Moving beyond Two-Tower models allows for more expressive ranking but introduces massive latency. This architecture demonstrates how to integrate heavy GPU inference into real-time stacks by optimizing feature fetching and moving business logic to the device.
Authors: Xiao Yang | Senior Staff Machine Learning Engineer; Ang Xu | Principal Machine Learning Engineer; Yao Cheng | Senior Machine Learning Engineer; Yuanlu Bai | Machine Learning Engineer II; Yuan Wang | Machine Learning Engineer II; Sihan Wang | Staff Software Engineer; Ken Xuan | Senior Software Engineer

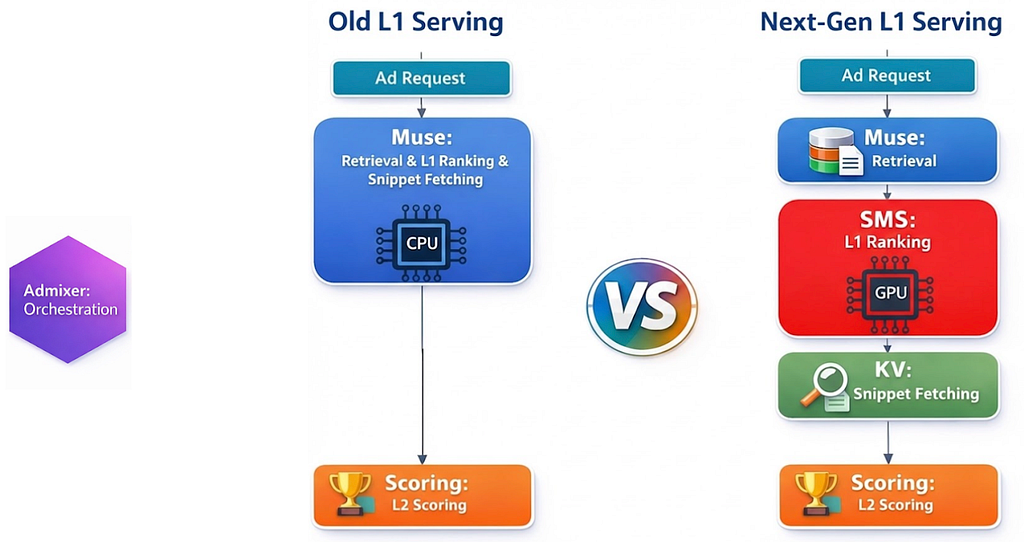
In the world of large-scale recommendation systems, the “Two-Tower” model architecture has long been the industry standard for the retrieval and lightweight ranking stage. Its appeal lies in its elegant efficiency: one neural network tower encodes the user, another encodes the item, and at serving time, the ranking score is reduced to a simple dot product between two vectors. This architectural simplicity allows systems to scan millions of candidates in mere milliseconds, making it the workhorse of modern discovery engines.
However, this efficiency comes at a significant cost in expressiveness. The Two-Tower architecture inherently struggles to leverage interaction features — complex, high-fidelity signals that capture exactly how a specific user interacts with a specific item (e.g., “User A has clicked on an ad from Advertiser B five times in the last hour”). Furthermore, it prevents the use of powerful architectural patterns like target attention or early feature crossing, where user and candidate features interact deep within the network layers rather than just at the very end. These “cross-features” and advanced architectures require the model to “see” both user and item data simultaneously, something the decoupled Two-Tower design structurally forbids.
To achieve a step-function improvement in recommendation quality, we knew we needed to break free from these constraints. We wanted to deploy general-purpose, more complex neural networks that could model these deep interactions directly.
But there was a catch. Our existing retrieval infrastructure was highly specialized for simple algorithmic operations like dot products or Approximate Nearest Neighbor (ANN) search. It was not designed to host heavy, general-purpose model inference. To support these new models, we needed to introduce a dedicated GPU-based model inference stage. To bridge this gap, we leveraged our in-house model inference engine — the same robust system powering our heavy ranking stages — which offers native support for PyTorch traced models and CUDAGraph models.
The challenge was daunting: How do we insert a new computationally heavy GPU model inference stage into our highly optimized serving stack while keeping end-to-end latency neutral?
This is the story of how we re-architected our serving stack to make the impossible possible.
Traditionally, our serving funnel followed a funnel-like path:
Simply plugging a GPU model inference box into this existing flow would have been disastrous for latency. The sheer volume of data involved — fetching features for tens of thousands of documents, serializing them, transferring them over the network to the GPU, running inference, and sending results back — was a bottleneck waiting to happen. The latency penalty would likely outweigh any gains from the better model.
We realized we couldn’t just optimize the model in isolation; we had to holistically restructure the entire serving funnel for the early stage.
One of the biggest contributors to latency at the lightweight ranking scale (handling O(10K) to O(100K) documents per request) is feature fetching. In many cases, the network I/O of fetching features from a remote service takes significantly longer than the actual model inference itself.
To solve this, we analyzed our traffic and adopted a Inventory Segmentation Strategy:
Note: This post focuses on the “Segment 1” optimization, which is currently launched in production. We will cover the technical details of our “Segment 2” solution in a future post — stay tuned!
In a typical recommendation setup, a model is a pure scoring engine: it inputs candidates and outputs raw scores per candidate. The serving system then handles all the messy business logic — utility calculations, diversity rules, deduplication, and top-k selection — on the CPU.
For us, this approach was inefficient. It meant streaming scores for O(100K) documents back from the GPU to the CPU, only to have the CPU discard 99% of them after applying filtering logic.
We flipped this pattern. We moved the business logic, such as utility calculation (combining pCTR, pCVR, bid, etc.), diversity rules, and top-k sorting, inside the PyTorch model itself.
Optimization 3: Taming the GPU Inference
Even with data optimizations, the raw inference speed was initially too slow. Our first benchmark showed a p90 latency of 4000ms — orders of magnitude too high for a real-time system. We needed to get it down.
Through a series of targeted low-level systems optimizations, we successfully slashed this latency to just 20ms:
Tools used: PyTorch Profiler, Nvidia Nsight Systems.
Our legacy retrieval engine was designed to return a list of “snippets” — a row-wise list of heavy Thrift structures containing metadata for every candidate. At the scale of O(100K) documents, the serialization, deserialization, and data transmission of this metadata became a massive bottleneck.
We split the retrieval execution into two phases:
In Phase 2, we further conducted a thorough audit of the metadata payload. We deprecated 1/3 of the unused fields and moved another 1/3 to be fetched later (in parallel with downstream heavy ranking stages). As a result, the metadata size was reduced by 3x. Compared to a naive implementation where we simply fetch full metadata for all candidates, these structural changes reduced the retrieval stage latency from 200ms down to 75ms.
Optimization 5: Graph Execution & Targeting
Finally, we looked at the very beginning of the request lifecycle. Previously, the system waited to fetch all features before starting any work.
We optimized the execution graph by splitting the feature expansion into two parallel paths:
This allows the targeting and filtering steps to start much earlier, overlapping with the heavier feature fetching process. This graph optimization shaved off another 10ms from the end-to-end latency.
After achieving acceptable latency with the optimizations above, we faced one final, unexpected hurdle during our online A/B experiments. While our goal was purely architectural — swapping the engine without changing the lightweight models or ranking logic — we observed non-neglect shifts in online metrics: some metrics unexpectedly improved while others regressed. After extensive analysis and debugging, we identified the root cause: the subtle but impactful difference between Local Ranking and Global Ranking.
Theoretically, Global Ranking is superior. However, in practice, this shift caused a “distribution shift” in the makeup of the candidate set. We observed that certain metrics improved while others regressed, likely because the composition of ads served to users had fundamentally changed — even though we hadn’t intentionally altered the business logic to seek such trade-offs. We spent significant effort analyzing and tuning this distribution shift to ensure our new system met or exceeded the business performance of the production behavior.
Transitioning from a CPU-based Two-Tower architecture to a GPU-based general-purpose inference stack was one of the most complex engineering challenges in years. It was a close collaboration between the modeling and infrastructure teams — a complete re-architecture of our serving foundation at the early stage in the funnel, driven by a deep model-infra co-design philosophy.
By blurring the lines between “model” and “infrastructure” — bundling features into weights, moving business logic into neural networks, and redesigning data protocols — we achieved our goal. We successfully introduced a sophisticated GPU inference stage while maintaining neutral end-to-end latency.
This work lays a solid foundation for the future of recommendation at Pinterest, unblocking a new generation of modeling innovations that go far beyond the limits of Two Towers. Early offline results already show step-function improvements in model performance, reducing loss by around 20%. We look forward to sharing more learnings as we continue to scale these models in production.
We’d like to thank Peng Yan, Qingyu Zhou, Longyu Zhao, Qingmengting Wang, Li-Chien Lee, Fan Zhou, Abe Engle, Peifeng Yin, Nathon Fong, Cole McKim, Zhuyan Chen, Madhukar Allu, Lili Yu, Tristan Lee, Lida Li, Shantam Shorewala, Renjun Zheng, Haichen Liu, Nuo Dou, Fei Tao, Li Tang, Zhicheng Jin for their critical contributions to this project, and thank Jitong Qi, Richard Huang, Leo Lu, Supeng Ge, Andy Mao, Jacob Gao, Chen Hu for their valuable discussions, and thank Jinfeng Zhuang, Zhaohong Han, Ling Leng, Tao Yang, Haoyang Li, Chengcheng Hu for their strong support and exceptional leadership.
Beyond Two Towers: Re-architecting the Serving Stack for Next-Gen Ads Lightweight Ranking Models… was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleScaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
This approach addresses the common bottleneck where network I/O limits ML serving efficiency. By implementing feature trimming based on model signatures, engineers can maximize GPU utilization and significantly reduce infrastructure costs by moving away from network-optimized instances.
This case study demonstrates how high-level ML workloads can cause low-level kernel starvation, leading to network driver resets. It is a critical lesson in debugging performance bottlenecks that span the entire stack from distributed frameworks to cloud infrastructure drivers.