Transitioning to GPU serving for lightweight ranking allows engineers to deploy sophisticated architectures like MMOE-DCN. This shift significantly improves prediction accuracy and business metrics without sacrificing the strict latency requirements of real-time recommendation systems.
Yuanlu Bai | Machine Learning Engineer II, L1 Conversion and Shopping Modeling; Yao Cheng | Sr. Machine Learning Engineer, L1 Conversion and Shopping Modeling; Xiao Yang | Sr. Staff Machine Learning Engineer, Ads Lightweight Ranking; Zhaohong Han | Manager II, Ads Lightweight Ranking; Jinfeng Zhuang | Sr. Manager, Ads Ranking

Lightweight ranking plays a crucial role as an intermediate stage in Pinterest’s ads recommendation system. Its main purpose is to efficiently narrow down the set of candidate ads before passing them to downstream, more complex ranking models. By doing so, it ensures that only the most relevant candidates move forward, improving both the efficiency and quality of our ads recommendations.
To balance model performance and serving latency, we adopted a classic two-tower paradigm. In this design, the Pin (ad) tower calculates Pin embeddings via offline batch updates, while the query (user) tower generates real-time embeddings. The prediction score is computed as the sigmoid of the dot product between the Pin and query embeddings. Previously, all two-tower models were served on CPUs. In 2025, we launched our first GPU-serving model for engagement prediction, which was an important milestone in the roadmap for next-generation infrastructure and model architecture.
The new model architecture combines Multi-gate Mixture-of-Experts (MMOE) with Deep & Cross Networks (DCN), alongside feature updates. GPU serving enables us to support this more complex model while maintaining latency comparable to the CPU baseline. With these improvements, we observed a 5–10% reduction in offline loss compared to our previous production model for click-through rate (CTR) prediction. Additionally, by serving standard and shopping ad scenarios separately and training each with only its relevant data, we achieved a further 5–10% reduction in loss. This segmentation also doubled our offline model iteration speed.
In this blog, we will provide a brief overview of the changes to our model architecture. For a more detailed explanation of MMOE and DCN, please refer to [1]. We will also share our insights on improving GPU training efficiency, as increased model complexity and large training datasets have led to longer training time. Finally, we will present both the offline and online evaluation results of this launch.
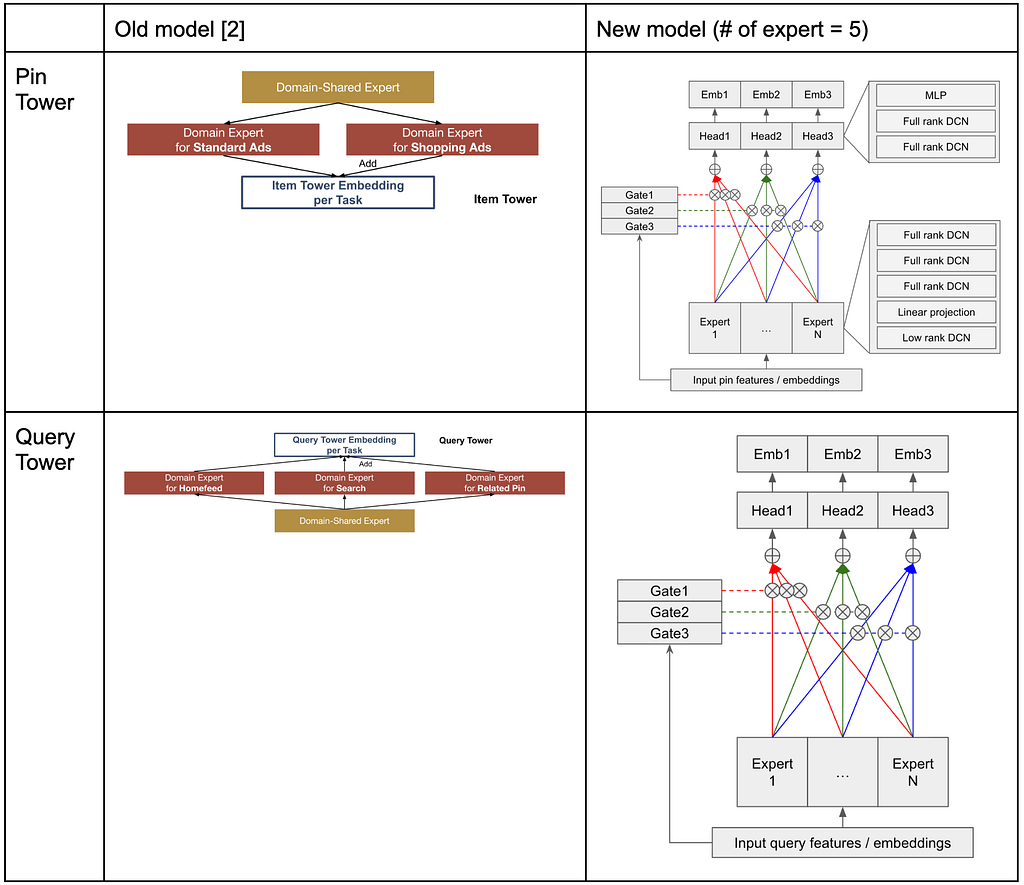
The new model introduces a significant architectural shift from the previous Multi-Task Multi-Domain (MTMD) [2] model to an MMOE-DCN design. We incorporated the MMOE structure with an MLP gating mechanism. In the prior MTMD model, domain-specific modules were used to learn information unique to each type of Pin or query. The new MMOE architecture effectively addresses multi-domain multi-task challenges, even without these domain-specific modules. Each expert in our model employs both full-rank and low-rank DCN layers. Below are diagrams illustrating the previous and current model architectures.
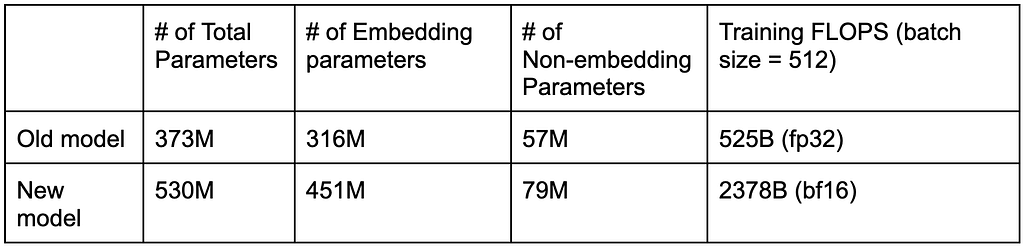
Here is a comparison of the model sizes.
As model size and training FLOPs increased, we conducted various optimizations and analyses to enhance training efficiency. As a summary, to accelerate training, we implemented the following improvements:
We use prediction scores from downstream ranking models as training labels and employ KL divergence [3] between the labels and model predictions as our loss function. The model is trained and evaluated on both auction winners (ads that were inserted and shown to users) and auction candidates (ads passed to the downstream ranking model). The table below demonstrates significant loss reduction across all slices, both offline and online [4].

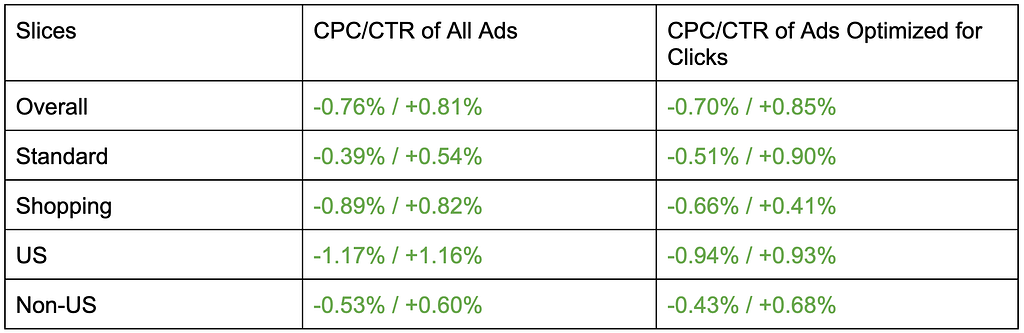
In online experiments, we typically use cost-per-click (CPC) and click-through rate (CTR) as key success metrics. CPC measures the average advertising cost for each user click, so lower values are preferable. As shown in the table below, we observed significant reductions in CPC and increases in CTR across all slices [4].
In this launch, we introduced a new GPU-serving two-tower model for Pinterest ads lightweight ranking, leveraging the MMOE-DCN architecture. By GPU infrastructure, model optimizations, and training efficiency improvements, we achieved substantial gains in both offline and online metrics. These enhancements resulted in significant reductions in loss and cost-per-click, as well as increases in click-through rate. This work marks an important step forward in scaling our recommender systems with more complex, efficient, and effective models.
This project was a collaborative effort involving multiple teams at Pinterest:
[1] Li, Jiacheng, et al. “Multi-gate-Mixture-of-Experts (MMoE) model architecture and knowledge distillation in Ads Engagement modeling development.” Pinterest Engineering Blog.
[2] Yang, Xiao, et al. “MTMD: A Multi-Task Multi-Domain Framework for Unified Ad Lightweight Ranking at Pinterest.” AdKDD 2025.
[3] Kullback, Solomon, and Richard A. Leibler. “On information and sufficiency.” The annals of mathematical statistics 22.1 (1951): 79–86.
[4] Pinterest Internal Data, US, 2025.
GPU-Serving Two-Tower Models for Lightweight Ads Engagement Prediction was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleScaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
This approach addresses the common bottleneck where network I/O limits ML serving efficiency. By implementing feature trimming based on model signatures, engineers can maximize GPU utilization and significantly reduce infrastructure costs by moving away from network-optimized instances.
This case study demonstrates how high-level ML workloads can cause low-level kernel starvation, leading to network driver resets. It is a critical lesson in debugging performance bottlenecks that span the entire stack from distributed frameworks to cloud infrastructure drivers.