Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
Authors (listed alphabetically)
Ads Feature Engineering Infra team: Ajay Venkatakrishnan, Le Zhang
Core ML Infra team: Eric Shang, Pihui Wei
ML Data team: Connor Votroubek, Yi He
User Understanding team: Camilo Munoz, Simin Li
If you work on ranking, retrieval, or recommendation systems, you’ve probably asked for some version of the same thing: “Give me the last N meaningful actions this user took, with the right enrichments, in a format that’s easy to train and serve ML models.”
On paper, that sounds simple. In practice, “user sequences” often become one of the most expensive and fragile parts of the ML data stack.
This article walks through how we redesigned our user‑sequence platform to make these sequences cheaper to run, faster to extend, and easier to debug, while still supporting demanding production use cases.

In this context, a user sequence is an ordered list of recent, relevant events for a user, along with the enrichments (signals) attached to each event. Here, enrichments mean all the extra signals we attach to raw events, so they’re useful for models: embeddings (for example, Pin or query representations), contextual features (such as surface, device, or country), and derived attributes or counters that describe how the user interacted with a piece of content over time.
A concrete example helps. Imagine a sequence made up of the last 500 engagements a user had with Pinterest Pins. Each event in that sequence might carry a timestamp, an action type, the surface where the action occurred, and a handful of embedding features or categorical attributes.
As a data primitive, user sequences are powerful. They capture temporal behavior instead of just aggregates like “how many clicks” over a period. They enable sequence‑aware models such as Transformers, sequence encoders, or attention‑over‑history architectures. And because they preserve fairly raw behavior, they can be reused across ranking, retrieval, exploration, anomaly detection, and other workloads.
The catch is that a high‑quality sequence is not just “the N latest events from a log table.” It is the result of a multi‑step process:
Doing this once is easy. Doing it in a way that supports many teams, many event types, and many models over multiple years is where things get interesting.
User sequences sit underneath almost every user-facing surface: Home feed(HF), Related Pins (RP), Search Results (SR), and many others. They power both organic products and ads across these surfaces in Pinterest, so any regression in sequence quality shows up quickly in user experience and revenue.
From an infrastructure point of view, they show up in three main places.
Across these use cases, sequence quality turns out to be multi‑dimensional. Freshness measures how quickly new events and enrichments show up in the sequence. Completeness asks whether late‑arriving events, corrections, or backfills are eventually reflected. Consistent enrichment is about ensuring that the same enrichments are available across streaming and batch, and that training and serving see aligned data. Stable schemas matter as well: downstream consumers need schemas to be versioned and predictable, not silently changed.
One more constraint is that this is a multi‑tenant platform. It has to support many teams and models, each with different needs and lifecycles. That makes correctness, observability, and operability just as important as raw throughput or latency.
When we stepped back to redesign the platform, we framed the work with a small set of explicit goals and non‑goals.
The key organizing principle for the redesign was simple:
Define a signal or event type once, then instantiate it consistently across multiple runtimes.
A signal definition captures which raw events to use, which enrichments to apply, and how to assemble enriched events into a sequence. That same definition is then consumed by three different kinds of workloads:
This “one definition, many runtimes” approach avoids the classic split‑brain failure mode where training pipelines build sequences one way from batch tables while serving systems assemble sequences a different way from online stores. Over time, those two views naturally drift apart in subtle ways.
Instead, we rely on a single configuration surface plus a shared execution engine to keep indexing, training and serving aligned.
System Architecture Diagram
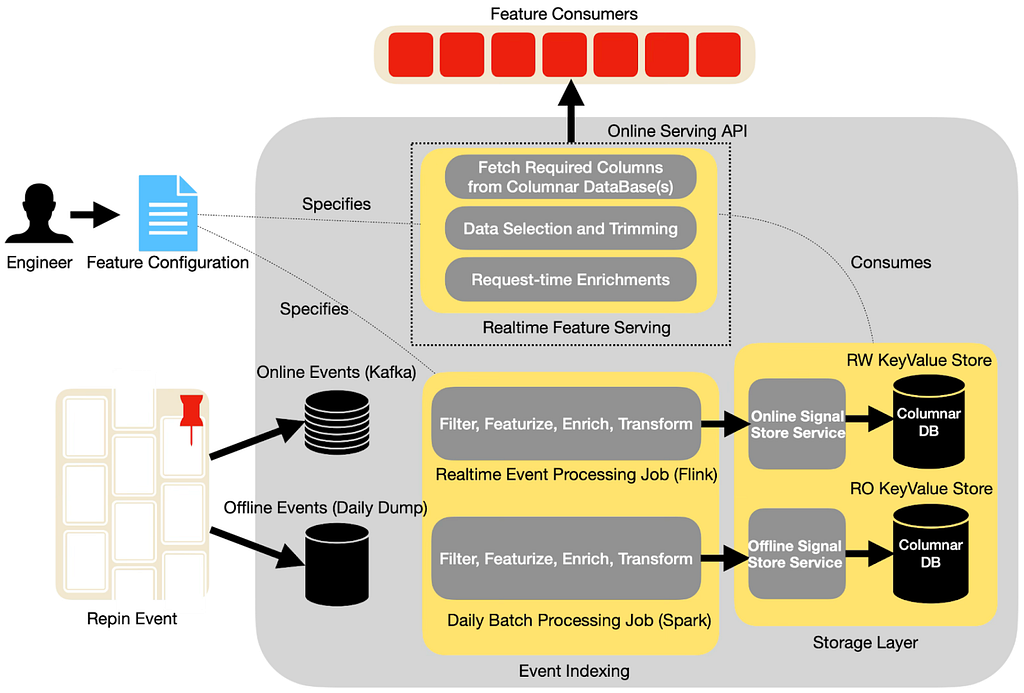
At a high level, the platform is composed of six major pieces that work together.
From the perspective of a model or client team, this all collapses into a simple contract:
Request sequence X for user U, and you’ll get a well‑defined schema of enriched events, with a documented freshness and completeness profile.
We moved sequence and enrichment definitions into configuration‑as‑code, expressed in a regular programming language (Python) with a well‑defined schema.
Our configurations describe which sequence features exist, how they’re named, and basic metadata such as owners, retention, and lifecycle stage. Event‑type configuration describes, for each event type, which enrichments apply, what filtering logic to use, and what data sources to read from. Enrichment configuration explains how to fetch or derive additional signals (for example, embeddings) and how to map them into the event schema.
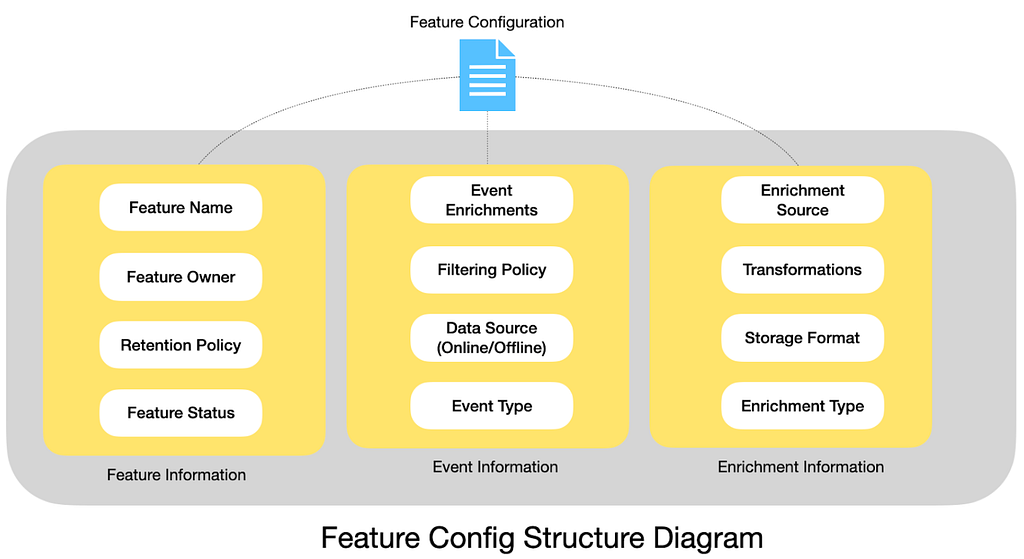
These configurations are validated, compiled into a portable JSON format, stored in managed internal object storage, and then consumed by the shared execution engine across streaming, batch and serving jobs.
This approach made onboarding dramatically faster. New event types or enrichments can now be added primarily through configuration, plus small, isolated pieces of code where absolutely necessary, instead of via entirely new pipelines. That significantly reduces the concept‑to‑production time for new signals.
Treating configuration as code also improved reviewability and safety. Diffs are human‑readable, code owners can review changes, rollbacks are straightforward, and version history lives in standard version control systems.
A clearer separation of concerns followed naturally. ML and product teams focus on what they want (events, features, and filters) while platform teams focus on how to execute that configuration reliably and efficiently.
We introduced a shared execution engine responsible for reading configuration, connecting to data sources (kafka, logs, tables, feature stores), running filtering and featurization, calling enrichment services or joining against offline tables, and finally writing enriched results to storage.
Within this engine, an executor is a plugin that converts a raw event into one or more enriched records. In plain terms, the executor is the “business logic module” for a particular event type or grouping, while the execution engine handles everything around it.
The shared engine allowed us to reuse the same core enrichment logic in both streaming jobs that handle near‑real‑time events and batch jobs that process historical data. That minimized code duplication and reduced drift between batch and real‑time behavior.
To keep the system maintainable, we drew a clear line between framework and plugin code.
Framework responsibilities include wiring data sources and sinks, handling concurrency, retries, and backpressure, and parsing and validating configuration. Executors own the business‑specific filtering and featurization logic and the mapping from raw events to normalized user‑event representations.
Sequence consumers want two things that naturally pull in opposite directions. On one hand, they need freshness: “I want this morning’s actions reflected in ranking now.” On the other hand, they care about completeness and correctness: “If late events show up tomorrow, I still want my sequences and training data to be right.”
Real‑world data is messy. Events arrive late. Enrichment sources are recomputed or corrected. Backfills introduce new historical coverage months after the fact.
To balance these requirements, we adopted a lambda‑style architecture for user sequences.
A streaming path processes events as they arrive and maintains a near‑real‑time view of user sequences for online inference. A batch path periodically recomputes enriched events and sequences from raw historical data, producing long sequences and reusable datasets for backfills and offline analysis.
The two paths cooperate instead of competing. The streaming path maintains the “now” view of the world, while the batch path focuses on “fixing history” and ensuring that training and long‑term analytics see consistent, corrected data.
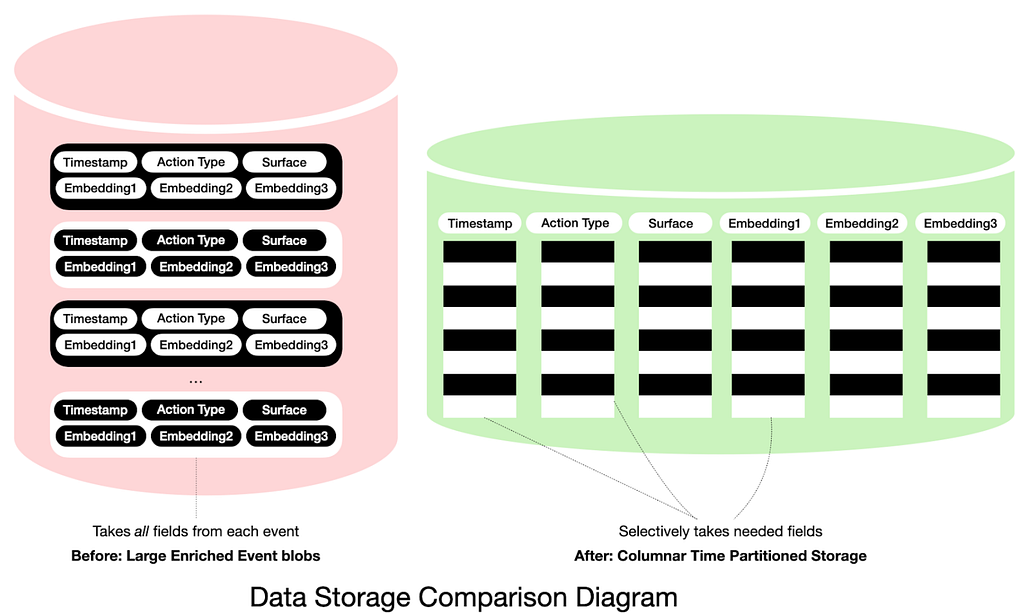
Before this redesign, we stored sequences as large, consolidated “enriched event” blobs. Every online call or offline scan had to pull the whole payload — even if a model only needed a small subset of features — so request fan‑out turned directly into heavy payload size and I/O on our storage systems.
We moved sequence storage to a columnar, time‑partitioned layout that behaves like a set of tables. Each enrichment or feature lives in its own column, and reads can select only the columns they need for a given model or analysis. Data is partitioned by time bucket so that writes and scans stay constrained to relevant partitions as history grows. Engineers can query these datasets with familiar table abstractions, which makes it easy to compare runs, versions, or backfill strategies by inspecting partitions.
This design improved both efficiency and operability. Columnar storage improves compression and reduces network bandwidth by avoiding wide “enriched event” blobs when only a few features are needed. Time partitioning keeps I/O bounded even as the system accumulates long histories.
Operationally, having clear table semantics makes it much easier to inspect anomalous days or event types, validate new enrichments, and compare old and new pipelines side by side.
Redesigning a platform is one thing; migrating existing production workloads is another. We treated migration as a first‑class project.
We followed an event type by event type approach.
For a given event type, we first ran the new pipeline in parallel with the existing one and generated “shadow” sequences. We then compared those shadow outputs to the legacy sequences over a defined period.
Since we are regenerating the data using completely new jobs, we had to accept that the data won’t have a 100% match due to the nature of our online systems. As a result, we had to have thorough validations to prove that our new system was producing approximately the same sequences when compared to the legacy system.
We decided on a strategy of using two tiers of comparisons, an event-level comparison, which compared field-by-field of events we matched between our old and new indexing jobs, as well as a sequence-level comparison, comparing the shadow sequence output with the legacy sequence output. Alongside performing A/B experiments using our new data, these validations gave us the confidence that we could safely swap our pipelines with no impact.
Once we were confident in the behavior, we performed a controlled cutover by shifting consumers to read from the new architecture. We then iterated the same process across additional event types, steadily deprecating the legacy path.
To stay within company policies, we only describe qualitative outcomes here.
On cost, we saw significant infrastructure cost reductions once large event types were fully migrated, primarily because of more efficient storage formats, fewer replicas where appropriate, and lower network transfer per request.
On productivity, the time to onboard new enrichments and event types dropped substantially. Most changes moved from bespoke pipeline work to configuration updates and small, composable executors.
On quality, our major recommendation surfaces saw improved engagement metrics after switching to sequences produced by the new platform, while still staying within quality and safety expectations.
Throughout migration and into steady state, we invested heavily in observability and operational hygiene.
We set up dashboards tracking sequence freshness and lag, event and enrichment coverage, schema drift and configuration rollout status, and serving latency and error rates..
These foundations turned out to be crucial. A platform that many teams rely on will eventually have bad days; the difference between a minor blip and a major incident often comes down to whether you can quickly see what went wrong and where.
There is still plenty to improve, and many of the directions generalize beyond any single company.
We want richer self‑serve tooling so that adding new signals feels more like filling out a template than editing infrastructure code. That includes wizards for new signals, static analysis for configurations, and automated backfill orchestration for common patterns.
We are also interested in stronger correctness guarantees. Anomaly detection over both indexing and serving paths would further harden the system.
Finally, we plan to broaden coverage and add richer signals. That includes extending sequence coverage to more event types and surfaces and adding higher‑level behavioral abstractions on top of raw event sequences, such as session‑level or object‑level views. The challenge is to do that while preserving the core “events → enriched signals → sequences” contract that keeps the platform coherent.
A big thank you to everyone who contributed through discussions, design reviews, and recurring syncs that helped shape and unblock this work. In no particular order:
Alekhya Pyla, Chuxi Wang, Han Wang, Jia Zhan, Kangnan Li, Kyle Soares, Laksh Bhasin (He Him), Nilesh Gohel, Se Won Jang, Xue Xia, Yang Tang, Yi He, Anton Arboleda, Yi Pan
And thank you to Archer Liu, Haoyang Li, Hongbo Deng, Qingxian Lai, Shun-ping Chiu, and Yingjian Ding for their great management support.
Making User-Sequence Data More Cost-Efficient, Faster, and Easier to Use was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleScaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
It demonstrates how to scale multimodal LLMs for production by combining expensive VLM extraction with efficient dual-encoder retrieval. This architecture allows platforms to organize billions of items into searchable collections while maintaining high precision and low operational costs.
This article demonstrates how to significantly accelerate ML development and deployment by leveraging Ray for end-to-end data pipelines. Engineers can learn to build more efficient, scalable, and faster ML iteration systems, reducing costs and time-to-market for new features.
This article details how Pinterest scaled its recommendation system to leverage vast lifelong user data, significantly improving personalization and user engagement through innovative ML models and efficient serving infrastructure.