This approach addresses the common bottleneck where network I/O limits ML serving efficiency. By implementing feature trimming based on model signatures, engineers can maximize GPU utilization and significantly reduce infrastructure costs by moving away from network-optimized instances.
Guangtong Bai | Staff Software Engineer, Product ML Infrastructure*; Shantam Shorewala | Software Engineer II, Product ML Infrastructure*; Chi Zhang | Staff Software Engineer, AI Platform*; Neha Upadhyay | Software Engineer II, AI Platform*; Haoyang Li | Director, Product ML Infrastructure
*These authors contributed equally to this article.
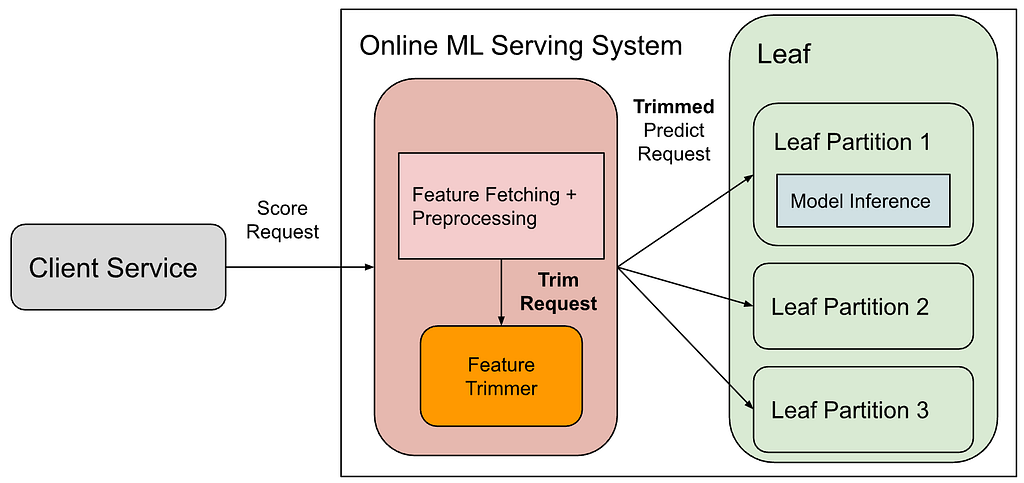
At Pinterest, our online ML serving systems employ a root-leaf architecture. On a high level, the architecture looks as follows:

In the diagram, “Client Service” is responsible for recommending organic or promoted Pins to users. In order to know if a given Pin is relevant to a particular user request, client service sends a score request to the online ML serving system to have the Pin scored by a bunch of ML models, each of which scores an aspect of “relevancy”.
The online ML serving system is composed of 2 parts:
What is flowing between the services are ML features. In this blog, we share how passing too many features from root to leaf created a network bottleneck and how we resolved it with Feature Trimmer.
The root-leaf architecture provides us with significant benefits, namely:
However, this setup introduced a new challenge — the network bandwidth between root and leaf became a performance bottleneck on the online serving path; we had to scale the system based on network usage rather than compute. We observed this pressure in the Ads server on both the root and leaf partitions:
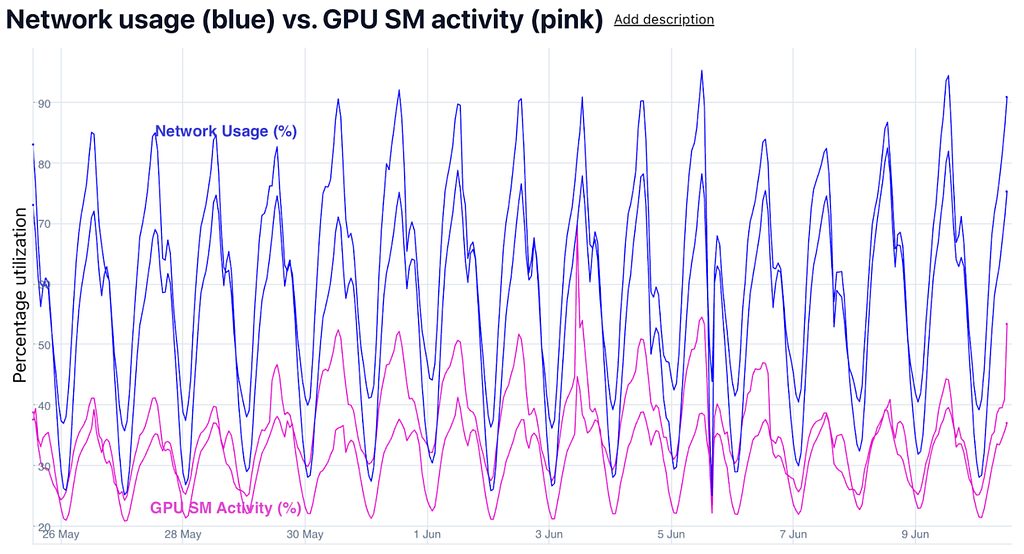
That led to a straightforward idea: reduce the root-leaf network bandwidth usage to unlock immediate fleet downscaling and infrastructure savings. If we could cut bandwidth enough, we could also move the root from network-optimized m6in instances to standard m6i instances (about 20% cheaper), further reducing cost.
The most direct way to reduce the root-leaf network bandwidth usage is to compress the requests between them.
This compression strategy is well-suited for the requests sent from the root to the leaf, which primarily carry ML features for multiple candidate Pins for a given user request. These requests are compressible for several reasons:
After a few quick tests, we enabled lz4 compression in fbthrift (the RPC framework used by root and leaf) for root-leaf traffic. That reduced 20% root-leaf network usage, at the cost of 5% CPU usage increase and 5ms (~10%) p90 latency increase.
Compression was a solid early win, but it didn’t change the underlying problem: we were still shipping too much unused data. The bigger lever was to stop sending unused features altogether, which led to our “Send What You Use” approach.
In our root–leaf architecture, the root is shared across many leaf partitions and must fetch ML features for all models. To minimize feature store QPS, the root fetches the union of features needed across models (per candidate Pin), stores them in an efficient in-memory cache, and then fans out the full feature set to each leaf model. Each model converts and uses only the features it needs; the rest are effectively discarded before inference.
This approach was acceptable in our prior architecture, where the same GPU host handled both feature fetching/preprocessing and local model inference. In that context, the unnecessary features only increased main memory usage, which was not a bottleneck on GPU machines. However, within the new root-leaf architecture, transmitting these unneeded features across the network introduces a significant efficiency problem.
If we could send only the required features and trim everything else, similar to C++’s “include what you use” header management tool removing unnecessary #include’s, we could potentially cut root-leaf network usage by ~50%. Like compression, this trades network savings for some additional CPU work and potential latency overhead.
To make this work, the root must know the exact feature list required by each leaf model. Since models refresh continuously, we also need to keep the feature allowlist on root in sync with the feature expectations of the latest model version on the leaf.
The source of truth for which features are needed by a model is its model signature. Model signature defines the inputs and outputs of a model, similar to a function signature. As a version of a model finishes training, its model signature is exported as an extra file alongside the TorchScript artifact in the .pt archive file. Below is what a model signature looks like:
❯ unzip -p model.pt archive/extra/module_info.json | jq
{
"input_names": [
"feature_id_1",
"feature_id_2",
"feature_id_3",
...
],
"output_names": [
"output_score_1",
"output_score_2"
]
}
When the leaf loads a specific model version from the .pt archive, it not only deserializes the weights from the TorchScript artifact, but also builds a feature converter from the model signature. The converter transforms input features from internal company format into native PyTorch tensors before passing them to the model. Because it knows the model’s inputs, it converts only the required features and discards the rest.
A crucial convention is that a model’s signature remains unchanged across different versions. If a signature modification is necessary — for instance, to introduce a new input feature — a new model is forked from the original. This practice is essential because it underpins the fallback mechanism for the versioned lookup feature of the Feature Trimmer, a topic discussed in detail later in the “Versioned Lookups and Fallback” section.
Feature Trimmer only works if the root knows exactly the features that the leaf model expects. That sounds simple until you factor in reality: models are refreshed frequently (hourly to daily), multiple models are shipped together as a “bundle”, and rollouts happen gradually (canary → prod, rolling deploys, occasional rollbacks).
This section explains how we keep the root up to date with what’s actually deployed on the leaf without adding heavy runtime dependencies or introducing brittle, manually managed configs.
At a high level, our approach is:
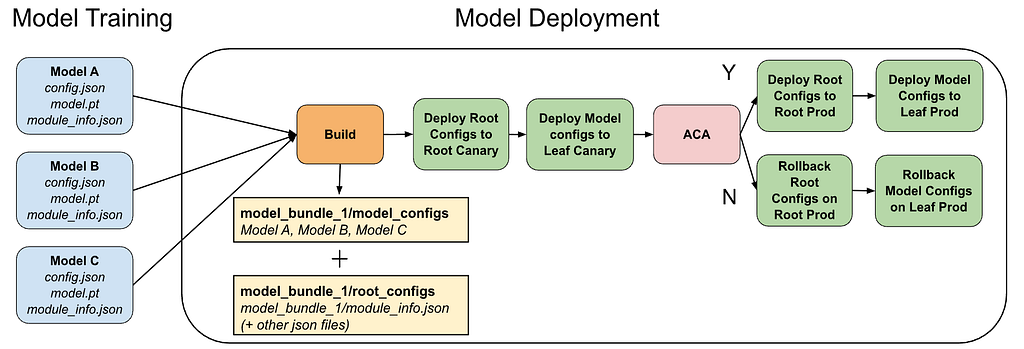
Publish module_info.json as a standalone artifact
To make the model signature easy to ship and consume, we export module_info.json as a standalone file as part of the model training workflow, next to other model files (for example, alongside the model artifact and config files). This is important for synchronization as it ensures signatures are available before deployment, and available in a form that can be aggregated and deployed without any heavy runtime dependencies.
Generate a bundle-level module_info mapping during bundle build
In production, roots don’t serve a single model, they typically serve bundles containing multiple models (and sometimes multiple versions during a rollout window). So instead of deploying N per-model signatures independently, the bundle pipeline generates one bundle-level artifact that looks like:
{
"model_A": [
{
"version": "1",
"input_names": ["feature_id_1", "feature_id_2", "..."],
"output_names": ["score_1", "..."]
},
{
"version": "2",
"input_names": ["feature_id_1", "feature_id_2", "..."],
"output_names": ["score_1", "..."]
}
],
"model_B": [
{
"version": "7",
"input_names": ["feature_id_9", "..."],
"output_names": ["score_x", "..."]
}
]
}During the build step, the model deploy pipeline iterates over the model versions that will be shipped in the bundle.
Finally, the bundle-level module_info file is packaged and uploaded together with other root configuration files, so the root receives one coherent “ configs” package.
Deploy root configs through the same staged delivery flow
Once the bundle build produces the root-config package, deployment follows the standard staged delivery pattern:
This is important because it integrates the feature trimmer into the existing model deployment system and ensures that the “root’s trimming view of the world” is updated using the same guardrails and rollback mechanics as other model changes.
We deploy root configs before rolling out new leaf model versions because the feature trimmer keys feature allowlists by model name + version. If a versioned request arrives without a matching allowlist, we skip trimming to avoid stale configs, which can cause a temporary rollout gap. To prevent this, we ship a backwards-compatible root artifact containing allowlists for both the current and pending versions. Discussed in more detail in a later section “Versioned Lookups and Fallback.”
On successful completion, the root hosts receive the bundle-level signature mapping at a known location on disk, and the trimmer can begin using it for per-model feature allowlisting.
Once the root hosts have an idea of which features each model requires, we only keep the needed features in the fan-out request to leaf partitions. This allowlist approach, compared to a blocklist where we keep features not in the list, does not carry the burden of tracking all the features that might be in development or deprecated. Given the evolving nature of ML models and volume of experiments at Pinterest, the blocklist is significantly larger for any given model and it is probable that it will grow faster than the allowlist in the future.
As mentioned earlier, a model bundle can contain multiple ML models. Additionally, the model bundles do not map 1:1 to the root cluster — each root cluster can receive traffic for multiple bundles. The bundles, each with their own module_info artifact, are deployed independently and often at different cadence. Further, we need to support independent rollbacks for even a single model bundle.
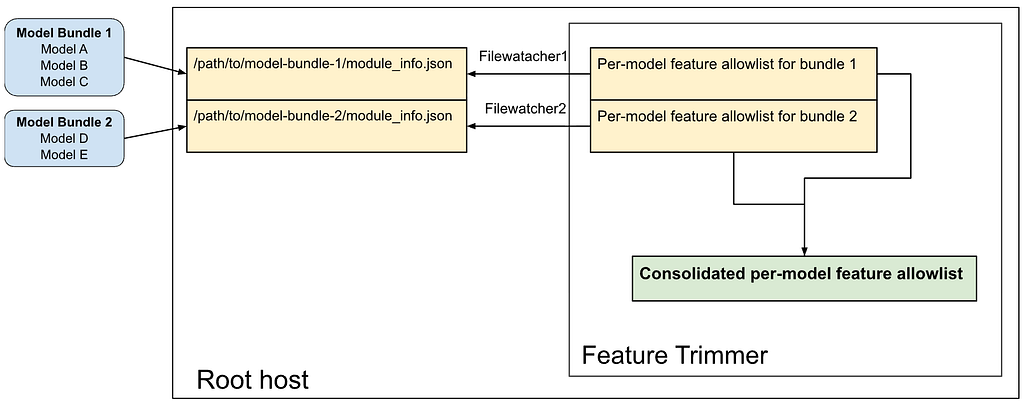
A feature trimmer module is initialized on each root host when it comes online. This module maintains a consolidated, in-memory mapping from models to their versioned feature allowlist. Each trim request is efficiently serviced by looking up the model name and version within this consolidated map. The consolidated map uses the model name and version as nested keys for fast read access as follows.
{
"model_A": {
"version_N": ["feature_id_1", "feature_id_2", "..."],
"version_M": ["feature_id_1", "feature_id_2", "..."],
},
"model_B": {
"version_N": ["feature_id_3", "feature_id_4", "..."],
"version_K": ["feature_id_4", "feature_id_5", "..."],
},
}This per-model feature allowlist map needs to be continuously refreshed as the model bundle is updated. Here is how it is managed:
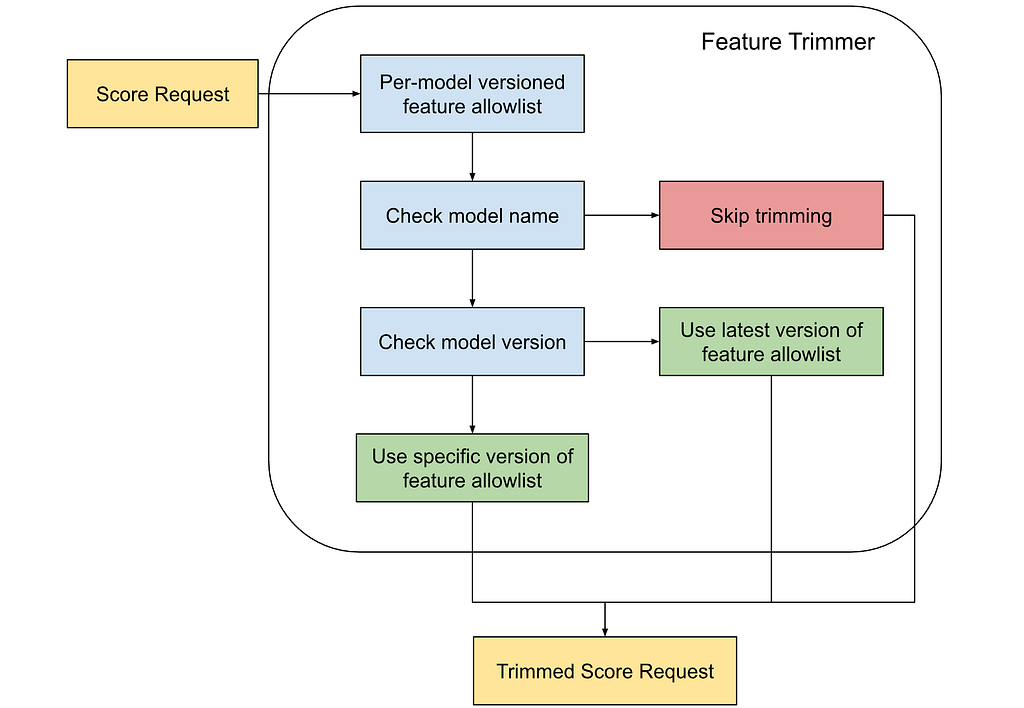
Each scoring request sent to the root cluster must include the model name and optionally, the model version. If the version is omitted, it defaults to the latest version. The feature trimmer parses these fields to determine the version-specific feature allowlist for the requested model.
The adoption of the feature trimmer is expected to reduce network bandwidth consumption for root-leaf connections. This places the trimmer on the critical failure path: failure to trim score requests can cause a significant spike in network bandwidth, potentially leading to cascading failures. Therefore, robust handling of artifact (module_info.json) corruption or deployment failures is essential.
We have implemented the following safeguards:
The fundamental assumption that the model signature is consistent across different model versions allows us to implement these precautions, ensuring the Feature Trimmer remains reliably operational even in the event of intermittent deployment failures.
Ads root-leaf server setup was the biggest beneficiary of this launch. Figures 7 and 8 compare the network performance of the Ads root and leaf clusters post the launch of the feature trimmer module.
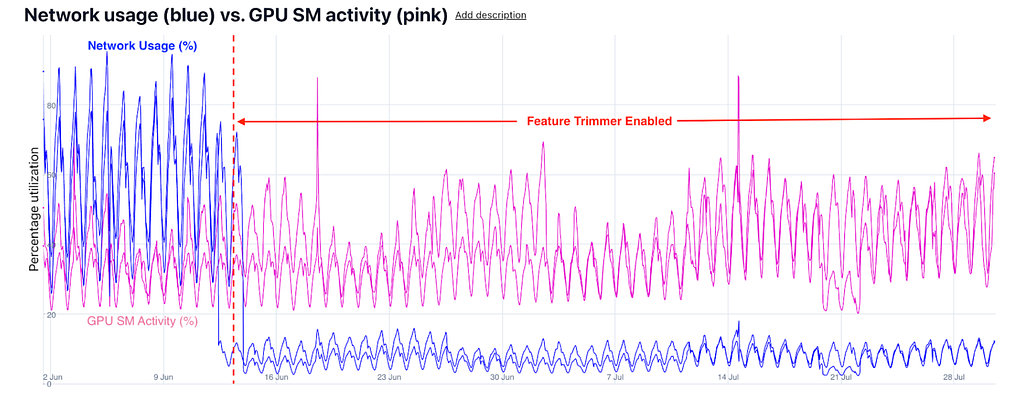
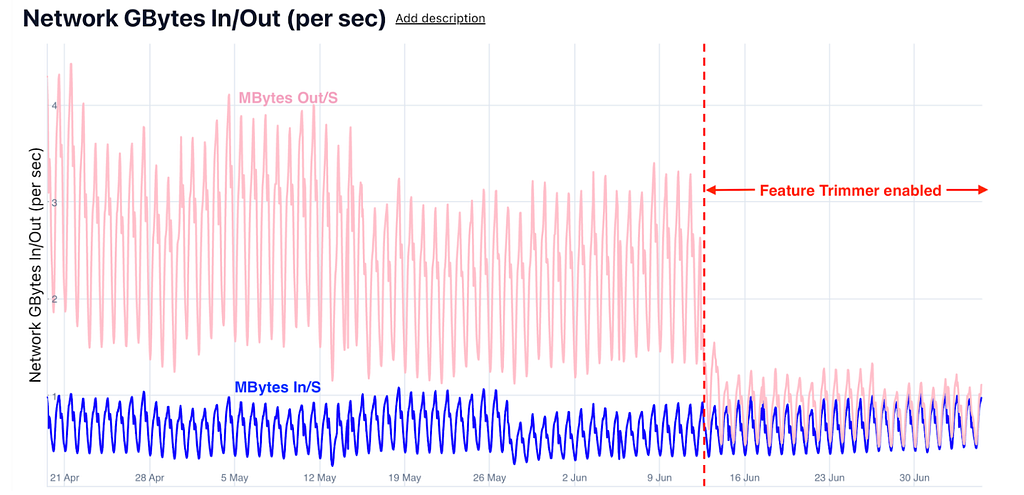
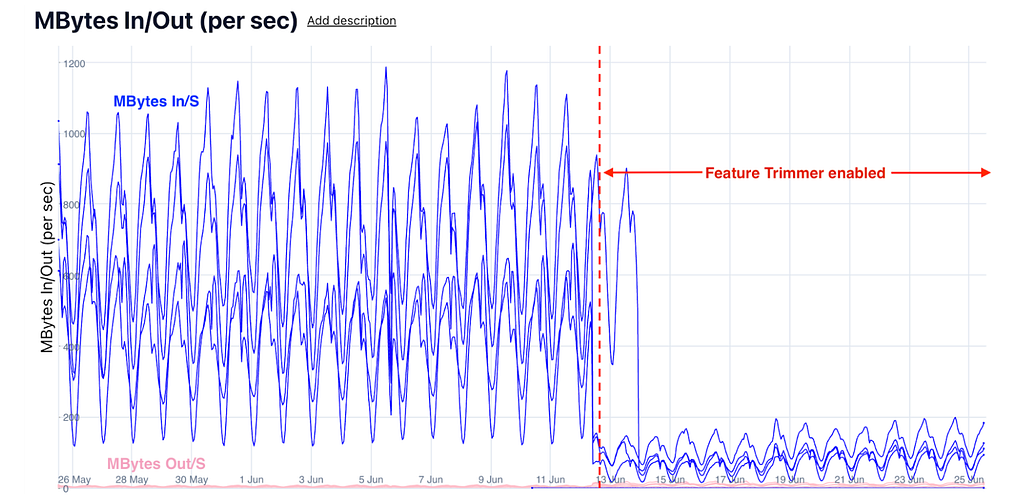
Later, we also applied the feature trimmer to other use cases such as HomeFeed and Related Pins and saw latency and network reductions similar to Ads, amplifying the overall impact of this initiative. Figures 10 and 11 show the network savings in Homefeed Root and Leaf.
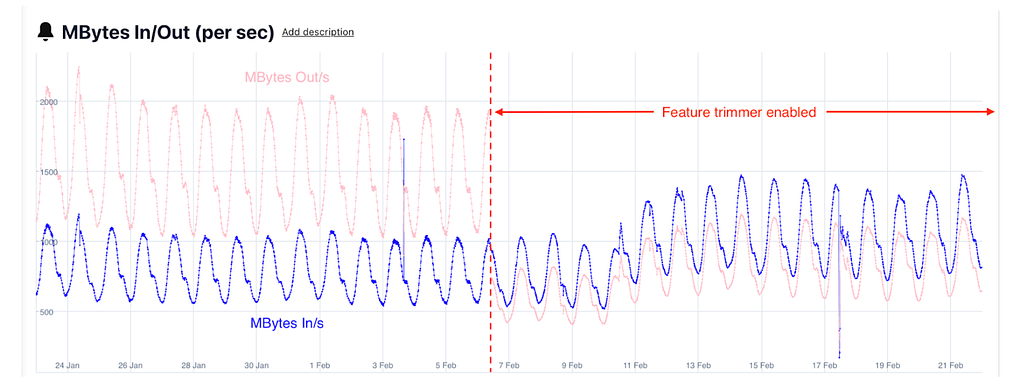
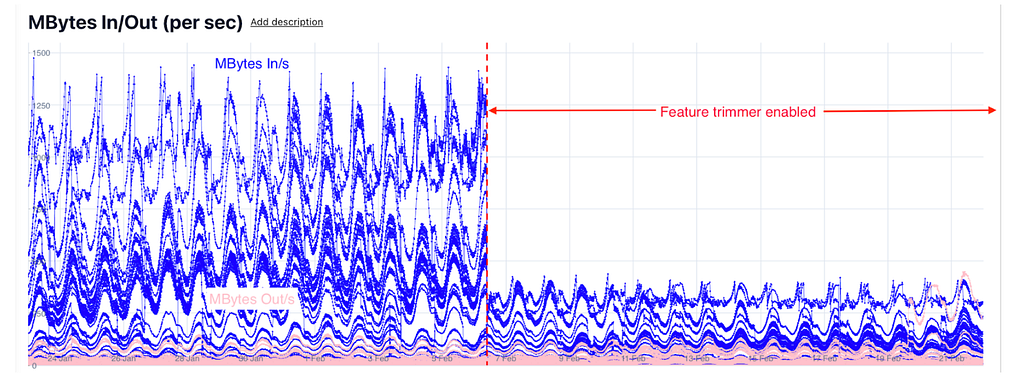
As a result, we reduced the Homefeed root cluster fleet size by 33% and are still working on rightsizing the Homefeed leaf clusters, unlocking significant infrastructure savings.
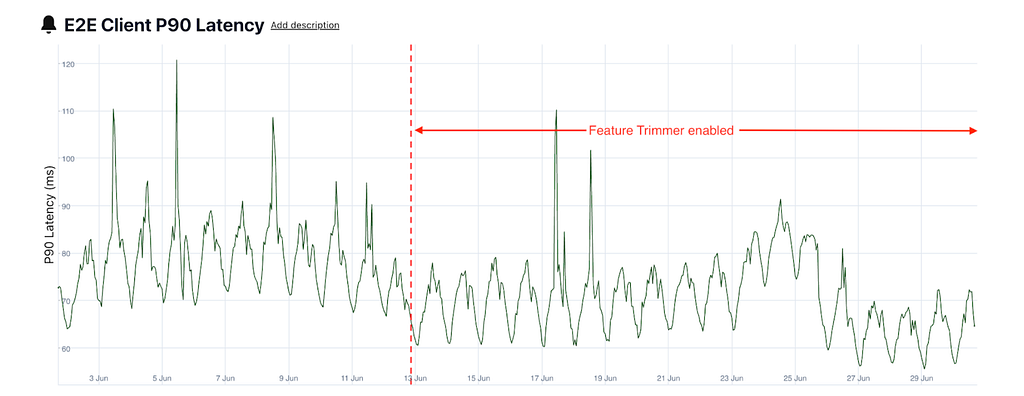
While the payload size reduction directly contributed to the network performance improvement, we also saw a reduction in CPU utilization on the root cluster and a reduction in both server-side and client-side root latency. We believe this is largely because a smaller payload leads to less CPU cycles spent on SerDe (serialization/deserialization). This additional latency headroom allowed Ads to save additional cost by trading some latency for cost and the remainder was used to unblock future experiments (see latency increases in late June).
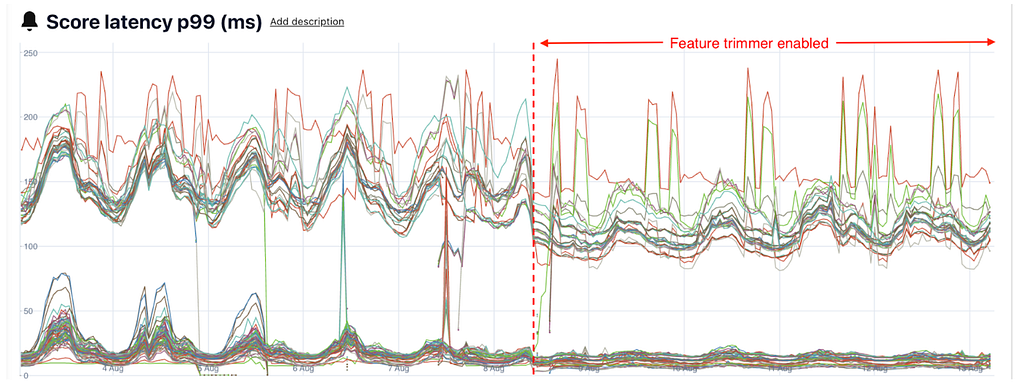
For our Related Pins surface, the model score latency p99 (ms) before the feature trimmer for most models sits around ~130–180 ms with frequent spikes above 200 ms. After the feature trimmer is enabled, the p99 baseline shifts down to roughly ~95–125 ms for most models, a notable ~25–30% drop in latency.
Based on the efficiencies realized in terms of network performance and client latency, we were able to resize the ML servers at Pinterest to realize significant cost savings:
Overall, this project saved over $4M in annual infrastructure costs for Pinterest while creating headroom to test bigger models and features without latency or network performance concerns. It effectively shifted the bottleneck from network to CPU cycles on the root cluster. This also allows the team to switch focus to optimizing the payload between the client and the root to further finetune the resource utilization end-to-end.
Feature Trimmer successfully addressed a critical network bottleneck in Pinterest’s root-leaf ML serving architecture, moving beyond simple payload compression to implement a “Send What You Use” philosophy. By establishing the model signature as the source of truth for required features and deploying a robust, version-aware feature allowlisting system in sync with model rollouts, we significantly reduced the data volume passed between the root and leaf clusters. This optimization resulted in substantial network bandwidth reduction, improved client-side latency, and ultimately delivered significant cost savings.
In Part II of this blog series, we will shift focus to how request feature compression further optimizes the network connection between the client and the root. Keep an eye out for the next installment to discover how we achieve even greater efficiencies in our ML serving infrastructure.
This project would not have been possible without former team members Yiran Zhao and Queena Zhang’s early exploration and prototyping. We extend our sincere gratitude to the following individuals for their invaluable support in deploying Feature Trimmer into production: Miao Wang, Randy Carlson, Runze Su, Qifei Shen, and Tao Mo. We would also like to thank Nazanin Farahpour, Howard Nguyen, Bo Liu, Sihan Wang, Renjun Zheng and Zheng Liu for their helpful review of this blog post.
Optimizing ML Workload Network Efficiency (Part I): Feature Trimmer was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleThis article demonstrates how Pinterest optimizes ad retrieval by strategically using offline ANN to reduce infrastructure costs and improve efficiency for static contexts, complementing real-time online ANN. This is crucial for scaling ad platforms.
Scaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
Redundant processing of duplicate URLs wastes massive computational resources. This automated, data-driven approach to normalization reduces infrastructure costs and improves data quality by identifying content identity before expensive rendering or ingestion steps occur.