This article demonstrates how to significantly accelerate ML development and deployment by leveraging Ray for end-to-end data pipelines. Engineers can learn to build more efficient, scalable, and faster ML iteration systems, reducing costs and time-to-market for new features.
Andrew Yu Staff Software Engineer / Jiahuan Liu Staff Software Engineer / Qingxian Lai Staff Software Engineer / Kritarth Anand Staff Software Engineer
At Pinterest, ML engineers continuously strive to optimize feature development, sampling strategies, and label experimentation. However, the traditional ML infrastructure was constrained by slow data pipelines, costly feature iterations, and inefficient compute usage.
While Ray has already transformed our training/batch inference workflows, we saw an opportunity to extend its capabilities to the entire ML infrastructure stack. This blog details how we expanded Ray’s role beyond training to feature development, sampling, and label modeling — ultimately making ML iteration at Pinterest faster, more efficient, and more scalable.
“Provide reliable and efficient data platforms and services at planet-scale to accelerate innovation and sustain our business” — ML foundation mission statement
Before integrating Ray across our broader ML stack, we faced several key challenges:
To solve these challenges, we introduced a Ray-native ML infrastructure stack, focusing on four major improvements.
To extend Ray’s role across our ML infrastructure, we introduced:
Goal: Develop functionalities to enable feature development, sampling, and label transformations natively in Ray, eliminating the need for Spark backfills.
How:
Design:
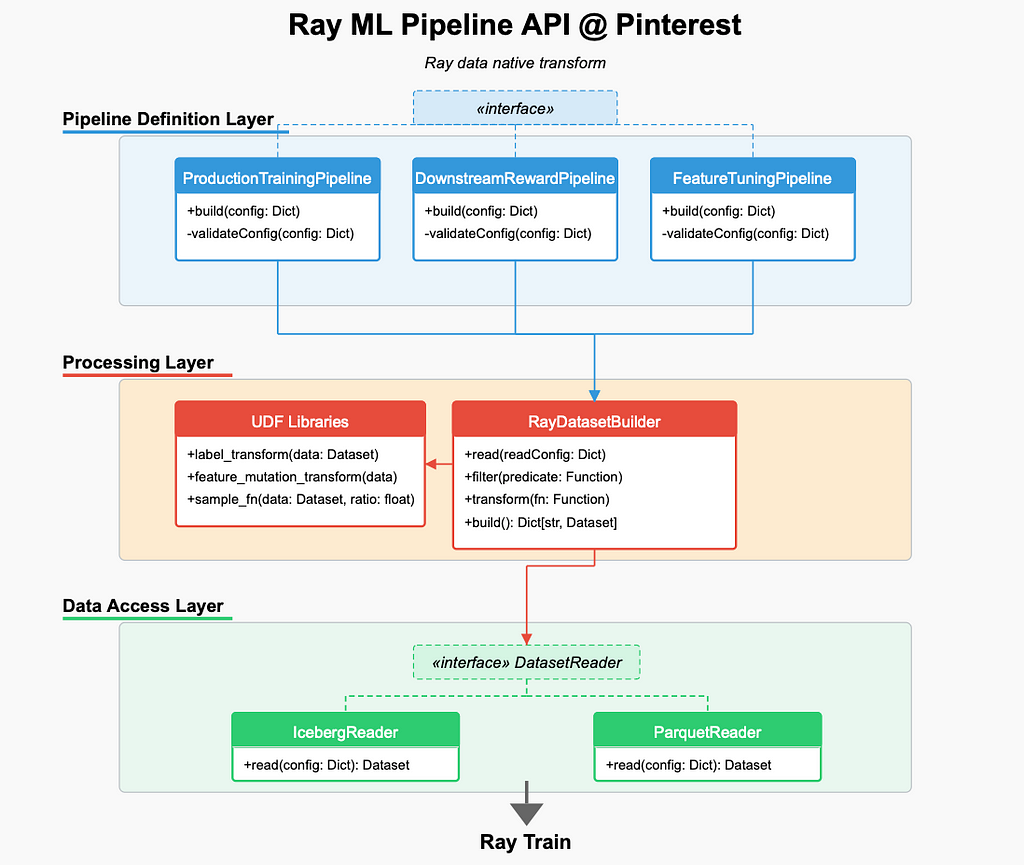
Impact:
Goal: Enable fast, efficient feature joins across different sources without precomputing large tables.
How:

Impact:
Eliminated the need for expensive pre-joining of data, allowing ML engineers to experiment with new features in hours rather than waiting days for traditional pipelines to complete.
Goal: The ability to write transformed data that can be efficiently read by subsequent experimentations and production retrains.
How:
Design:

This design addresses two common challenges in ML development:
With the new design, the process of developing new features from ideation to launching will become:
Impact:
Enable faster experimentation and hyperparameter tuning by avoiding redundant computation. Reduce the engineering efforts of end-to-end launching new features to production.
Goal: Accelerate large-scale ML workloads by optimizing Ray’s data processing capabilities.
How:
(This will be covered in detail in a future blog post, but we mention it here as an enabler of our approach.)
We have put significant effort to optimize data processing, and achieved 2–3X speedup across different pipelines. The optimization can be categorized into three categories: Ray Data, Feature Conversion and UDF efficiency.
a. Removing block slicing: Ray internally enables block slicing by setting the target_max_block_size attribute of DataContext to avoid excessively large blocks. This incurs significant CPU and memory overhead.
b. Remove combine_chunks: The combine_chunks function within the batcher can cause unnecessary data copying. This function was originally a workaround to prevent slowness on following operations, as a single continuous chunk can perform better than discrete chunks. Chunk combination will be performed only when necessary in our pipeline, and many operations are optimized for single chunks, so we can operate on the list of chunks without combining them.

2. Feature conversion
a. Deduplication by Request ID, Within a given batch of training data, certain features will share the same value due to their common origin. This data duplication presents an opportunity for optimization. The primary trade-off lies in balancing the computational cost of deduplication against the potential savings in conversion time, network transfer, and GPU memory utilization.

b. Redundant data copying and operations during pyarrow conversion can be avoided by implementing optimization on feature conversion, such as by avoiding null filling and reorder operations. These optimizations will be covered in a later blog post that focuses on optimization techniques.
3. UDF Efficiency
The efficiency of UDFs, such as filtering or aggregation transformations, is essential for overall pipeline performance, regardless of the data loader used. Slow UDFs can create bottlenecks due to the bucket mechanism.
a. Combining UDFs/Filters:
Consolidating filters into a single UDF minimizes data copying and enhances efficiency.
b. Numba JIT Optimization:
Numba employs Just-In-Time (JIT) compilation to translate segments of Python code into optimized machine code during runtime, significantly accelerating numerical computations and overall execution speed.
The combination optimization achieved significantly speed up on training and data transformation pipeline, on our homefeed ranking model training pipeline we are able to achieve 90% of roofline throughput.
With these improvements, we now have a fully Ray-powered ML workflow that extends beyond training:

This transformation reduces ML iteration times by 10X while significantly cutting infrastructure costs.
While we have made significant improvements, there’s still room for further expansion of Ray’s capabilities:
By extending Ray’s role beyond training into feature engineering, sampling, and labeling, we’ve unlocked a more scalable, efficient, and cost-effective ML infrastructure.
At Pinterest, Ray now powers end-to-end ML workflows, reducing iteration time, improving compute efficiency, and lowering infrastructure costs.
Scaling Pinterest ML Infrastructure with Ray: From Training to End-to-End ML Pipelines was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleScaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
It demonstrates how to scale multimodal LLMs for production by combining expensive VLM extraction with efficient dual-encoder retrieval. This architecture allows platforms to organize billions of items into searchable collections while maintaining high precision and low operational costs.
This article details how Pinterest scaled its recommendation system to leverage vast lifelong user data, significantly improving personalization and user engagement through innovative ML models and efficient serving infrastructure.