It demonstrates how to scale multimodal LLMs for production by combining expensive VLM extraction with efficient dual-encoder retrieval. This architecture allows platforms to organize billions of items into searchable collections while maintaining high precision and low operational costs.
Faye Zhang, Staff Software Engineer; Jasmine Wan, Machine Learning Engineer I; Qianyu Cheng, Machine Learning Engineer II; Matthew Hichar, Machine Learning Engineer II; Eric Wan, Sr. Software Engineer; Jinfeng Rao, Sr. Staff Machine Learning Engineer
Online retailers and social platforms now operate catalogs with billions of items. Pinterest is one example, but the underlying challenge of how to organize products into precise, navigable shopping collections at web scale is shared across large e‑commerce and social discovery systems. Historically, collections have been derived from user search history and manual curation. In the age of multimodal large language models (LLMs), it is now possible to invert this process and generate collections directly from the content itself while still grounding them in how people search.
Introducing our solution Pinlanding¹, a production‑oriented pipeline for shopping collection generation. The system is built around four components: (1) understanding user search patterns, (2) building and validating a shopping collection vocabulary using multimodal LLMs and LLM‑as‑judge, (3) constructing feeds from attributes, and (4) evaluating the system and evolving it for AI‑native search behavior.
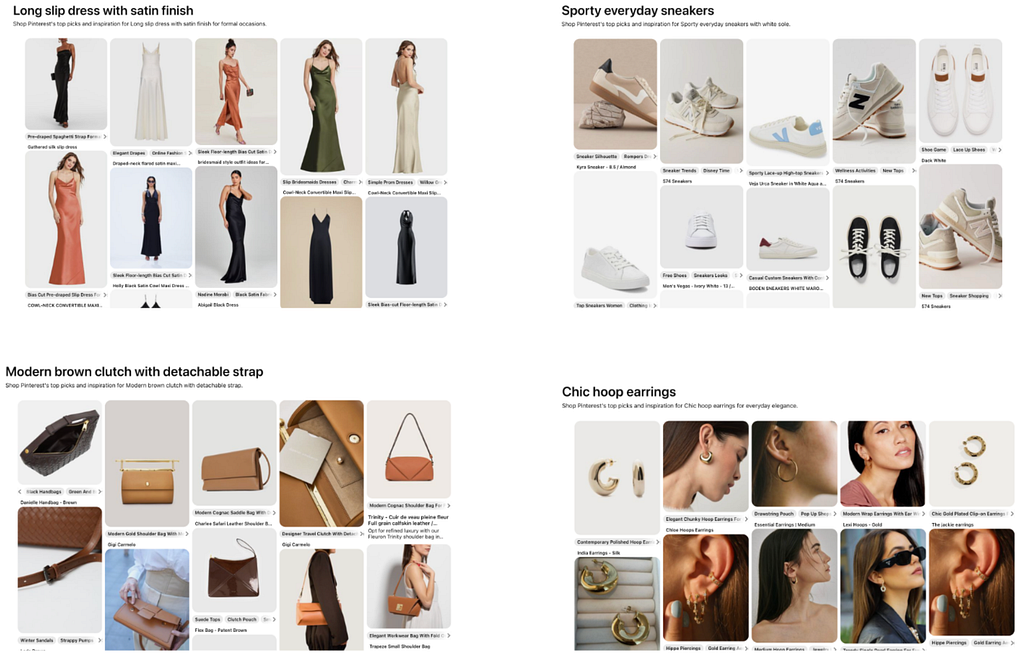
The starting point is a quantitative view of how users interact with the catalog. User search history, autocomplete interactions, filter usage, and browse paths are aggregated to estimate the distribution of shopping intents. At this stage, the goal is not to enumerate all possible topics but to understand current coverage and failure modes.
Two patterns typically emerge. First, there is a head of high‑volume, well‑formed queries (“black cocktail dress,” “white linen pants”) that are already served by existing shopping collections and ranking logic. Second, there is a growing trend with long tail and conversational search with AI chatbots (e.g., “what to wear for Italian summer vacation” or “long red satin dress with lace trim under $200”).
These data provide three important signals for the collection pipeline. They identify product spaces where demand is strong but coverage is thin. We highlight attribute dimensions that users care about (color, occasion, style, fit, price, brand, etc.) across 20 categories; they form the baseline against which a content‑first approach will be evaluated. The rest of the system is designed to increase topical coverage and precision relative to this query‑driven baseline, rather than to replace query understanding outright.
Once the behavior surface is characterized, the next step is to obtain a structured representation of each product that is rich enough to support collection generation.
Each product is modeled as a multimodal tuple consisting of an image and associated metadata such as title, description, merchant tags, and price. A vision‑language model (VLM) is used to generate candidate attributes. The model is prompted to output normalized key-value pairs rather than free‑form text, which simplifies downstream processing.
The raw VLM output has high recall but limited usefulness as‑is. It tends to produce large numbers of very specific attributes (“black insoles,” “lace‑trim hem with side slit”) and multiple near‑duplicate variants (“boho,” “bohemian,” “boho‑chic”) for the same underlying concept. These issues lead to an over‑sparse attribute space where most attributes apply to very few products, which in turn makes it difficult to form robust collections.
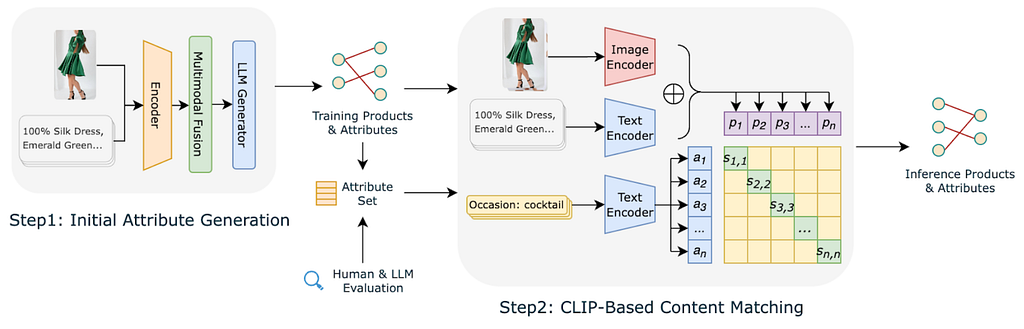
To address this, we introduce a curation pipeline to construct a compact, high‑quality attribute vocabulary. The process combines statistical filtering, embedding‑based clustering, and manual/LLM‑assisted review. First, attributes are filtered by frequency; attributes that apply to only a handful of products are almost never useful as collection keys and are dropped. This step removes the majority of ultra‑specific descriptors while preserving attributes that describe reusable shopping concepts. Second, dense text embeddings are computed for each remaining attribute, and attributes that are highly similar in embedding space are merged, with the more frequent surface form chosen as canonical. We then apply LLM‑as‑judge at the topic level to filter and rank these candidate queries for searchability. Given an attribute tuple and its generated query, a second LLM pass scores the pair along several dimensions: semantic coherence between the attributes and the text, plausibility as a real shopping intent, and alignment with typical search phrasing. This consolidation converts a long tail of attributes and phrasing variants into shopping topics that reflect true user search intent.
The curated attributes define the target label space, but assigning them to every product via the VLM would be computationally expensive and operationally fragile. Instead, the system trains a dual‑encoder model inspired by CLIP. One encoder ingests product image and text and outputs a product embedding. The other encoder ingests an attribute phrase and outputs an attribute embedding in the same space. During training, product-attribute pairs derived from the VLM are treated as positives; non‑matching attributes are treated as negatives.
For the Contrastive training objective, the model is trained with a bidirectional contrastive loss to align matching product-attribute pairs while pushing apart mismatched pairs.

At inference time, all products and all attributes are embedded once. An attribute is assigned to a product when the similarity between their embeddings exceeds a calibrated threshold (optionally adjusted by a frequency‑based weight to correct long‑tail smoothing). Compared to the original VLM outputs, this approach drastically reduces the number of distinct attributes while increasing the average number of attributes per product, producing a dense, consistent attribute graph suitable for downstream shopping tasks.
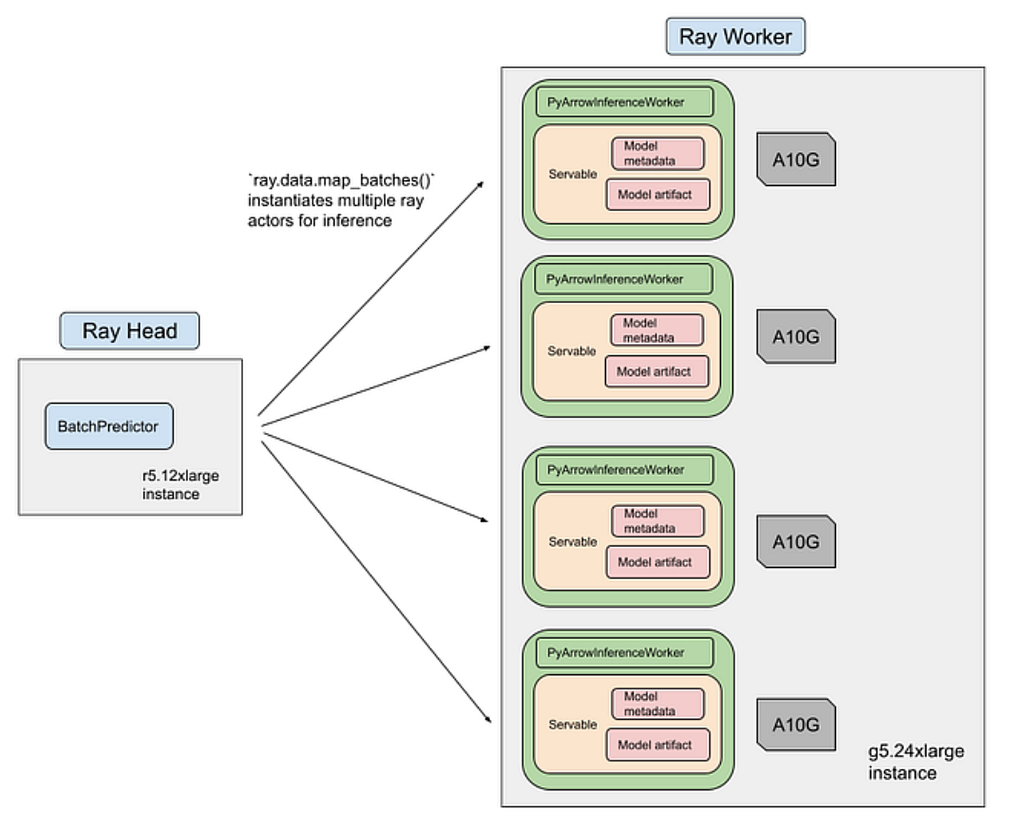
The attribute classifier and the feed builder must both operate at the scale of millions of Pins and millions of candidate topics. We use Ray² for scalable batch inference over the catalog and a ANN matching layer to construct feeds.
Attribute inference is executed as a Ray streaming job. The pipeline is organized into three stages. In the data loading and preprocessing stage, Pin images and metadata are downloaded, tokenized, and serialized into PyArrow tables, then sharded across a CPU cluster. In the ML inference stage, Ray schedules batches of preprocessed items onto a GPU pool where the CLIP‑based classifier runs forward passes to produce attribute scores. Streaming execution ensures that data loading, preprocessing, and inference overlap in time, and heterogeneous clusters let us scale CPU‑bound preprocessing and GPU‑bound inference independently. The overall training and inference pipeline for the classifier completes in roughly 12 hours on 8 NVIDIA A100 GPUs, with an estimated cost of about $500 per training run.
Once attribute assignments are available, feed construction proceeds via a ANN‑style and strict attribute via Spark matching layer. Each shopping topic is defined as a tuple of attributes. For example, category: dress, color: yellow, season: summer, occasion: party. We use distributed computation (Apache Spark in the current implementation) to compute relevance scores between topics and products. The scoring function aggregates the contribution of each shared attribute between topic and product, weighted by attribute‑level confidence. Candidate joins are pruned using attribute‑based partitioning and pre‑filters on minimum attribute overlap.
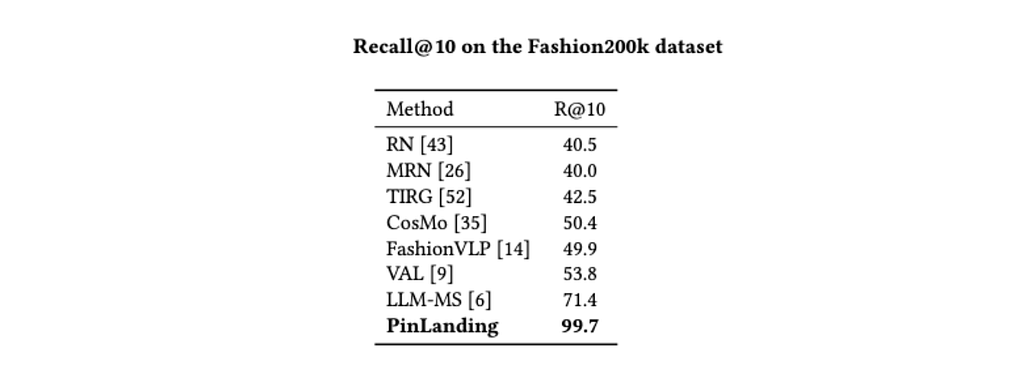
For attribute quality, the CLIP‑based model is evaluated on the Fashion200K dataset, a standard benchmark for fashion attribute prediction. The model achieves 99.7 percent Recall@10, substantially outperforming prior methods, which are in the 50 percent range on the same metric. This validates that the classifier has learned a strong mapping between product imagery and fashion attributes.
In addition, analysis of attribute frequency distributions confirms that the CLIP‑based classifier produces a much more usable attribute space than raw GPT‑4‑V outputs, with far fewer extremely rare attributes and a larger proportion of attributes that consistently describe many products.
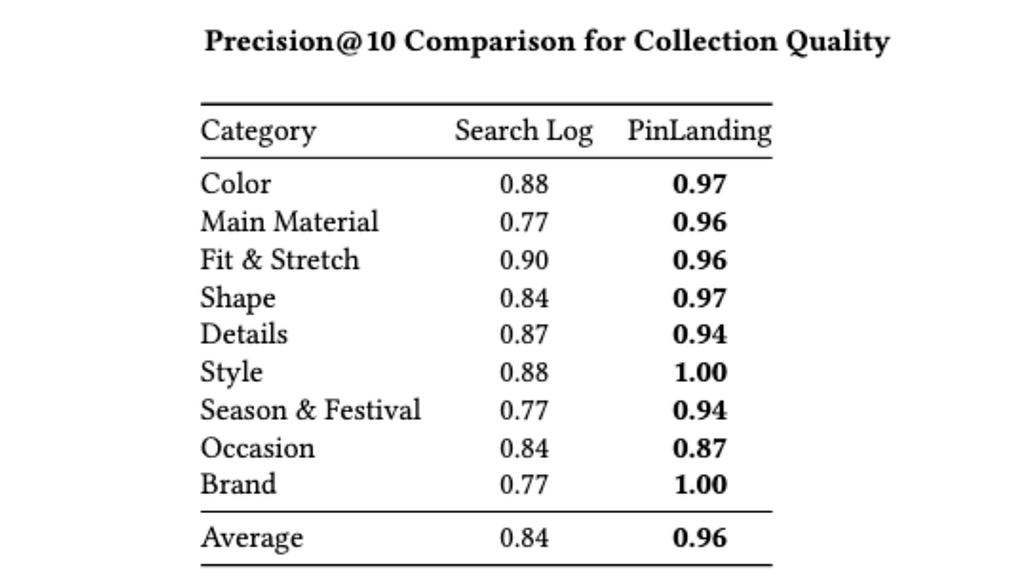
For collection quality, human raters compare feeds generated by the content‑first pipeline against a traditional search‑log‑derived baseline. Precision@10 is measured as the fraction of the top ten products in a collection that satisfy the collection’s title attributes. Across attribute families such as color, main material, fit and stretch, shape, style, season and festival, occasion, and brand, the new system improves average precision@10 from 0.84 to 0.96, with several categories (style and brand) reaching 1.00.
In production, the pipeline is deployed to generate fashion shopping collections for external search traffic as well as internal discovery surfaces. The content‑first approach yields 4.2 million shopping landing pages, a four‑fold increase in unique topics relative to the previous search‑log‑based approach, and leads to a 35% improvement in search performance.
Looking ahead, the same framework can be extended beyond shopping collection to any topical collections including Ads, Notifications, etc. However, many of the viral internet queries express composite concepts (for example, “old money aesthetic work outfits,” “Barbiecore party decor”) that are not directly represented in a fixed attribute schema. To bridge this gap, we are integrating social and trend signals and are actively developing an AI‑agent–based layer that decomposes emerging concepts into attribute patterns and maps them into our existing content‑first pipeline.
Reference
¹ F. Zhang, J. Wan, Q. Cheng, and J. Rao, “PinLanding: Content-First Keyword Landing Page Generation via Multi-Modal AI for Web-Scale Discovery,” arXiv preprint arXiv:2503.00619, 2025. [Online]. Available: https://arxiv.org/abs/2503.00619
² Pinterest Engineering, “Ray batch inference at Pinterest (Part 3),” Medium, [Online]. Available: https://medium.com/pinterest-engineering/ray-batch-inference-at-pinterest-part-3-4faeb652e385. Accessed: Dec. 1, 2025.
PinLanding: Turn Billions of Products into Instant Shopping Collections with Multimodal AI was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleScaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
This article demonstrates how to significantly accelerate ML development and deployment by leveraging Ray for end-to-end data pipelines. Engineers can learn to build more efficient, scalable, and faster ML iteration systems, reducing costs and time-to-market for new features.
This article details how Pinterest scaled its recommendation system to leverage vast lifelong user data, significantly improving personalization and user engagement through innovative ML models and efficient serving infrastructure.