This article demonstrates how to scale personalized recommendation systems using transformer-based sequence modeling. It provides a blueprint for transitioning from coarse-grained to fine-grained candidate generation, improving ad relevance and efficiency in large-scale production environments.
Lakshmi Manoharan | Senior Machine Learning Engineer, Ads Vertical Modeling; Karthik Jayasurya | Staff Machine Learning Engineer, Ads Signals ; Ziwei Guo | Senior Machine Learning Engineer, Ads Vertical Modeling; Joy Xin | Machine Learning Engineer II, Ads Vertical Modeling; Alina Liviniuk | Machine Learning Engineer II, Ads Vertical Modeling
At Pinterest, ads are more than just advertisements; they are a vital part of the content ecosystem, designed to inspire users and connect them with products and ideas they love. Our goal is to surface the right ads at the right time, ensuring they seamlessly integrate into a user’s shopping journey and provide genuine value. To achieve this, understanding user behavior is paramount.
Delivering highly relevant ads in a dynamic environment like Pinterest presents unique challenges. Users’ interests and shopping intents evolve rapidly, making it crucial for our ad systems to adapt and anticipate their needs. Traditional ad targeting methods often rely on broad demographic data or static interest categories, which can fall short in capturing the nuanced and evolving nature of user behavior.
To address this challenge, the Pinterest Ads team has embarked on a new effort: enhancing our Ad Candidate Generation using advanced behavioral sequence modeling. The core idea is to leverage the rich historical sequence of user offsite behavior to predict their future conversions with advertisers and products.
We initially focused on developing a transformer-based sequence model to encode user behavior and predict which advertisers a user is most likely to interact with next. By analyzing the sequence of products a user has viewed, purchased, or added to cart, the model learns to identify patterns and signals that indicate a propensity for engaging with specific advertisers. This allows us to generate a highly personalized set of advertiser candidates, significantly improving the relevance of the ads presented to the user.

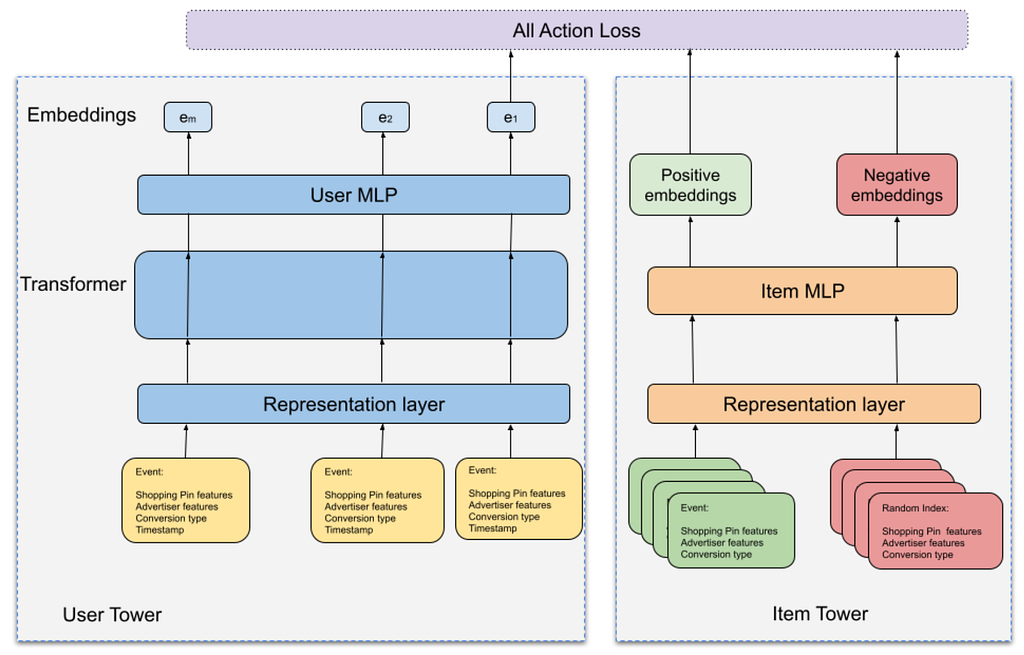
We use a two-tower model where
We use in-batch negatives to construct <user sequence, positive, negative> triplets and employ the sampled softmax loss for training the model. We define positives as events with conversion type ∈ {checkout, add-to-cart, signup} sampled from a K-day future window. We also add log-Q bias correction terms to the sampled softmax loss in order to avoid over-penalizing popular items.


The primary evaluation metric for measuring model performance is Recall@K. Given the embedding based retrieval paradigm, the offline metrics focus on the ability to retrieve positive labels against a random indexed set of advertisers. Specifically, at a given time period t when the training period ends, we first compute embeddings for all users in the evaluation set in (t, t+k) window. Then, we measure the cosine similarity score between user embedding and advertiser embeddings from positive interactions, and evaluate hit rate against a sampled index of 2M advertiser embeddings in order to compute Recall@K. This measure is averaged across all users, weighted by frequency, to report aggregate recall at different K (up to 1000).
An offline batch workflow predicts the top-100 relevant advertisers for each user based on their offsite behavior and publishes it to the online feature store. When an ad request comes in, the Ads Serving system retrieves the predicted list of top advertisers for the user from the feature store and passes on eligible ads from these advertisers to the downstream light-weight L1 ranker for scoring. The top ads as scored by L1 are further capped to a predefined quota, blended with ads from other candidate generators and sent downstream to heavy-weight scoring models and marketplace auction.

In online experiments, we observed a significant lift in conversion volume and a reduction in CPA (cost per action). This advertiser-level model has been serving production traffic since its initial launch in Spring 2024 for Standard ads.
Note: Shopping ads refer to ads that are designed specifically to promote products from a merchant’s product catalog, whereas standard ads refer to ads that promote Pins, which can be any type of content (not limited to products in a catalog).
Building upon this foundation, our next goal was to predict not just the advertiser, but the specific products a user will interact with next. This involves an even deeper understanding of user intent, long-term interests and product attributes. By predicting item-level engagement, we can move towards a truly deeper personalized ad experience, where users are shown the exact products they are most likely to be interested in at any given moment. This advanced capability has the potential to unlock new levels of user satisfaction and ad performance. Besides, the Ads delivery funnel is fundamentally item-based. Given the scale of growth of the Pinterest catalog, it is not practically feasible to continue to personalize at the advertiser level, as that would lead to the more complex downstream models scoring an exponentially large pool of items within those selected advertisers.
Our architecture utilizes a two-tower approach, analogous to the advertiser-level two-tower model. However, we adapt the candidate tower to represent individual shopping product Pins. To create richer, item-granular representations, we incorporate two key elements: internal Pin embeddings learned from Pinterest’s engagement graph data and the associated product’s metadata features from catalog.
Given the extremely large scale of the item corpus (over 1 billion), we utilize a dual approach for the negative corpus: both in-batch negatives and a randomly sampled set of 20 million Pins. This strategy is employed to enhance contrastive learning and derive more meaningful semantic representations. The model is trained using the identical set of key conversion types as labels. However, to optimize for both retrieval performance and diversity metrics — at both the product and advertiser levels — the label weights and the log-Q parameters within the sampled softmax loss function are carefully tuned.
Once trained, the model artifact is used in a daily inference job that computes up-to-date user embeddings based on recent activity. To minimize redundancy and save compute, each day, we only infer embeddings for users with new activities and append them to a prior snapshot in the feature store. The exported item tower is directly used for indexing hundreds of millions of ad items at Pinterest.
Model performance is primarily assessed using hit rates at various K, which are calculated based on the cosine similarity between user and Pin representations, mirroring the offline evaluation methods for advertiser prediction. For the final model selection, a balance between overall retrieval effectiveness and diversity is achieved by considering both item and advertiser level Recall@K metrics, as every Shopping Pin is associated with an advertiser. Furthermore, given the inherent noise and sparsity of user offsite activity data, we also evaluate the predictions qualitatively to understand the semantic relevance of the model’s predictions.
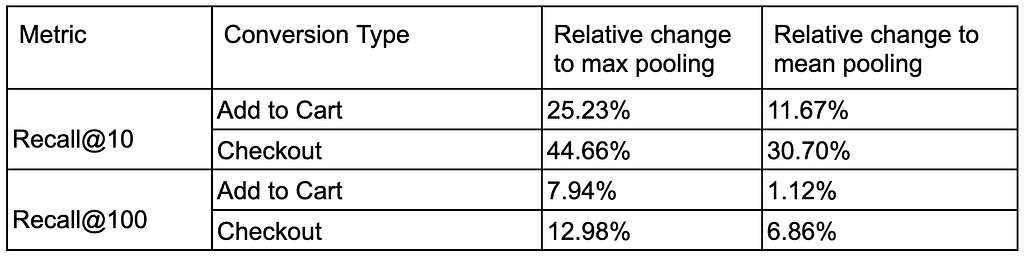
We evaluated recall metrics at K=10 and K=100 against two baselines: max pooling and mean pooling. These pooled models are simple MLPs, trained on aggregated (pooled) embedding features without incorporating a transformer model. Ultimately, the final model demonstrated up to a 45% improvement in user checkout performance, signifying a capture of deeper and more actionable intent.
The item embeddings generated by the model are used to construct an ANN (Approximate Nearest Neighbor) graph for efficient retrieval. During online serving, user embeddings produced by model inference are leveraged to retrieve the top K items from the ANN graph. In online experiments, we observed a significant reduction in CPA (cost per action) and lift in conversion volume, with minimal impact on other key online metrics. This demonstrates the effectiveness of the new model in discovering novel conversion ads based on users’ offsite interests. This item-level model has been serving production traffic since its initial launch in Spring 2025.
Below we share some of our empirical learnings from working on this project.
Our initial approach using log-Q bias correction, while achieving reasonable recall, steered the model toward predicting items from the most frequent advertisers, resulting in poor personalization. To resolve this, we carefully tuned the weight for the log-Q correction parameters for both positive and negative examples within the softmax loss function. We also introduced a metric to measure diversity: the fraction of random indices covered by 90% of the top retrieved results and was used to achieve a careful balance between performance and diversity.
Given that the item distribution is different between the offsite and onsite item corpus, we removed high-cardinality ID features from the large item corpus. We retained only coarse-level ID features, such as the advertiser ID, which were incorporated through a hash embedding layer. This approach allowed the model to better capture higher-level affinities and understand user behavioral interactions. As a result, we achieved strong overall performance at the advertiser and category level.
We experimented with increasing the sequence length up to 1024, but observed that recall gains diminished significantly after a length of 100. Given the sparsity of conversion history, longer sequences pose the risk of introducing stale and noisy interests, in addition to increasing infrastructure costs during model serving. To address this, we plan to enhance sequences with data from onsite domains and implement cross-domain learning strategies. This will improve knowledge transfer, after which we will re-evaluate the benefits of using a longer input sequence.
Contrary to the findings in the PinnerFormer paper, we find that the All Action Loss performs better than the Dense All Action Loss for our use case. This could be due to the sparse nature of conversion events leading to the ordering of events playing a more important role in the model’s predictions, compared to PinnerFormer, which creates an embedding representation from users’ onsite behavior.
Ads Audience Modeling Team: Chongyuan Xiang, Jiayin Jin, Kevin Liao
Ads Ranking Team: Yinrui Li, Kaili Zhang
ATG Team: Nikil Pancha, Haoyu Chen
Leadership: Alice Wu, Leo Lu, Siping Ji, Ling Leng, Hari Venkatesan
Ads Candidate Generation using Behavioral Sequence Modeling was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleStandard recommendation systems often over-optimize for immediate clicks, leading to user churn. By modeling the lifecycle of specific interests (UICs), engineers can build systems that prioritize long-term retention and discovery, ensuring platforms remain relevant as user needs evolve.
Scaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
This approach solves the 'cold start' of session intent in recommendation systems by blending offline historical sequences with real-time context. The hybrid inference model balances computational efficiency with immediate relevance, significantly improving candidate survival in ranking funnels.