This case study highlights that even mathematically superior models fail if serving infrastructure lacks feature parity with training. It provides a blueprint for diagnosing ML system discrepancies by auditing the entire pipeline from embedding generation to funnel alignment.
Authors: Yao Cheng | Senior Machine Learning Engineer; Qingmengting Wang | Machine Learning Engineer II; Yuanlu Bai | Machine Learning Engineer II; Yuan Wang | Machine Learning Engineer II; Zhaohong Han | Machine Learning Engineer Manager ; Jinfeng Zhuang | Senior Machine Learning Engineer Manager

The L1 ranking stage sits in the middle of Pinterest’s ads funnel. It filters and prioritizes candidates under tight latency constraints so that downstream ranking and auction systems only see a manageable set of ads.
When we started pushing new L1 conversion (CVR) models, we saw the same pattern repeatedly:
This gap between offline evaluation and online A/B performance, which we call our Online–Offline (O/O) discrepancy, kept promising models from launching.
In this post, we’ll walk through:
For L1 CVR models, we look through two very different lenses:
Offline metrics
Online metrics
In a perfect world, a model that reduces offline loss and improves calibration would also improve conversions and thus reduce CPA eventually. In practice, for our new L1 CVR models we saw:
Offline
Online (Budget-Split experiments)
In other words, models that were clearly better on offline metrics did not reliably translate into online wins.
Instead of trying to guess a single root cause, we treated this as a full‑stack diagnosis and organized our hypotheses into three layers:
For each bucket of hypotheses we asked: “Could this alone explain the O/O gap we see?” Then we used data to accept or reject it.
We first revisited offline evaluation to make sure we weren’t chasing a mirage by:
Across all of these, the experimental CVR model consistently:
So the offline story was robust: the new model really was better on the data we were using. Offline evaluation bugs alone could not explain the neutral online results.
Next, we looked at exposure bias — the idea that when the control model owns most of the traffic, downstream systems and labels are optimized around it, making it hard for a small treatment to look good.
We ran a ramp where treatment traffic went from ~20% up to ~70%, and monitored online calibration and loss for both auction candidates and auction winners before and after the ramp
If exposure bias were the main issue, we would expect treatment metrics to improve as it owned more traffic. We did not see that pattern; the over‑calibration issue persisted even at higher treatment shares.
Finally, we double‑checked timeouts and serving health by comparing success rate and p50/p90/p99 latency across control and treatment for both query and Pin towers.
We did not see materially worse timeout or tail‑latency behavior for treatment. This matched prior L1 investigations on engagement models, where timeouts rarely explained large O/O gaps.
In summary, across offline evaluation, exposure bias, and serving health checks, these were all necessary sanity tests, but none of them could, on their own, explain the discrepancy we observed.
The deeper investigation converged on two structural issues where training and serving did not line up:
L1 Pin embeddings are built from indexing snapshots and fed into an ANN index used by retrieval and L1 ranking. This pipeline is separate from the L2 Feature Store used downstream. In other words:
When we put the two side by side (offline insertion tables vs. online feature‑coverage dashboards), it turned out several high‑impact Pin feature families had never made it into the L1 embedding path at all, including:
These signals existed in training logs, so the model quite reasonably learned to lean on them. But at serving time, they were missing from the embeddings, which meant that for many oCPM and performance‑sensitive ads, the online model was effectively running on a much thinner feature set than the one it was evaluated on offline.
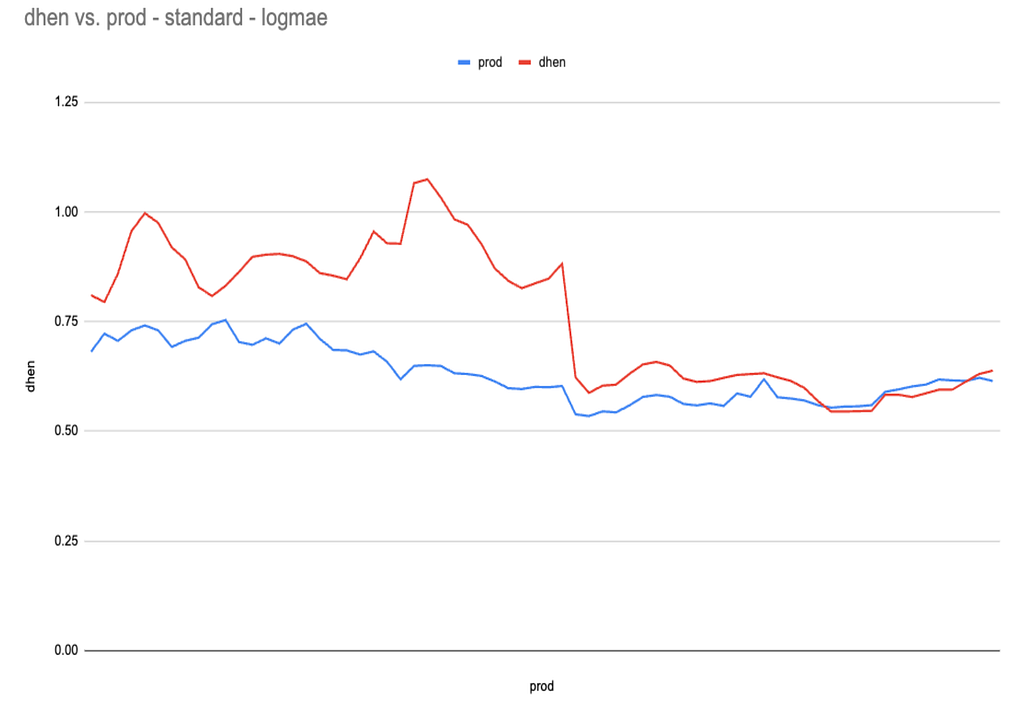
To fix this, we updated UFR configs to onboard the missing features into L1 embedding usage, and watched coverage recover in the online feature‑coverage dashboards, along with online loss moving in the right direction for both CVR and engagement models (especially on shopping traffic).
We also changed the default behavior in the UFR tooling so that features onboarded for L2 are automatically considered for L1 embedding usage, closing a recurring source of silent O/O issues.
Key lesson: It’s not enough for features to exist in training logs or the Feature Store — they also need to be present in the serving artifacts (like ANN indices) that L1 actually uses to serve traffic.
The second issue is specific to two‑tower architectures. Even when features are correct, the query and Pin towers may not be producing embeddings from the same model checkpoint.
The result is a natural amount of version skew: dot products between a query from version X and Pins whose embeddings may come from X, X–1, X–2, and so on.
To understand how much this mattered, we ran controlled sweeps where we:
The takeaway was:
Instead of trying to completely eliminate skew (which is hard in a live system), we started treating it as a deployment constraint: for large tiers we favor batch embedding inference so each ANN build uses a single, consistent embedding version, and we require every new model family to go through explicit version‑skew sensitivity checks as part of model readiness.
Embedding skew by itself did not account for every aspect of the O/O gap, but it helped align our expectations: offline numbers came from a cleaner world than the one the model actually lived in online.
Fixing features coverage and embedding skew closed most of the gap between “what we thought we were serving” and “what was actually running in production.” But we still had to answer a more systemic question:
What if the predictions are fine, but the rest of the system doesn’t translate them into CPA wins? Two concepts turned out to be especially important: funnel alignment and metric mismatch.
The ads funnel has multiple stages — retrieval, L1 ranking, L2 ranking, auction — each optimized under different constraints. An L1 model can be strictly better on its own metrics and still fail to move the overall system if the rest of the funnel is already close to its limits or is misaligned. To study this, we tracked:
Across multiple experiments, we saw cases where:
This told us that beyond a certain point, L1 model quality is not the bottleneck — the funnel and utility design are.
We also had to internalize that offline and online metrics live in different regimes:
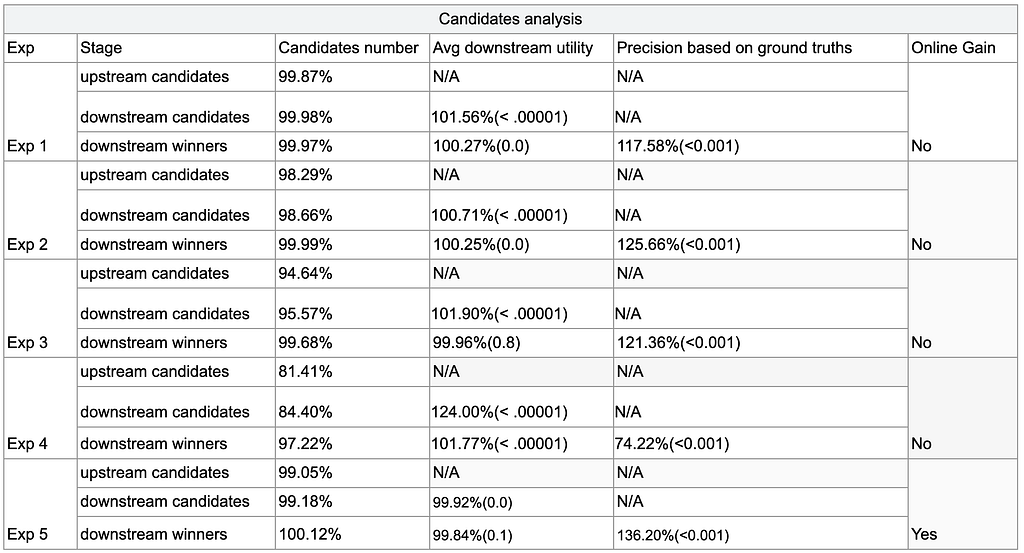
Replay analyses showed that:
This doesn’t mean offline metrics are useless — far from it. But they are necessary, not sufficient. You need to interpret them through the funnel and utility context they’re going to live in.
The big shift from this work is mindset: O/O discrepancy is not something you debug at the end; it’s something you design for from the start.
For L1 at Pinterest, that means:
By baking these ideas into our launch process, we’ve taken a frustrating blocker and turned it into a set of tools and habits that make future L1 experiments more predictable — and make it much easier to ship models that improve both offline metrics and real‑world outcomes.
We’d like to thank Xiao Yang, Peng Yan, Qingyu Zhou, Longyu Zhao, Li-Chien Lee, Fan Zhou, Abe Engle, Tristan Lee, Lida Li, Shantam Shorewala, Haoyang Li for their critical contributions to this analysis, and thank Jinfeng Zhuang, Zhaohong Han, Ling Leng, Tao Yang, Haoyang Li for their strong support and exceptional leadership.
Bridging the Gap: Diagnosing Online–Offline Discrepancy in Pinterest’s L1 Conversion Models was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleStandard recommendation systems often over-optimize for immediate clicks, leading to user churn. By modeling the lifecycle of specific interests (UICs), engineers can build systems that prioritize long-term retention and discovery, ensuring platforms remain relevant as user needs evolve.
Scaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
This approach solves the 'cold start' of session intent in recommendation systems by blending offline historical sequences with real-time context. The hybrid inference model balances computational efficiency with immediate relevance, significantly improving candidate survival in ranking funnels.