This article demonstrates a practical approach to significantly improve CI/CD pipeline efficiency and developer experience. By intelligently caching and reusing build artifacts, engineering teams can drastically reduce build times and infrastructure costs.
In the world of DevOps and Developer Experience (DevXP), speed and efficiency can make a big difference on an engineer’s day-to-day tasks. Today, we’ll dive into how Slack’s DevXP team took some existing tools and used them to optimize an end-to-end (E2E) testing pipeline. This lowered build times and reduced redundant processes, saving both time and resources for engineers at Slack.
For one of our largest code repositories (a monolithic repository, or monorepo), Slack has a CI/CD pipeline that runs E2E tests before merging code into the <span style="font-weight: 400">main</span> branch. This is critical for ensuring that changes are validated across the entire stack for the Slack application: frontend, backend, database, and the handful of services in between. However, we noticed a bottleneck: building the frontend code was taking longer than expected and occurred too frequently, even when there were no frontend-related changes. Here’s the breakdown:
This entire process took about 10 minutes per run. Half of that time, around 5 minutes, was consumed by frontend builds, even when no frontend changes were involved.

Given that hundreds of pull requests (PRs) are merged daily, these redundant builds were not only time-consuming, but costly:
<span style="font-weight: 400">main</span>, causing terabytes of duplicate data.To tackle this, we leveraged existing tools to rethink our build strategy.
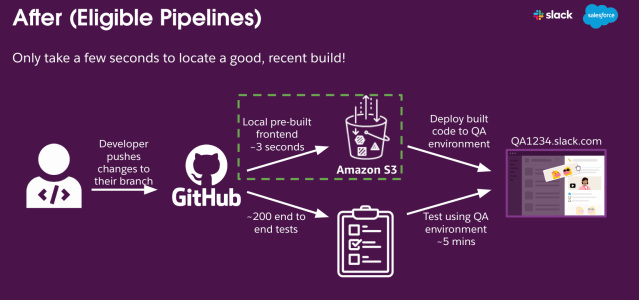
Our first step was determining whether a fresh frontend build was necessary. We detected changes by utilizing <span style="font-weight: 400">git diff</span> and its 3-dot notation to identify the difference between the latest common commit of the current checked-out branch and <span style="font-weight: 400">main</span>. If changes were detected, we invoke a frontend build job. If no changes were detected, we skipped the build entirely and reused a prebuilt version.
When a frontend build is not needed, we locate an existing build from AWS S3. To be efficient, we use a recent frontend build that is still in Production. We delegate the task of serving the prebuilt frontend assets for our E2E tests to an internal CDN. This reduced the need for creating a new build on each PR, while still ensuring we test on current assets.
While the approach seemed straightforward, scaling this solution to our monorepo presented a few challenges:
Our efforts paid off, delivering remarkable improvements:

By strategically utilizing existing tools like <span style="font-weight: 400">git diff</span> and internal CDNs, we managed to save valuable developer time, reduce cloud costs, and improve overall build efficiency.
For teams in other companies facing similar bottlenecks in DevOps and DevXP, the lesson is to question what’s truly necessary in your pipeline and optimize accordingly. The improvement from this project seems obvious in hind-sight, but it’s common to overlook inefficiencies in systems that haven’t outright failed. In our case, rethinking how we handled frontend assets turned into a massive win for the organization.
There are a lot of moving parts in a project like this: complex pipelines for building and testing, cloud infrastructure, an internal CDN, intricate build systems for frontend code, and existing custom setups throughout our entire system. It includes code written in Python, JavaScript, Bash, PHP/Hack, Rust, YAML, and Ruby. We achieved this without any downtime! Okay, almost. There was ten minutes of internal downtime for our deployment pipeline, but it was fixed pretty quickly.
This work was not possible without contributions from:
Anirudh Janga, Josh Cartmell, Arminé Iradian, Anupama Jasthi, Matt Jennings, Zack Weeden, John Long, Issac Gerges, Andrew MacDonald, Vani Anantha and Dave Harrington
Interested in taking on interesting projects, making people’s work lives easier, or just building some pretty cool forms? We’re hiring!
Continue reading on the original blog to support the author
Read full articleShipyard brings container-like deployment practices to EC2, enabling immutability and automated safety at scale. By treating infrastructure as artifacts, Slack reduces drift and improves security for critical workloads that cannot easily migrate to containers.
Agentic testing shifts E2E focus from rigid journeys to goal-based verification. While too slow and costly for every PR, it provides a powerful exploratory layer that adapts to UI changes and handles complex state transitions where traditional deterministic scripts often fail.
This article provides a blueprint for scaling enterprise LLM infrastructure. It details the transition from manual GPU management to managed services, highlighting how to balance security, cost-efficiency, and reliability through strategic multi-cloud orchestration and capacity forecasting.
This migration demonstrates how to eliminate stateful, insecure SSH dependencies in large-scale data platforms. It shows a path toward better reliability, finer audit granularity, and modern infrastructure like Spark on Kubernetes by adopting stateless REST-based orchestration.
 Explore Opportunities
Explore Opportunities