This migration demonstrates how to eliminate stateful, insecure SSH dependencies in large-scale data platforms. It shows a path toward better reliability, finer audit granularity, and modern infrastructure like Spark on Kubernetes by adopting stateless REST-based orchestration.
By 2024, Slack’s data platform had accumulated 700+ SSH-based operators orchestrating critical data pipelines. We’re talking daily search indexing that processed terabytes of data, analytics jobs powering business intelligence, the whole shebang. Every single one of these jobs required direct SSH access to production AWS Elastic MapReduce (EMR) clusters. We had a massive security surface, and we couldn’t move forward on any infrastructure modernization. Not ideal.
We needed to eliminate SSH entirely. The solution? Migrate all 700+ jobs to a REST-based architecture. This is the story of how we killed SSH entirely, across 8 data regions, with zero downtime.
Slack’s data platform was built around 2017 with a straightforward pattern. Airflow, our data pipeline orchestrator, needed to run jobs on EMR clusters, and SSH was the most direct path. Connect to the EMR master node, execute a command, done. Simple.
# The old way - simple, but problematic
task = SSHOperator(
task_id='run_spark_job',
ssh_conn_id='emr_master',
command='spark-submit /path/to/job.py',
)
This pattern proliferated across the platform. Teams built custom SSH-based operators for different use cases (because hey, if SSH works for Spark, why not everything else). By the time we took stock, we had 700+ jobs in production running everything from MapReduce jobs to AWS CLI commands to custom Python scripts.
It worked. But it came with some potential problems.
The Search Infrastructure team’s pipeline builds Solr search indexes from terabytes of data daily. This pipeline powers Slack’s search functionality. Any disruption affects search quality for millions of users. And it was relying on SSH-based job submission with all the reliability problems mentioned above. Not great.
Before diving into the solution, let’s establish what REST-based job submission actually means (and why it matters).
When you SSH into a machine and run a command, you’re creating a direct, stateful connection. If that connection drops (say your Kubernetes pod restarts), the command might keep running, might fail, or might leave orphaned processes hanging around. You’ve got no reliable way to reconnect and check status. It’s like hanging up mid-phone call and hoping the other person finishes the conversation.
Modern compute engines (YARN, Trino, Snowflake) expose HTTP APIs for job submission. Instead of maintaining a connection, you:
The job lifecycle is managed server-side. Your client can crash and restart, and the job keeps running while you can still query its status. Much better.
For Hadoop workloads (MapReduce, Spark, Hive), YARN is the resource manager with a REST API for job submission. But here’s the catch: YARN’s API is designed for Hadoop jobs. What about the 300+ CLI-based jobs running arbitrary shell commands like aws s3 sync or hadoop distcp?
That’s where YARN Distributed Shell comes in. This was the key breakthrough that made this whole migration possible.
Migrating Spark and Hive jobs was more straightforward. Spark has the Livy REST API and Hive has HiveServer2. But MapReduce jobs and the 300+ CLI-based jobs running arbitrary shell commands? Those were the hard parts. They didn’t have ready-made REST APIs.
We brainstormed multiple approaches. Our requirements were clear:
Some ideas we considered:
All of these felt too complex, required custom security implementations, or introduced new dependencies we’d have to maintain. Not great options.
Then we discovered YARN’s Distributed Shell. It’s a little-known feature (org.apache.hadoop.yarn.applications.distributedshell.ApplicationMaster) that allows any shell script to run in a proper YARN container with resource allocation and lifecycle management. And here’s the kicker: it was already part of YARN, used the same REST APIs, and required no custom security layer. It was perfect.
Here’s how it works:
For example, we could upload the following script (command.sh) to s3://bucket/
# command.sh
aws s3 sync /tmp/data/ s3://bucket/output/{
"application-type": "MAPREDUCE",
"am-container-spec": {
"commands": {
"command": "{{JAVA_HOME}}/bin/java org.apache.hadoop.yarn.applications.distributedshell.ApplicationMaster ..."
},
"environment": {
"DISTRIBUTEDSHELLSCRIPTLOCATION": "s3://bucket/command.sh",
"DISTRIBUTEDSHELLSCRIPTLEN": "548",
"DISTRIBUTEDSHELLSCRIPTTIMESTAMP": "1768529627000"
}
}
}
Yarn manages:
This architectural decision unlocked the migration of all SSH-based jobs. Not just Hadoop workloads, but any shell command. Whether it was aws s3 sync, hadoop distcp, or custom Python scripts, they could all run in proper YARN containers. Game changer.
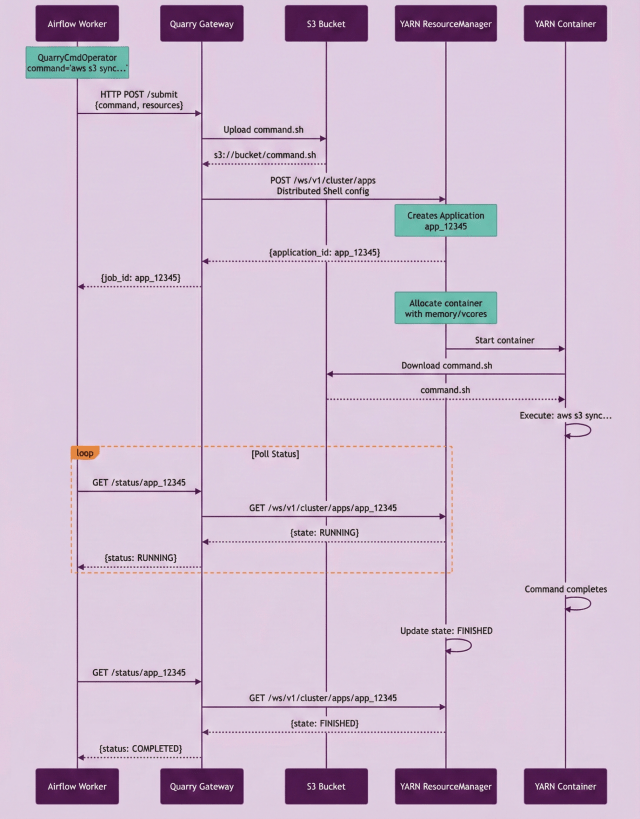
Figure 1: YARN Distributed Shell job submission flow showing how arbitrary shell commands are executed in YARN containers through Quarry.
Now that we understand the advantages of REST-based job submission and how we can migrate each existing job type, we’re just missing one thing: an orchestrator.
Enter Quarry, Slack’s REST-based job submission gateway. Quarry was originally built to provide a unified interface for submitting jobs across multiple compute engines (EMR/YARN, Trino, Snowflake). It already solved authentication, reliability, and observability challenges. For SSH deprecation, it turned out to be exactly what we needed.
Quarry sits between various services and compute engines (Airflow being the biggest user), handling:
Before:
Airflow → SSH Connection → EMR Master Node → Execute CommandAfter:
Airflow → Quarry REST API → YARN ResourceManager → EMR ContainerInstead of establishing SSH connections, Airflow operators make HTTP requests to Quarry. Quarry submits jobs to YARN and polls for status. If an Airflow pod restarts, the job keeps running, and Quarry maintains the connection.
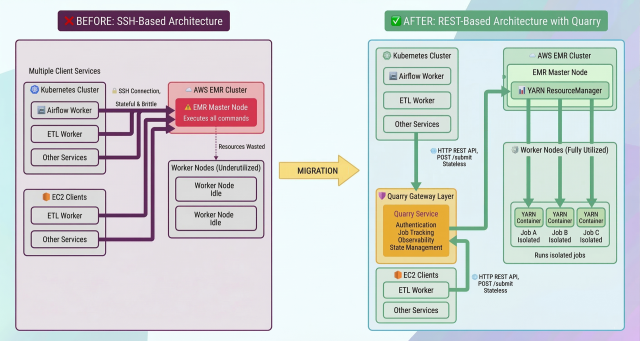
Figure 2: Architecture comparison showing the shift from SSH-based direct execution to REST-based job submission through Quarry and YARN.
With YARN Distributed Shell support, Quarry became our universal job submission gateway. Whether you’re running a Spark job, a Hive query, or a simple shell script, it all goes through the same REST API.
No SSH credentials. No direct cluster access. Just REST API calls with proper authentication and server-side job tracking.
We knew from the start this wasn’t going to be a quick fix. We had 700+ production jobs across 8 independent data regions, each with unique network configurations and data sovereignty requirements. Critical workloads, like search indexing, couldn’t tolerate any downtime. So yeah, we needed a plan.
Phase 1 – Proof of Concept: Started with pilot jobs to validate the Quarry-based approach. Built the first Quarry operators and tested in dev environments.
Phase 2 – Security Review: Engaged security teams to plan credential elimination and ensure the REST-based approach met security requirements.
Phase 3 – OKR-Driven Execution: Made it a Key Result with executive visibility. This created accountability and kept it prioritized. We hit the 80% migration milestone during this phase.
Phase 4 – Bulk Migration: Heavy cross-team coordination to migrate remaining workloads across all regions. Multiple teams (Search Infrastructure, Data Engineering & Analytics, ML Services) worked in parallel.
Phase 5 – Final Cleanup: Completed overlooked DAGs and deprecated all legacy SSH-based operators. Achieved 100% completion.
No migration this size goes smoothly. Here are the biggest obstacles we ran into (and how we dealt with them).
During migration of a data export DAG, we hit unexpected failures. Jobs that’d been running fine via SSH were now failing with vmem (virtual memory) check errors. What gives?
The root cause: SSH commands ran directly on the master node, bypassing YARN’s resource enforcement entirely. Quarry submits jobs properly to YARN, which actually enforces resource limits. The vmem check was rejecting containers that exceeded virtual memory limits (which SSH had been quietly ignoring).
The fix: Following AWS best practices, we disabled vmem checks across all clusters:
"yarn.nodemanager.vmem-check-enabled": "false"AWS explicitly recommends this because virtual memory accounting in Linux can be unreliable, and physical memory limits are sufficient. (Also, it’s worth noting that vmem checks have been a source of spurious failures for years in the Hadoop ecosystem.)
Lesson learned: When migrating from SSH to proper YARN submission, expect to encounter resource limit issues that were previously invisible. SSH hides a lot of problems. Test thoroughly in dev environments before production rollout.
During migration of dev search infrastructure jobs from one dev cluster to a staging analytics cluster, a task failed with an EKM (Enterprise Key Management) connectivity timeout. Great.
Error: com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.SdkClientException:
Unable to execute HTTP request: Connect to sts.amazonaws.com:443 failed: connect timed outThe root cause: the original cluster had network routing configured to reach the necessary key management endpoints. The staging analytics cluster, operating in a stricter network segment, did not have equivalent connectivity and correctly so. The failure surfaced a hidden dependency on network topology that wasn’t captured in the job’s configuration.
The fix: We moved search infrastructure tasks to a dev ETL cluster with proper routing to dev services. For tasks requiring production Hive catalogs, we kept them in staging. We also scaled up the dev ETL cluster to handle the additional workload.
Lesson learned: Network topology matters. Like, really matters. Understand network segregation and account boundaries before deciding which cluster runs which jobs. Dev jobs need dev network access, prod jobs need prod network access. The migration revealed hidden dependencies that SSH had been quietly papering over.
Slack operates EMR clusters across 8 independent data regions to support data sovereignty requirements. This meant the SSH deprecation wasn’t a single migration. It was effectively 8 parallel migrations, each with its own special set of challenges. Fun times.
Lesson learned: Multi-region infrastructure significantly multiplies migration complexity. The effort isn’t just N times harder. It’s N times harder with unique failure modes for each region. Budget extra time for cross-region coordination and region-specific debugging. (Seriously, budget more time than you think.)
We achieved 100% SSH elimination. Every production job now runs through Quarry with REST-based submission. Here’s what we gained.
Eliminated SSH access to all production EMR clusters across 8 independent data regions, which massively reduced our attack surface. We replaced SSH key distribution with service-to-service token authentication, and gained proper audit trails through REST API logging. Every job submission now has structured logs through Quarry. No more “who ran that command?” mysteries.
This also enabled completion of our Whitecastle initiative by allowing us to migrate the last AWS main account EMR cluster to a child account. Bonus: we simplified compliance by removing special security group configurations and the complex permission management that SSH access required.
Master node resource contention: eliminated. All non-Hadoop jobs now run in distributed YARN containers with proper resource allocation instead of competing for resources on the master node.
Job reliability: dramatically improved. Jobs survive client Kubernetes pod restarts because Quarry maintains server-side job tracking. No more zombie processes. Jobs terminate properly when cancelled through REST APIs. We gained proper lifecycle management with clean cancellation and cleanup.
Observability: transformed. Structured job status, logs, and metrics are now available through Quarry’s API. We can track jobs across their entire lifecycle, see YARN container logs, and actually debug issues with proper tooling instead of SSH-ing into boxes and hoping for the best.
The REST-based architecture unblocked critical initiatives:
With two years of production experience since completion, the architectural decisions have proven sound. The REST-based approach delivered on its promises: better security, operational stability, and infrastructure flexibility. No regrets.
We wanted to give a shout out to all the people that have contributed to this journey:
Interested in taking on interesting projects, making people’s work lives easier, or just building some pretty cool forms? We’re hiring! 
Continue reading on the original blog to support the author
Read full articleShipyard brings container-like deployment practices to EC2, enabling immutability and automated safety at scale. By treating infrastructure as artifacts, Slack reduces drift and improves security for critical workloads that cannot easily migrate to containers.
This article provides a blueprint for scaling enterprise LLM infrastructure. It details the transition from manual GPU management to managed services, highlighting how to balance security, cost-efficiency, and reliability through strategic multi-cloud orchestration and capacity forecasting.
This article details how to build secure, privacy-preserving enterprise search and AI features. It offers a blueprint for integrating external data without compromising user data, leveraging RAG, federated search, and strict access controls. Essential for engineers building secure data platforms.
Managing context in long-run agentic systems is critical as context windows fill and performance degrades. This architecture shows how to use structured memory and specialized agent roles to maintain coherence and accuracy across complex, multi-step workflows.