This article demonstrates how Pinterest optimizes ad retrieval by strategically using offline ANN to reduce infrastructure costs and improve efficiency for static contexts, complementing real-time online ANN. This is crucial for scaling ad platforms.
Authors (non-ordered): Qishan(Shanna) Zhu, Chen Hu
Acknowledgements: Longyu Zhao, Jacob Gao, Quannan Li, Dinesh Govindaraj
In the evolving landscape of advertising, the demand for real-time personalization and dynamic ad delivery has made Online Approximate Nearest Neighbors (ANN) a mainstream method for ad retrieval. Pinterest primarily employs online ANN to swiftly adapt to users’ behavior changes (depending on their age, location and privacy settings), thereby enhancing ad responsiveness and relevance.
However, offline ANN is also a valuable option, particularly when large-scale data processing, efficient resource utilization, and cost-effective operations are critical. By precomputing candidates offline, this approach is ideal for scenarios that require high throughput and low-latency query responses and relatively static query context. This article explores suitable use cases for offline ANN, outlines its advantages and disadvantages, shares insights from our experiences, and illustrates its application within Pinterest. We will also discuss potential future enhancements.
Pinterest has successfully applied Online ANN to fetch from its large ads inventory, which has brought double digits gains on ads quality metrics across surfaces. However, we are encountering challenges as the ads inventory continuously expands. It is imperative to maintain a neutral impact on online request latency and infra cost.
One potential solution to this issue involves improving the efficiency of the ANN algorithm. We have successfully migrated from the Hierarchical Navigable Small World (HNSW) algorithm to the Inverted File (IVF) algorithm. This transition enables the launch of a larger tier index capable of encompassing more than 10x the number of ads previously accommodated. Nevertheless, the associated cost increase remains a substantial concern, significantly restricting our ability to leverage the expanded inventory integrated into the index.
To address infrastructure costs while enhancing online efficiency, an alternative approach involves utilizing the Offline ANN. This approach benefits from the ample computational resources and latency tolerance available in batch processing environments. Specifically, this method proves most effective and efficient for candidate generators with static query contexts.
The following illustration describes the architecture of online and offline ANN retrieval.
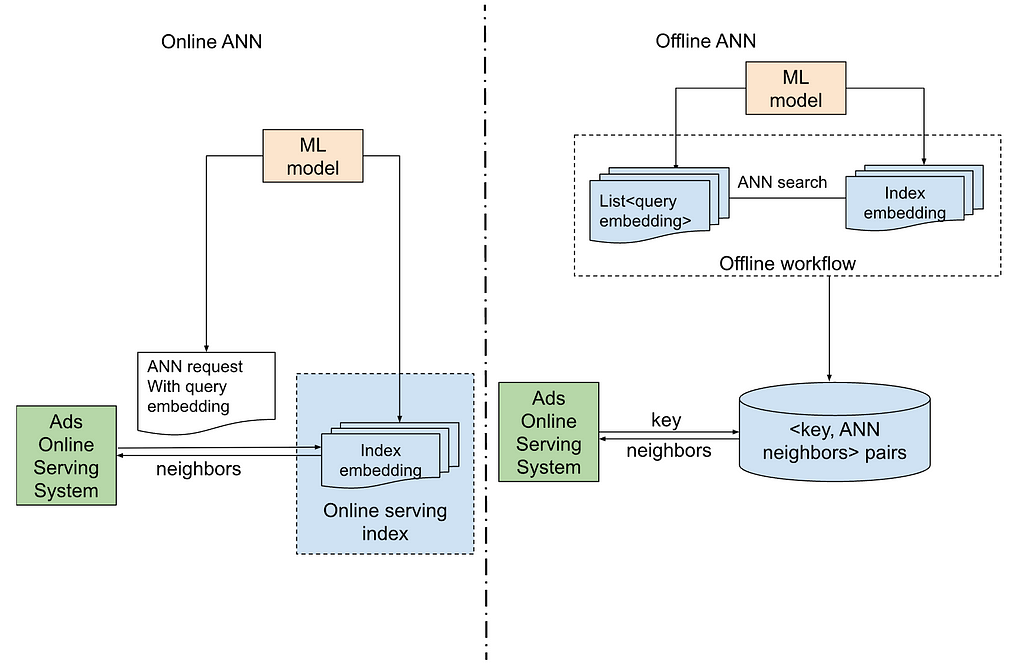
The primary differentiation between the online and offline approaches is determined by the timing of the ANN search. In an online approach, the ANN search is executed in real-time as part of the immediate service. Conversely, in an offline approach, the ANN search is conducted within an offline workflow.
On the left side of online ANN architecture:
On the right side of offline ANN architecture:
Pros of Offline ANN Architecture:
Cons of Offline ANN Architecture:
Given the pros and cons, there are naturally best use-cases for offline ANN architecture and online ANN architecture.
It would be best to use offline ANN architecture:
It would be best to use online ANN architecture:
At Pinterest, we have extensively evaluated offline ANN-based retrieval in several different use-cases. In the next section, we will go over two different use cases.
Context
Advertisers can set up ads to retarget a user’s offsite engaged items on Pinterest (depending on the user’s age, location and privacy settings), which is called dynamic retargeted ads. This type of ad usually shows very high engagement and conversion metrics. To utilize the strong performance of dynamic retargeted ads, we can use ANN to find items that are very similar to offsite engaged items and also show these similar item ads to users. We experimented with both offline ANN and online ANN and will share the implementation and result below.
Implementation
The online ANN version is very similar in architecture. We will go over offline ANN, as an example.
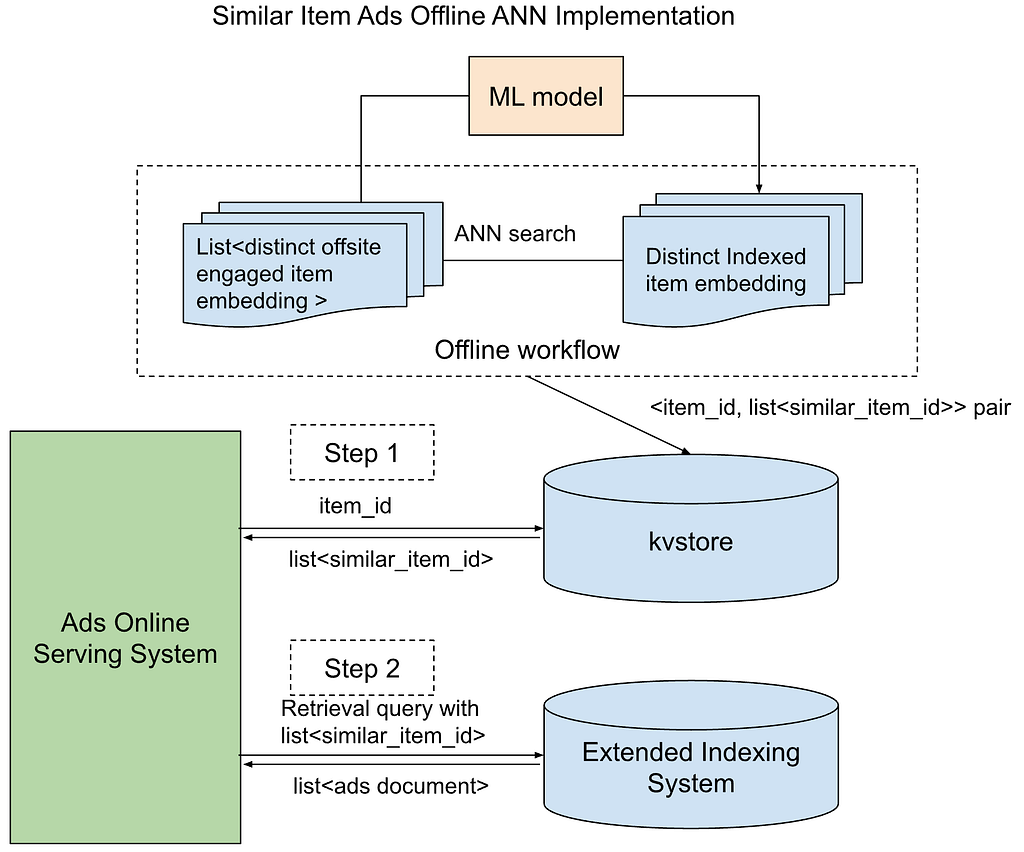
We implemented with two-step retrieval:
Successful Metrics
The experiment result has shown that similar item ads also have high engagement and conversion performance. Compared with the online ANN version, offline ANN version has a much lower infra cost and better engagement and conversion performance.
Limitation & Solution
In offline ANN, the result was initially limited by the number of similar item ads retrieved and was very small, even though we increased the number of similar items per query to up to 50. After targeting, budget, and index size constraints, the number of retrieved ads is small.
We solve that by increasing indexing size. It is very cheap to run each retrieval query for this specific type of ID, so we can easily scale to a much larger index.
Context
To enhance the visual relevance of Pinterest ads, there are a couple of efforts utilized to incorporate visual embedding-based candidate generators across various surfaces and modules. These candidate generators employ the Online ANN approach, which has notably improved the advertisement relevance for their respective surfaces. To address the associated infra costs and facilitate the expansion of visual candidate generators to other surfaces, we are considering the offline approach for the reasons previously outlined.
Implementation
Successful Metrics
The offline ANN method can be seamlessly extended to other interfaces, such as search and home feed, by leveraging the navboost Pin or cached Pin alongside the shared offline workflow.
Furthermore, Pinterest is actively developing its own offline ANN framework and platform, which will facilitate easier and more scalable future advancements. This initiative promises a wealth of new features, including index hyperparameter tuning and recall monitoring, ensuring a robust and adaptable development environment.
Unlocking Efficient Ad Retrieval: Offline Approximate Nearest Neighbors in Pinterest Ads was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleThis approach addresses the common bottleneck where network I/O limits ML serving efficiency. By implementing feature trimming based on model signatures, engineers can maximize GPU utilization and significantly reduce infrastructure costs by moving away from network-optimized instances.
Scaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
Redundant processing of duplicate URLs wastes massive computational resources. This automated, data-driven approach to normalization reduces infrastructure costs and improves data quality by identifying content identity before expensive rendering or ingestion steps occur.