Manual cloud cost optimization fails at scale due to configuration drift and lack of trust. This hybrid AI/deterministic approach automates the last mile of FinOps, turning complex resource tuning into safe, reviewable code changes that significantly reduce infrastructure waste.
By Shan Appajodu and Tuhin Kanti Sharma.
Salesforce faced significant infrastructure challenges while scaling Hyperforce, the platform powering thousands of cloud services. Fragmentation across more than 8,000 Kubernetes-based services led to widespread over-provisioning, with nearly half of managed Kubernetes spend tied to idle capacity. While internal systems identified these inefficiencies, our service owners lacked the visibility and confidence to address them in an environment shaped by years of configuration drift.
The Capacity Optimization Agent solves this by embedding optimization directly into the service owner’s development workflow. The agent analyzes service configurations across repositories, computes optimal resource allocations, and generates pull requests to apply those changes safely. This shifts the process from manual investigation and coordination to a closed-loop agent that does continuous evaluation.
Building this system required us to solve challenges across infrastructure and development workflows. We addressed configuration sprawl and the reasoning limitations of standard LLM agents by developing deterministic optimization that is consistent and safe. This design ensured service owners could trust and safely adopt automated changes at production scale, turning complex optimization into a pull request.
The primary challenge was enabling service owners to act on identified inefficiencies rather than simply finding them. Hyperforce infrastructure grew over years, resulting in configuration sprawl across Helm charts and other configuration files. This complexity meant that even when over-provisioning appeared obvious, service owners struggled to identify where to apply optimizations or how those modifications might propagate.
Traditional methods relied on dashboards that required manual interpretation and implementation. This created uncertainty regarding safety and ownership, which slowed progress. We solved this by shifting focus from delivering insights to executing changes.
The agent now generates pull requests that modify the specific configuration files responsible for capacity allocation. These automated updates remain environment-aware and align with established deployment patterns. By utilizing the pull request model, service owners review precise changes instead of investigating system behavior. This transformation turns capacity optimization into a repeatable, agent-driven workflow that scales across thousands of services.
In our initial iterations, we built a simple agent for automated optimization, but these early versions produced non-deterministic results on our infrastructure. The large language models could not reason against fragmented service configurations sprawled across multiple repositories and Helm charts.
Non-deterministic outputs further reduced trust, as identical configurations often produced different results. Additionally, these models struggled with global optimization because capacity decisions require simultaneous evaluation of multiple constraints, whereas model reasoning remained localized.
We resolved these issues by narrowing the role of the LLM. It now handles repository discovery, configuration parsing, and context extraction. Meanwhile, a deterministic algorithm manages all optimization decisions.
This architecture creates a clear separation between probabilistic reasoning and deterministic computation. The model navigates the infrastructure while downstream systems perform optimization. By limiting the model to specific responsibilities, the system improves reliability and expands coverage across our complex services.
Providing accurate and globally optimal decisions became our priority after redefining the role of the model. Since large language models are probabilistic, they produce inconsistent capacity optimization plans for the same configurations.
We replaced the model-driven planning layer with a deterministic optimization engine to ensure correctness. The new multi-stage pipeline uses AI for repository discovery and configuration parsing, while a dedicated planning layer calculates the optimal configuration. An Integer Linear Programming solver sits at the core to minimize resource waste across all containers.
A preprocessing layer now maps configuration relationships and identifies control points. Structured schemas enforce strict contracts between stages, replacing free-form text. Isolated execution logic ensures the system applies plans exactly as intended. These changes created a deterministic engine that produces verifiable results across thousands of services.
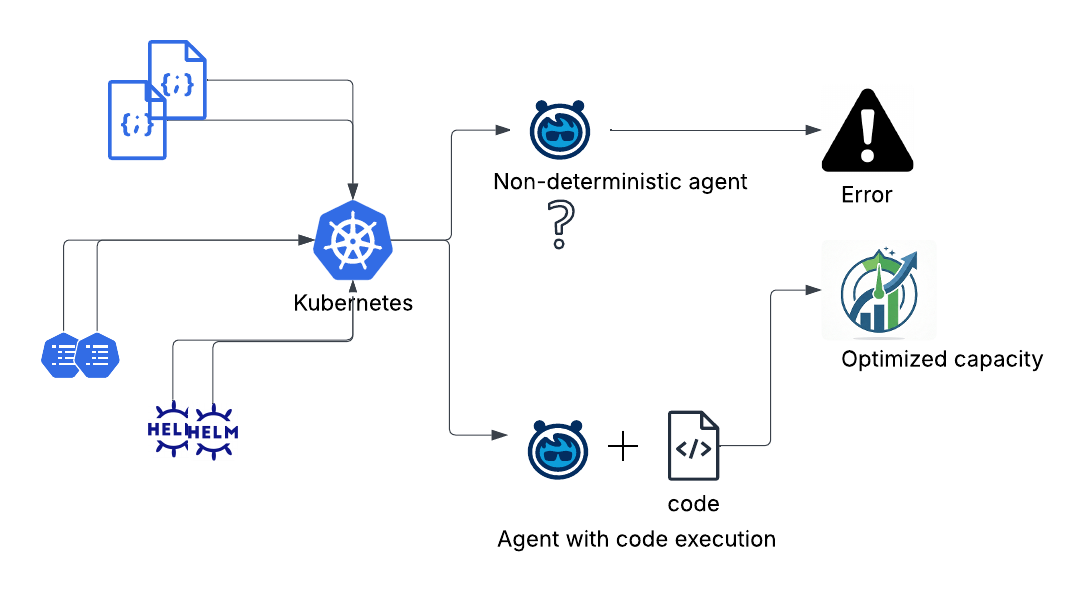
Agents can be made deterministic if paired with code execution
Adoption creates a challenge centered on trust when AI agents generate pull requests across thousands of repositories. Service owners require a clear understanding of changes before they approve them for production.
We redesigned the presentation and validation of optimizations to build confidence. Each pull request now includes clear explanations, projected impacts, and supporting context. Visualization tools demonstrate how configuration updates affect system behavior.
Multiple layers enforce safety throughout the process. The agent modifies only Kubernetes CPU requests and leaves CPU limits untouched to maintain scaling headroom. All changes move through existing deployment pipelines, which include validation and staged rollouts. This transparency and control allow service owners to apply changes safely across production environments.
The next phase focuses on expanding coverage and capability across other configurations. Support for multi-repository environments will allow agents to reach services outside standardized paths, even as distributed configurations add complexity to discovery and coordination.
Optimization efforts now include memory utilization and Horizontal Pod Autoscaler (HPA) configurations alongside CPU. These additions require enhancements to the deterministic planning layer to manage the increased complexity.
Scaling adoption remains a priority for the team. Improved visualization, feedback loops, and post-deployment validation help trust grow alongside automation. These expansions will move the system closer to delivering continuous efficiency gains across the entire Hyperforce infrastructure.
The agent fundamentally changes infrastructure management by replacing manual, periodic analysis with continuous, automated decision-making. This approach embeds intelligence directly into the development lifecycle to ensure efficiency happens by design rather than by accident.
AI drives the discovery of optimization opportunities, while deterministic planning provides the necessary guardrails for accuracy, safety, and consistency. This synergy moves the organization away from reactive fixes toward a model where systems optimize themselves in real time.
As these capabilities evolve, infrastructure optimization becomes a permanent, always-on feature of the environment. The focus now shifts toward scaling these processes safely and transparently to maintain the trust of the engineers who manage these complex systems every day.
The post How AI-Driven Kubernetes Optimization Reclaimed Millions from 47% Idle Capacity appeared first on Salesforce Engineering Blog.
Continue reading on the original blog to support the author
Read full articleTransitioning AI agents from demos to production requires a shift from prompt engineering to system engineering. This article highlights how to handle non-deterministic tasks in critical infrastructure, ensuring agents can safely automate complex cloud optimization worth millions.
Benchmarking AI systems against live providers is expensive and noisy. This mock service provides a deterministic, cost-effective way to validate performance and reliability at scale, allowing engineers to iterate faster without financial friction or external latency fluctuations.
Moving AI to production requires shifting focus from prompting to distributed systems reliability. Durable workflows ensure that long-running tasks can recover from failures without duplicating expensive work or losing state, which is essential for enterprise-scale applications.
Automating build failure analysis reduces developer downtime and scales support expertise without increasing headcount. By using AI to distinguish between infra, app, and external platform issues, teams can resolve incidents 60% faster and focus on proactive infrastructure health.