Managing shared infrastructure limits is critical when scaling LLM applications. This architecture demonstrates how to balance high-volume autonomous agents with human-in-the-loop workflows, ensuring fairness and prioritizing high-value tasks without hitting rate-limit failures.
By Karthik Premnath, Arie Kusnadi, and Felix Yu.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Karthik Premnath, a lead software engineer on the Agentforce Sales Engagement team that engineered a distributed persistent queue that orchestrates AI workloads and human workflows within strict infrastructure limits to help customers scale outreach to over 10,000 leads daily.
Explore how Karthik and his team designed a persistent queue that prevents autonomous agents and human workflows from overwhelming shared capacity while using a priority orchestration system to ensure high-value reply emails are dispatched before lower-value outreach.
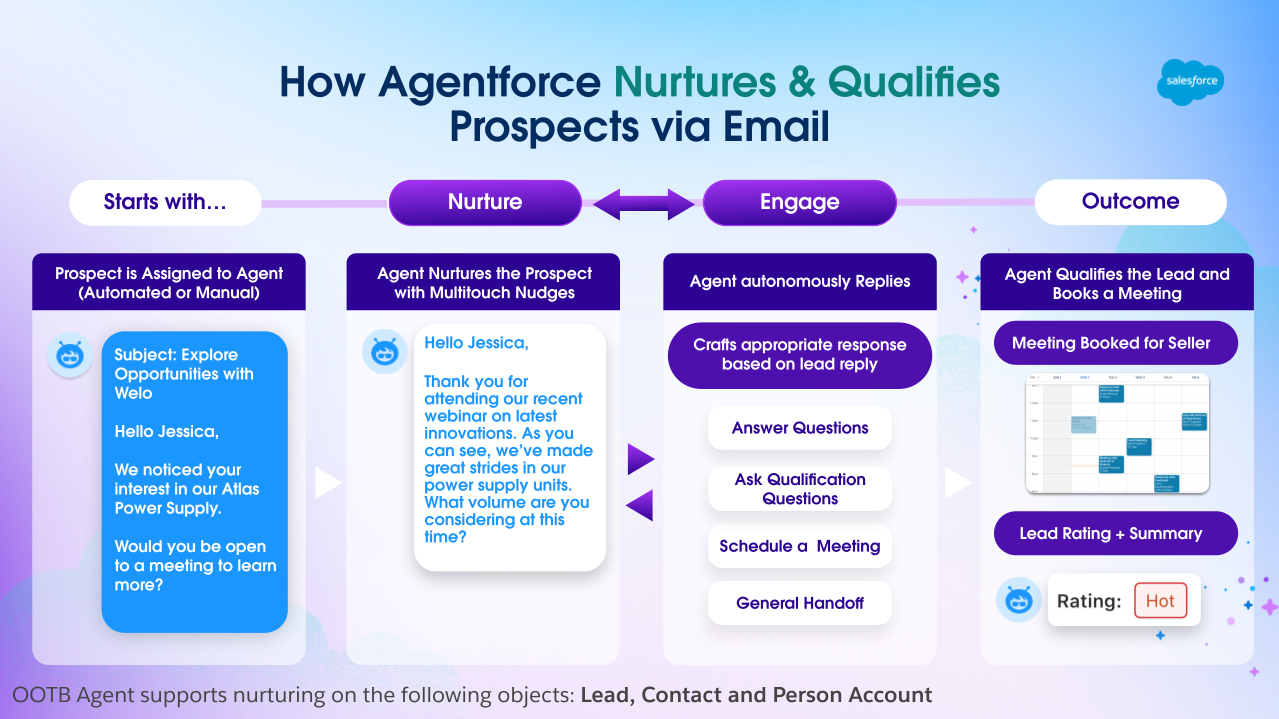
Agent workflow: Automated nurture, intelligent engagement, qualified meetings
Our mission involves enabling Agentforce Lead Nurturing Agent to operate at enterprise scale while respecting the infrastructure limits of shared LLM capacity. Because customers often assign thousands of leads simultaneously, the system requires orchestration to prevent requests from overwhelming the gateway and triggering failures.
To solve this, the team built a persistent queue that acts as an orchestration layer between customer workflows and the infrastructure. Instead of executing outreaches immediately, this queue determines exactly when work can safely run while remaining within system limits.
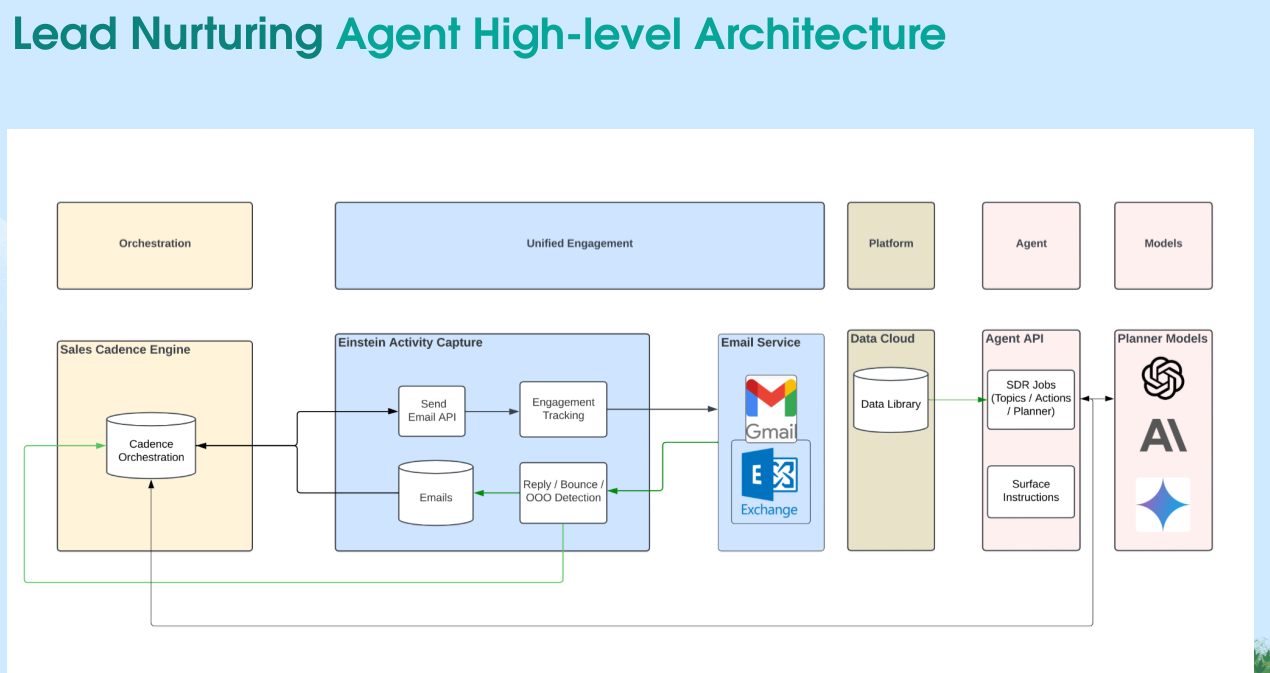
This architecture allows the platform to coordinate AI agents and human workflows in a unified system that preserves reliability and fairness. Consequently, customers can assign large volumes of outreach without calculating throughput because the queue continuously regulates dispatch across all execution contexts.
AI agents and human sellers operate with different capacity characteristics while sharing the same LLM infrastructure limits. AI agents typically have higher daily throughput, whereas human workflows have varying daily email limits and operating hours restrictions. Both are subject to the same 300 RPM LLM limit and email provider constraints, so one group could easily consume most of the available capacity without proper orchestration.
The queue resolves this contention by using a fair-share distribution allocation mechanism. The system groups work by execution context, such as AI agents by bot user or workflows by owner, and the dispatcher iterates across these groups using a round-robin strategy.
Each cycle pulls one outreach from each context until the system fills the dispatch capacity. This approach ensures that neither agents nor human workflows monopolize the available resources, which allows the system to maintain balanced throughput for both workloads.
Not all outreach carries the same business value. Reply emails from engaged prospects represent active conversations, whereas introductory or nudge emails serve as lower-priority. When the system treats all work equally, lower-value outreaches can consume capacity and delay high-value replies.
The team addressed this by implementing a three-tier priority queue with dynamic slot allocation. Reply emails receive the highest priority, followed by introductory outreach and nudge emails.
To maintain efficiency, the queue also uses an adaptive backfill mechanism. The system queries each priority level once. If higher-priority outreaches do not fully occupy the dispatch capacity, the queue fills the remaining slots with work from lower-priority tiers using previously retrieved results. This ensures reply-first dispatch while maintaining 100% slot utilization and system throughput.
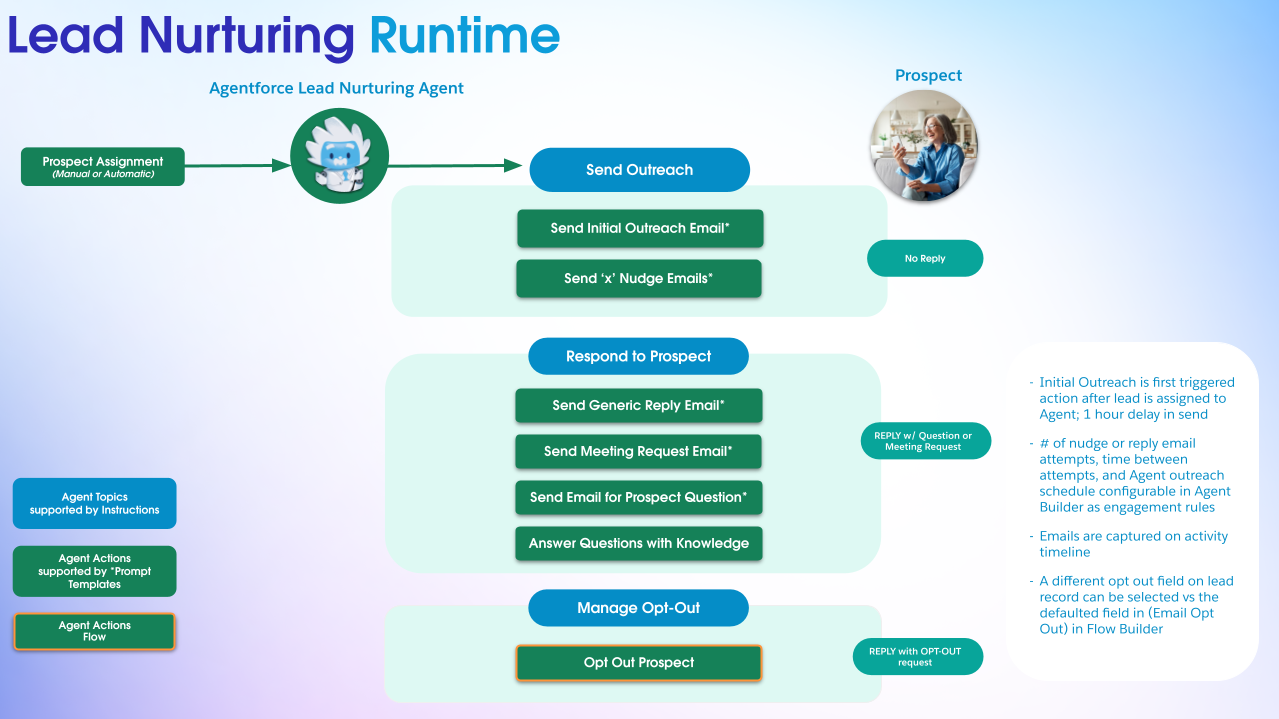
Lead Nurturing runtime with multi-touch orchestration.
Some organizations require human review before sending AI-generated emails. This creates a risk where emails awaiting approval accumulate and compete with autonomous agents for dispatch capacity. Without coordination, one workflow could dominate the system and block the other. Both AI agents and human workflows can operate under review-required configurations, adding complexity to fair distribution.
The queue resolves this by separating execution paths while maintaining shared infrastructure. Autonomous workloads follow the standard generation and dispatch pipeline, subject to capacity checks including daily email limits and operating hours, then dispatched immediately to the LLM for generation. Emails requiring review move through a separate path since generation already occurred during the drafting phase.
Before scheduling approved emails, the system evaluates each owner’s capacity constraints: daily email limits and operating hours. If an owner has no available capacity, the system sets to defer their work to the next dispatch cycle. This ensures both workflows operate efficiently without blocking one another.
The most significant reliability risk involves breaking multi-step conversations. When a prospect replies to an outreach email, failing to respond due to rate-limit violations disrupts the engagement and risks the opportunity.
Earlier push-based approaches attempted to retry failed requests. These retries competed with new work and created cascading failures as the system struggled to recover while processing incoming tasks.
The queue addresses this through adaptive rate modulation with proactive capacity-based admission control. Before dispatching work, the system checks real-time usage for the organization and adjusts dispatch volume. If usage approaches the infrastructure limit, the system dispatches fewer tasks during that cycle. This prevents rate-limit violations and ensures higher-priority tasks execute first.
System throughput constraints originate from underlying request limits. Each lead engagement requires multiple LLM calls, including planning, context generation, and message creation. These steps collectively consume several requests.
Lead throughput must align with available capacity. Without careful orchestration, large batches of outreach could exceed limits and trigger failures. The queue maximizes safe throughput by distributing work across multiple execution contexts through per-user capacity tracking and removing inefficiencies in the dispatch pipeline.
Simplified query patterns provide constant-time database access. This removes scaling bottlenecks and allows the dispatcher to operate predictably regardless of queue size. These improvements increased throughput 5x while respecting infrastructure limits. Customers with multiple agents and sellers can now assign and process significantly larger outreach volumes.
Compliance-sensitive industries require human approval before sending communications. This introduces latency that conflicts with the responsiveness of autonomous agents.
The team designed a dual-path queue architecture to solve this. In the human-review path, the system drafts the message and stores it in a queued state. Once a human approves the email, the queue queries approved emails separately and schedules delivery. This removes the need for another generation step, so approved emails don’t consume current LLM capacity
Fully autonomous workflows use the standard dispatch path. The system generates and sends these messages immediately within operational limits.
Separating these execution paths allows compliance-driven workflows and autonomous agents to operate simultaneously.
This shared infrastructure prevents performance degradation across the system.
The post Building a Distributed Persistent Queue That Scaled AI Workloads 5x Under LLM Rate Limits appeared first on Salesforce Engineering Blog.
Continue reading on the original blog to support the author
Read full articleMoving AI to production requires shifting focus from prompting to distributed systems reliability. Durable workflows ensure that long-running tasks can recover from failures without duplicating expensive work or losing state, which is essential for enterprise-scale applications.
Unified Planner demonstrates how to solve fragmentation and latency in complex AI architectures. By unifying runtimes and implementing parallel execution, Salesforce achieved a 9x performance gain, offering a blueprint for building scalable, multi-modal AI execution engines.
This article provides a blueprint for scaling AI infrastructure by moving from a monolith to a multi-tenant platform. It demonstrates how to maintain low latency and engineering velocity while managing complex state and resource isolation for hundreds of developers.
Scaling AI globally requires automated infrastructure to manage model availability. This approach ensures high reliability and compliance with data residency laws while slashing operational overhead, allowing teams to adopt new LLMs rapidly without manual configuration risks.