Scaling AI globally requires automated infrastructure to manage model availability. This approach ensures high reliability and compliance with data residency laws while slashing operational overhead, allowing teams to adopt new LLMs rapidly without manual configuration risks.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Scott Chang, Principal Engineer on the AI Infrastructure team, who builds the robust, secure, and resilient core that drives Agentforce 360.
Scaling Agentforce across a vast global network of AWS accounts and regions turned model tracking and routing into a complex puzzle. This insightful Q&A explains how Salesforce’s automated solution slashed Amazon Bedrock discovery times from three days to mere minutes. Explore how Scott and his team leveraged AWS APIs for instant endpoint detection, removing manual hurdles and strengthening compliance through dependable fallback routing.
The team’s core mission involves delivering stable, resilient, and secure infrastructure for the AI services behind Agentforce 360, with a sharp focus on operational excellence. As workloads powered by large language models (LLMs) expand and these models rapidly evolve, the reliability of the underlying infrastructure directly impacts the customer experience. Consequently, it is crucial to ensure model routing, availability, and fallback behaviors remain predictable and safe under all operating conditions.
The Bedrock Model Availability capability emerged directly from improving operational excellence. Instead of treating model routing as mere manual configuration data, the team developed it as an infrastructure capability that required automation, observability, and guardrails. The outcome is a robust foundation that enhances resilience, minimizes operational risk, and allows Agentforce to quickly adopt new models without compromising correctness or compliance.
Agentforce utilizes a multi-account AWS architecture to maintain regional separation, satisfy data residency requirements, and manage quotas. Global expansion pushed the platform to over 30 AWS accounts across various territories. Every account needs specific routing setups for foundation models, which makes managing availability a massive undertaking.
At the same time, Agentforce enters new regions while model providers launch fresh options at a rapid pace. These models often debut in specific hubs like Oregon or Virginia before a wider rollout. Each model offers different inference profiles, such as in-region or global endpoints, which change as capacity shifts. Relying on manual tracking across this multi-account landscape became impossible.
Engineers previously spent hours finding models, checking profiles, and updating complex routing configurations for every release. The team solved this by building an automated system that gathers availability data through three AWS APIs.
Regional AWS Lambda functions collect this data and share it as CloudWatch custom metrics. These insights feed into internal monitoring tools and a single Grafana dashboard. Engineers now identify active model endpoints by region and ID in real time. This innovation cuts discovery time from days to minutes.
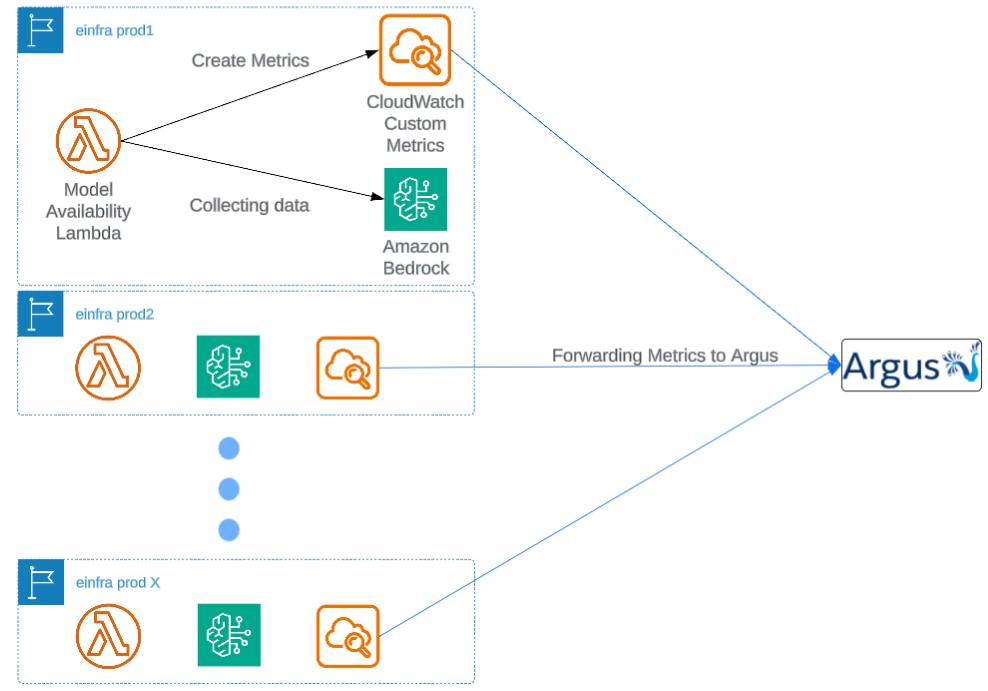
Lambda in each region collects data as customer metrics.
As model availability data gains complexity, correctness becomes a primary concern. Deploying incorrect endpoints can route inference traffic to unexpected regions or non-existent endpoints, leading to increased latency or service outages. Beyond availability issues, incorrect routing also creates compliance risks, especially for customers with strict data residency requirements that mandate data remain within specific regions or countries.
To prevent these failures from escalating into customer-visible incidents, the team collaborated with the team providing a gateway to external LLM providers to implement a deterministic baseline fallback mechanism. This mechanism establishes a set of verified, critical regions — such as Virginia, Oregon, or Frankfurt — that consistently offer available Bedrock capacity.
When a primary endpoint returns HTTP errors or becomes unavailable, the system automatically reroutes traffic to this baseline configuration. By separating primary routing logic from last-resort fallback behavior, the system ensures that incorrect or outdated configuration data cannot cause prolonged outages, significantly enhancing correctness and reliability under real-world operating conditions.
Cross-region routing presents a nuanced challenge. While network latency is a minor concern compared to overall LLM inference time, the real risks surface at the system level, particularly in capacity management. Directing traffic to unintended regions can create unexpected load, straining existing production capacity.
Data residency requirements further complicate matters. Many clients demand that inference traffic remains within specific jurisdictions. Routing European traffic outside the EU or sending APAC traffic across country boundaries risks violating compliance and raising security concerns.
The system tackles these limitations with layered routing controls. AWS-managed inference profiles offer in-region, in-country, and global failover options for capacity constraints. Concurrently, LLM Gateway employs its own failover logic, detecting error signals and rerouting traffic to predefined backup endpoints. These combined mechanisms ensure routing decisions simultaneously honor latency, capacity, data residency, and availability.
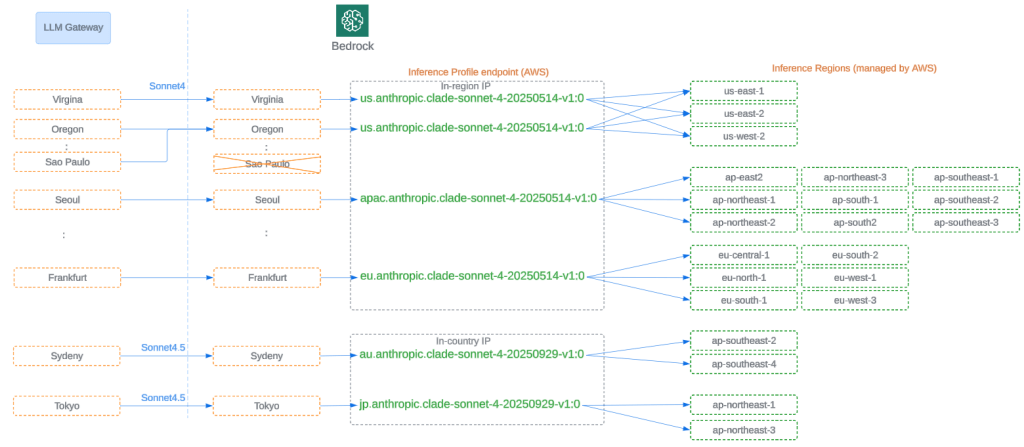
Model Routing integrated with Inference Profile increased resiliency.
Before automation, routing updates w ere a cumbersome, multi-step manual process. Discovering model availability, identifying endpoints, updating configurations, creating pull requests, and redeploying services all introduced delays and potential for errors. This extended onboarding timelines significantly, often over several days.
The Bedrock Model Availability capability has since removed these bottlenecks. The team now automatically collects, normalizes, and exposes all routing-critical data. Initially, this information is visible via a Grafana dashboard, offering a unified, real-time view of model availability across regions.
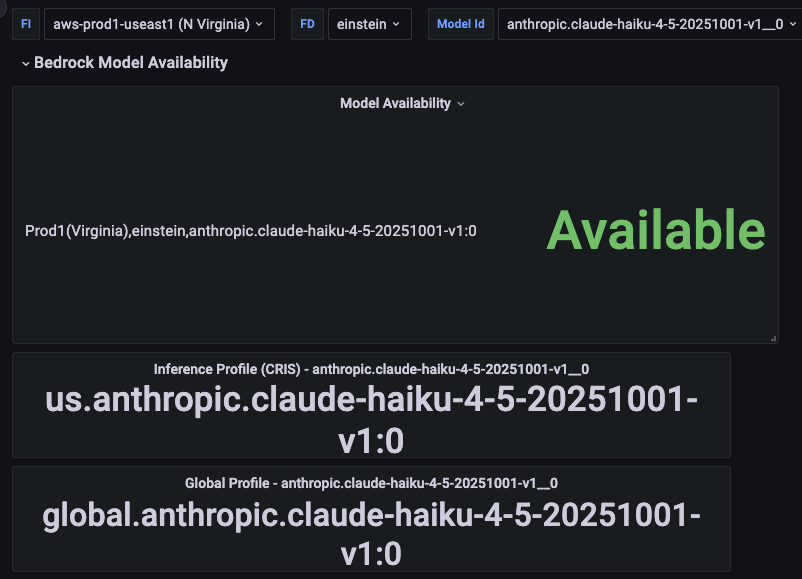
A single-pane-of-glass dashboard reduced operational time from days to minutes.
This change drastically cut model availability discovery time, from about three days to under ten minutes. The future promises full automation, completely eliminating routing configuration delays. What once took up to seven days, from discovery to deployment, will become effectively instantaneous, with dynamic updates propagating automatically at the service level. This transforms routing from a manual operational task into a scalable infrastructure capability, evolving at Agentforce’s own pace.
The post Building AWS Bedrock Model Availability: Slashing AI Routing Discovery From Days to Minutes appeared first on Salesforce Engineering Blog.
Continue reading on the original blog to support the author
Read full articleMoving AI to production requires shifting focus from prompting to distributed systems reliability. Durable workflows ensure that long-running tasks can recover from failures without duplicating expensive work or losing state, which is essential for enterprise-scale applications.
Unified Planner demonstrates how to solve fragmentation and latency in complex AI architectures. By unifying runtimes and implementing parallel execution, Salesforce achieved a 9x performance gain, offering a blueprint for building scalable, multi-modal AI execution engines.
This article provides a blueprint for scaling AI infrastructure by moving from a monolith to a multi-tenant platform. It demonstrates how to maintain low latency and engineering velocity while managing complex state and resource isolation for hundreds of developers.
Managing shared infrastructure limits is critical when scaling LLM applications. This architecture demonstrates how to balance high-volume autonomous agents with human-in-the-loop workflows, ensuring fairness and prioritizing high-value tasks without hitting rate-limit failures.