Securing AI agents at scale requires balancing rapid innovation with enterprise-grade protection. This architecture demonstrates how to manage 11M+ daily calls by decoupling security layers, ensuring multi-tenant reliability, and maintaining request integrity across distributed systems.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today we meet Sahil Sobti, Lead Software Engineer on the Developer Access team, who builds and operates the access layer safeguarding Agentforce, directly managing over 11 million daily agent calls across production environments.
Explore how the team defined clear protection boundaries as Agentforce expanded, designed a layered access-control plane enforcing identity, authorization, and request integrity at scale, and contained multi-tenant blast radius to prevent failures or misuse from cascading across the platform.
Our mission empowers builders to integrate seamlessly with the Agentforce platform, ensuring every agent interaction remains secure, reliable, and enterprise-ready. The Developer Access team manages the access plane fronting Agent Runtime, Agent Preview, and Agent Authoring APIs, placing us directly in the path of all agentic traffic.
This position carries a clear responsibility: we make it easy for customers to build and operate agents without exposing sensitive data or introducing new attack surfaces. Agents encapsulate customer prompts, configurations, and data models, therefore protection must meet the same standard as any other Salesforce customer data, without exception.
Simultaneously, the platform must evolve quickly. We design the access layer to support new agent capabilities and interoperability while preserving consistent security and reliability. Our goal extends beyond simply blocking undesirable traffic; we aim to provide a stable foundation that allows Agentforce to grow safely as adoption and complexity increase.
Sahil shares what keeps him at Salesforce.
Operating as the middle layer demands explicit ownership of responsibility boundaries. Within Salesforce, core services represent established platform systems enforcing identity, data access, and security guarantees. By contrast, the distributed compute layer comprises newer, rapidly evolving systems; because these extend the platform, they require an equivalent — if not higher — level of protection.
This distinction holds significance because Agentforce spans both environments. Any request to execute an agent need protection through organization and user-level permissions, anchoring authorization decisions in the core platform as the source of truth. Simultaneously, enabling new agent functionality requires coordinating multiple, independently moving teams through a single access layer. Any uncoordinated contract change directly impacts customers.
Due to this coupling, the access layer functions as both a technical and organizational control point. Architecturally, services within the distributed compute layer cannot bypass it, making Agent APIs the sole entry path for Agentforce AI Agents and ensuring consistent enforcement as the platform evolves.
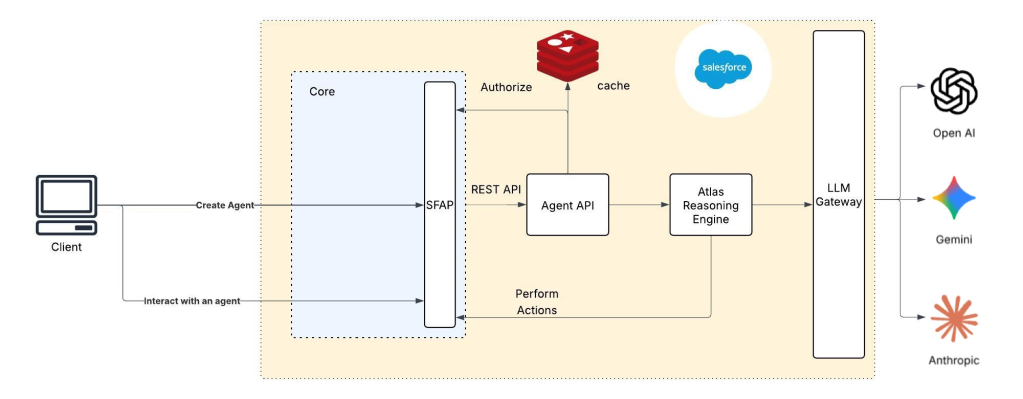
High-level design of a scalable and secure Agentforce Platform.
Protecting agent data required treating access control as a unified plane. The core challenge involved distributing authentication, authorization, and request validation across layers, meeting latency, scalability, and operational ownership needs.
We intentionally separated responsibilities across platform boundaries instead of centralizing all controls. This approach filters unauthenticated traffic early, preserves the core platform as the authoritative source for organizational and user-level permissions, and avoids forcing every backend service to independently manage trust and identity. This separation ensures consistent security decisions while reducing duplication and operational risk as Agentforce grows.
The access-control plane enforces three non-negotiable invariants:
This layered approach ensures only approved actors perform approved operations, without requiring each backend service to reimplement security controls.
Sahil explains the culture within Salesforce Engineering.
Agentforce operates as a shared, multi-tenant platform. This means a single misbehaving tenant, runaway agent, or malformed request pattern potentially degrades service for many customers simultaneously. As agent adoption grows and execution becomes more autonomous, blast-radius containment becomes a primary design concern, not an operational afterthought.
The team collaborates with product partners to understand expected usage patterns, including agent limits per org and anticipated request rates. These inputs, together with production monitoring of adoption trends, drive capacity planning.
Blast-radius containment is enforced through a combination of controls:
By enforcing isolation at the org level and designing for fairness from the start, the platform prevents localized issues from propagating across the broader Agentforce ecosystem.
Sahil spotlights why engineers should join Salesforce.
Operating Agentforce demands visibility into ephemeral interactions without adding latency or operational burden. Every agent interaction creates transient states that require observation for debugging, support, and reliability analysis. Without explicit tracking, attributing failures becomes difficult and reproducing them is nearly impossible.
To address this, the team introduced session-based tracking, leveraging a high-performance, in-memory distributed data store. Sessions are created for each interaction with minimal latency. Time-to-live semantics ensure automatic cleanup of abandoned sessions. This session layer forms the foundation for observability during both design-time testing and live traffic.
With that foundation established, service health is monitored through synthetic tests. These tests run on a fixed cadence to validate availability and performance, with results funneling into real-time telemetry and visualization suites, including shared Tableau dashboards. Production traffic currently exceeds 11 million agent calls daily, with peak periods reaching tens of thousands of requests per minute. This volume reinforces the necessity for continuous, automated monitoring.
The post How Agentforce Runs Secure AI Agents at 11 Million Calls Per Day appeared first on Salesforce Engineering Blog.
Continue reading on the original blog to support the author
Read full articleFor global-scale perimeter services, traditional sequential rollbacks are too slow. This architecture demonstrates how to achieve 10-minute global recovery through warm-standby blue-green deployments and synchronized autoscaling, ensuring high availability for trillions of requests.
Moving AI to production requires shifting focus from prompting to distributed systems reliability. Durable workflows ensure that long-running tasks can recover from failures without duplicating expensive work or losing state, which is essential for enterprise-scale applications.
Engineers must move beyond simple request-response wrappers to build reliable AI. This architecture shows how to combine the reasoning power of LLMs with the structural integrity of stateful orchestration, ensuring enterprise workflows are both flexible and auditably correct.
Unified Planner demonstrates how to solve fragmentation and latency in complex AI architectures. By unifying runtimes and implementing parallel execution, Salesforce achieved a 9x performance gain, offering a blueprint for building scalable, multi-modal AI execution engines.