Automating large-scale infrastructure migrations is critical for reducing operational risk. MIPS demonstrates how to build a deterministic decision engine that maintains auditability and customer trust while scaling to handle tens of thousands of complex organization moves.
By Raksha Subramanyam and Vijay Singh.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we feature an internal decision and automation platform, the Migration Intake and Processing Service (MIPS). Engineers on the Cloud Economics and Capacity Management and Org Migration teams came together to build this platform, which enables Salesforce’s large-scale customer organization (org) migrations to Hyperforce, processing over 95,000 organization migrations through more than 15,000 requests over a span of ~1 year.
Explore how the team replaced manual migration intake with an automated decision engine, architected reliable integration across multiple sources of truth while preserving auditability and customer trust, and balanced auto-approval with human intervention to maintain predictable throughput for 90%+ of the org migration requests managed through the automated system.
Our team enables Salesforce to migrate customer organizations to Hyperforce at an enterprise scale. We achieve this while meticulously honoring customer constraints and preferences, all without introducing operational risk or human throughput bottlenecks.
As Salesforce transitioned from first-party data centers to public cloud infrastructure, the nature of migration planning evolved significantly. What was once a small set of coordinated moves transformed into a high-volume program. Each request carries real, critical customer preferences including destination region, scheduling windows and respects customer constraints.
To address this new scale, the team developed the Migration Intake and Processing Service, or MIPS. This platform acts as a centralized decision and automation layer. It transforms migration requests into deterministic outcomes, empowering downstream execution teams to act with confidence. Rather than relying on spreadsheets managed by humans and manual coordination across various systems and teams, MIPS establishes a single, auditable intake path with clear routing instructions. It automates standard cases and escalates exceptions for review, allowing the program to scale efficiently without compromising accuracy, speed or customer trust.
In the initial phases of Hyperforce migrations, manual coordination proved manageable. This was largely due to the low migration volume, which allowed for communication through email, Slack, and spreadsheets. Salesforce manually validated each request, meticulously checking eligibility, schedulability, regional capacity, and legal requirements across various dashboards and data sources.
However, as migration volumes rapidly escalated into thousands of organizations per month, this manual approach quickly became a significant bottleneck. Each request demanded multiple validations, and performing these checks by hand led to delays, inconsistencies, and growing backlogs. Even minor data inaccuracies could result in incorrect migration decisions.
The primary limiting factor wasn’t data movement itself, but rather the speed of request processing. Without automation, the intake layer severely constrained the entire migration program. MIPS directly addressed this challenge by embedding validation logic into the system. This eliminated the need for human intervention in repetitive checks, allowing intake throughput to scale independently of staffing levels.
The core architectural challenge centered on consolidating numerous distributed sources of truth into one reliable decision engine. Migration eligibility, scheduling windows, capacity limitations, and policy rules resided with various teams and within disparate systems. MIPS had to read from and write to these systems, ensuring every decision relied on accurate, current data.
Misinterpretations could lead to migrating an organization to an incorrect region or scheduling a move at an invalid time, creating substantial customer and operational risks. To counter this, the team heavily invested in upfront architecture and functional design. This involved meticulously documenting dependencies, update paths, and ownership boundaries across systems.
To support deterministic decision-making, MIPS evaluates requests against a fixed set of validated inputs. These include:
The resulting architecture utilizes well-defined APIs, explicit data contracts, and continuous data quality checks. MIPS validates inputs across multiple dimensions before approving a request. It defaults to manual review when required data is missing or inconsistent, enabling autonomous operation at scale without compromising precision.
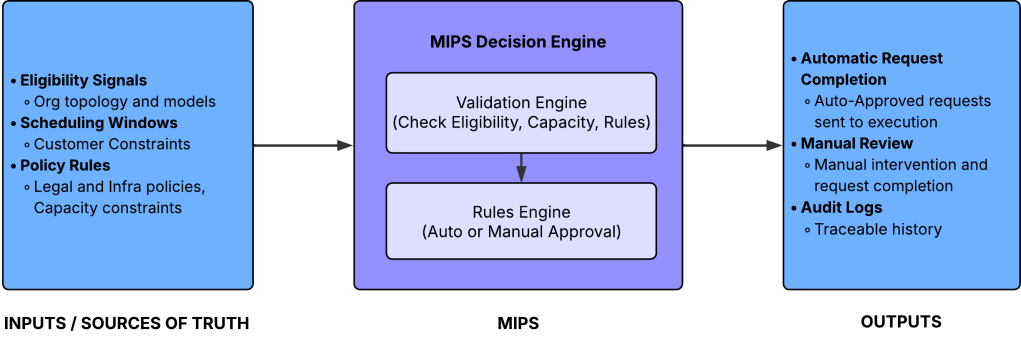
Reliability and auditability formed the bedrock of the MIPS system, given its direct impact on customer data residency and availability. Every approval or rejection is traceable, allowing engineers to manually pinpoint the exact decision-making process if downstream issues emerged. Traceability of our requirements is critical to ensuring our number one value, trust, is met at all times.
The team tackled this by constructing auditable decision pipelines that capture:
This allows engineers to backtrack through decisions when validating behavior or investigating anomalies.
Another significant risk was partial data availability. Instead of inferring or guessing, MIPS was engineered for safe failure. If any required source of truth becomes unavailable or yields unexpected results, the system automatically routes the request for human review. This conservative strategy prevents incorrect automated decisions and safeguards customer trust, ensuring automation never compromises correctness as migration volume grows.
Timeline pressure to complete most Hyperforce migrations forced the team to carefully select what they could safely automate early on. The goal was not complete automation, but rather high-impact automation without escalating risk.
The team analyzed manual validation steps performed by humans. They separated deterministic, policy-driven checks from those needing human judgment. Eligibility, schedulability, and capacity validations proved reliably automatable, unlike legal verification and certain exception scenarios.
MIPS directly incorporates this distinction into its rules engine. Requests meeting all deterministic criteria receive auto-approval and propagate downstream. Other requests are flagged with explicit reasons and routed for manual review. This method automated approximately 80% of requests, substantially reducing the backlog while retaining human involvement where judgment is necessary. The remaining 20% guides future automation opportunities.
Throughput at scale depended as much on data freshness as on request volume. Each migration request initiates multiple validations across eligibility, location, and capacity data. Synchronous lookups for every request would introduce unacceptable latency.
To address this, the team separated data freshness from request processing. Background jobs continuously refresh commonly used datasets on a fixed cadence. This ensures fast access to validated data when requests arrive. This approach reduced reliance on real-time calls and enabled consistent decision latency as volume increased.
Some constraints remained due to upstream system limitations. In those instances, the team defined clear service-level expectations and communicated them explicitly, rather than obscuring the limitations. By combining precomputed data, conservative defaults, and clear service level objectives, MIPS maintains predictable throughput while safely supporting 90%+ of the org migration requests managed through the automated system.
The post Hyperforce Migration at Scale: How Deterministic Automation Replaced Manual Spreadsheets Across 95,000 Organizations appeared first on Salesforce Engineering Blog.
Continue reading on the original blog to support the author
Read full articleThis article demonstrates how to build a resilient distributed system that handles extreme scale and unpredictable customer data models. It provides a blueprint for managing metadata bottlenecks and resource allocation when processing quadrillions of records across disparate storage systems.
This migration provides a blueprint for modernizing stateful infrastructure at massive scale. It demonstrates how to achieve engine-level transitions without downtime or application changes while maintaining sub-millisecond performance and high availability.
Scaling to 100,000+ tenants requires overcoming cloud provider networking limits. This migration demonstrates how to bypass AWS IP ceilings using prefix delegation and custom observability without downtime, ensuring infrastructure doesn't bottleneck hyperscale data growth.
Moving AI to production requires shifting focus from prompting to distributed systems reliability. Durable workflows ensure that long-running tasks can recover from failures without duplicating expensive work or losing state, which is essential for enterprise-scale applications.