Scaling recommendation systems to LLM-scale is often cost-prohibitive. Meta's approach demonstrates how co-designing hardware and software with intelligent request routing can break the inference trilemma, delivering high-performance AI at global scale with industry-leading efficiency.
0Meta continues to lead the industry in utilizing groundbreaking AI Recommendation Systems (RecSys) to deliver better experiences for people, and better results for advertisers. To reach the next frontier of performance, we are scaling Meta’s Ads Recommender runtime models to LLM-scale & complexity to further a deeper understanding of people’s interests and intent.
This increase in scale & complexity exacerbates a fundamental “inference trilemma”: the challenge of balancing the increased model complexity and associated need for compute and memory with the low latency and cost efficiency required for a global service serving billions of people. To overcome this, we have developed the Meta Adaptive Ranking Model, which effectively bends the inference scaling curve with high ROI and industry-leading efficiency.
Adaptive Ranking Model replaces a “one-size-fits-all” inference approach with intelligent request routing. By dynamically aligning model complexity with a rich understanding of a person’s context and intent, the system ensures every request is served by the most effective & efficient model. This allows Meta Ads to maintain the strict, sub-second latency the platform depends on while providing a high-quality experience for every person.
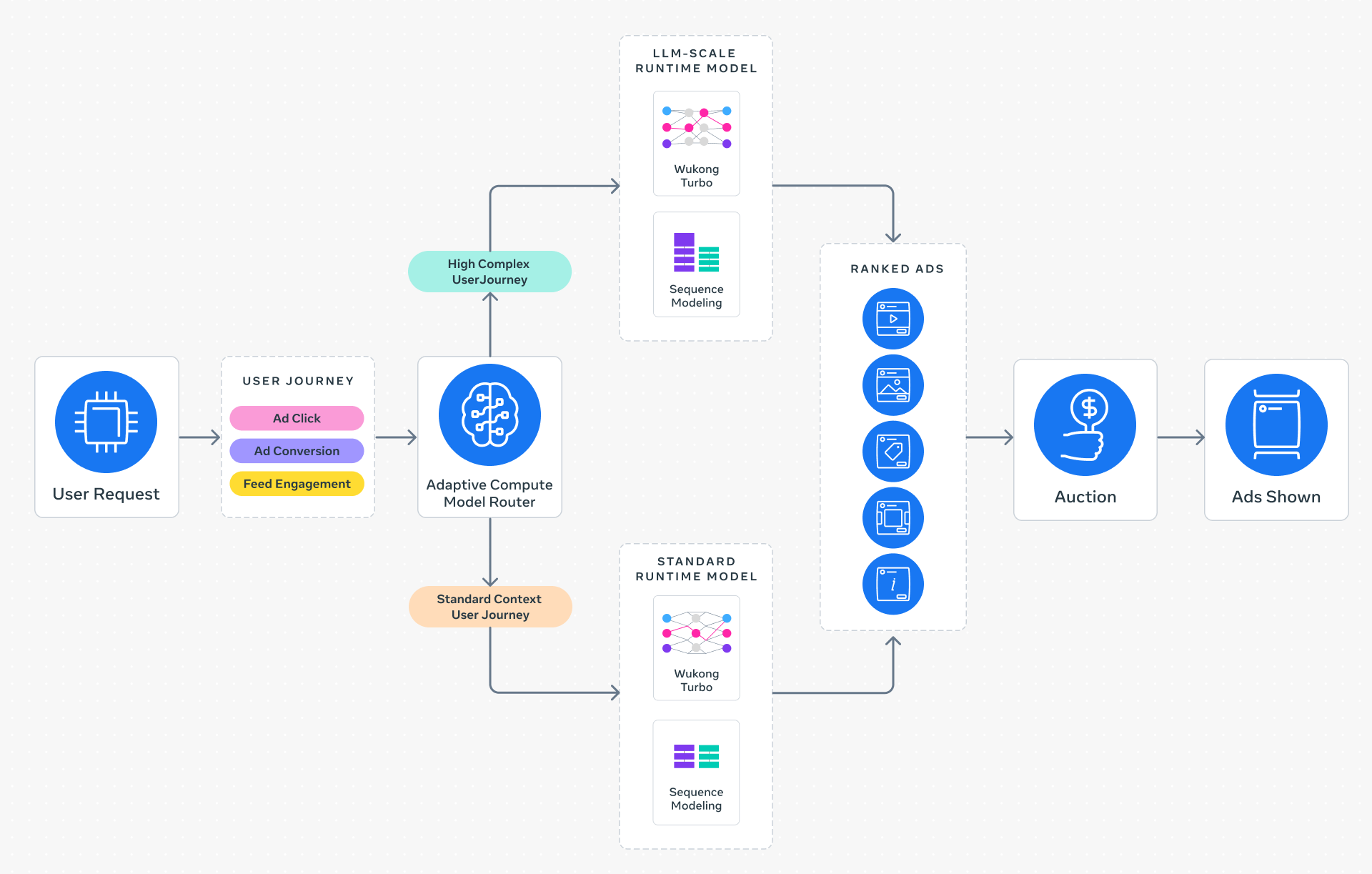 Serving LLM-scale models at Meta’s scale required a fundamental rethink of the inference stack, driven by three key innovations:
Serving LLM-scale models at Meta’s scale required a fundamental rethink of the inference stack, driven by three key innovations:
By further integrating LLM-scale intelligence into our ads stack, Adaptive Ranking Model delivers a significant increase in ad conversions and advertiser value while maintaining system-wide computational efficiency. This ensures superior performance for businesses of all sizes. Since launching on Instagram in Q4 2025, Adaptive Ranking Model has delivered a +3% increase in ad conversions and +5% increase in ad click through rate for targeted users.
Serving LLM-scale & complexity models in a real-time ads recommendation environment requires resolving a fundamental tension between model complexity and system efficiency. Unlike LLM applications such as chatbots, where response times are measured in seconds, an ad recommendation must achieve two uncompromising constraints:
Adaptive Ranking Model addresses these challenges through a paradigm shift powered by three core innovations across the serving stack:
By unifying these innovations, we ensure that the most effective model is used for every request — providing a highly personalized ad experience for people on our platforms and maximizing advertiser value while maintaining system-wide computational efficiency.
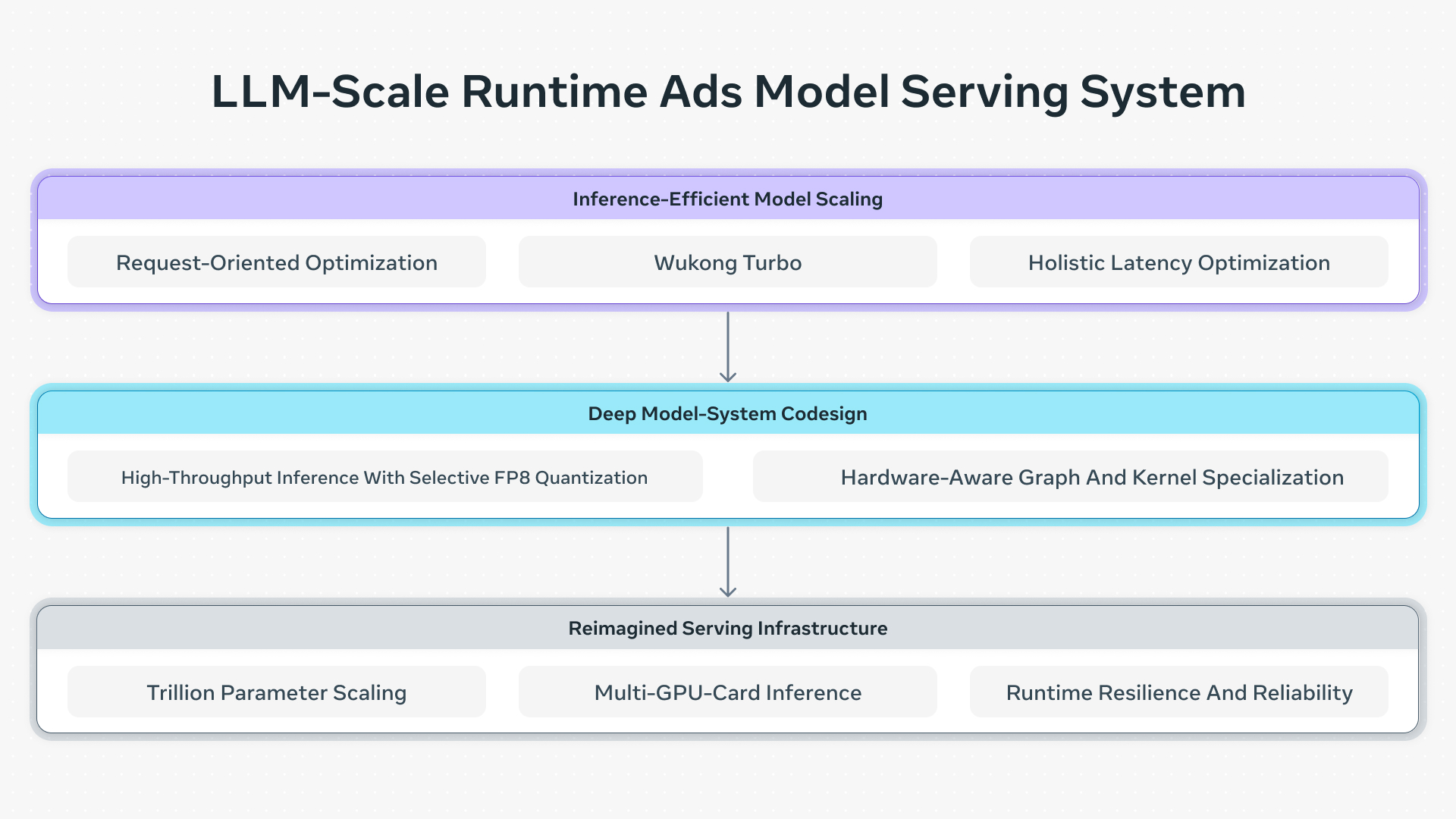
Adaptive Ranking Model introduces model-system innovations that fundamentally redefine inference efficiency. This transformation is built on three technical pillars:
Traditional models process each user-ad pair independently, creating massive computational redundancy. Adaptive Ranking Model eliminates this through Request-Oriented Optimization, which computes high-density user signals once per request rather than once per ad candidate. This shift, powered by Request-Oriented Computation Sharing and In-Kernel Broadcast optimization, which shares request-level embeddings across ad candidates directly within the GPU kernel, transforms scaling costs from linear to sub-linear while significantly reducing memory bandwidth pressure.
Building on this, Request-Oriented Sequence Scaling unlocks the use of long-form user behavior sequences that were previously limited by compute and storage costs. To minimize compute overhead, Adaptive Ranking Model processes heavy sequences once per request and shares the results across all ad candidates. To optimize storage, it replaces redundant data replication with a centralized, high-efficiency key-value store of user logs that are joined with training data on the fly. These optimizations jointly minimize the serving and storage footprints required for global-scale systems.
While Request-Oriented Optimization optimizes the computation flow, Wukong Turbo is the optimized runtime evolution of the Meta Ads internal architecture. Building on the Wukong architecture that uses stackable factorization machines, sequence learning and cross-layer attention, Wukong Turbo introduces specific refinements to handle the numeric instability and network overhead that typically arise when scaling deep models. Specifically, it employs a No-Bias approach to remove unstable terms, boosting throughput without increasing FLOPs or parameter counts. To prevent internal bottlenecks, it utilizes small parameter delegation to reduce network and memory overhead by offloading parameters from Fully Sharded Data Parallel (FSDP) to Distributed Data Parallel (DDP) alongside sparsity-based simplification that reduces redundant components in the linear layers. These enhancements transform the base architecture into a stable, high-performing system, allowing model complexity to scale while strictly protecting the sub-second inference budget.
The final stage of this transformation addresses feature preprocessing—a traditional bottleneck leading to client memory pressure and data starvation where the GPU’s compute power remains underutilized while waiting for processed features. Adaptive Ranking Model offloads preprocessing from the client CPU to remote GPU hosts, utilizing compact tuple-based formats and GPU-native kernels that reduce Top-K complexity from O(N log N) to O(N). To further speed up processing, we implemented a holistic strategy of optimized data compression and client-flow restructuring to eliminate thread-pool contention. These multi-layered optimizations successfully neutralized the latency penalty of LLM-scale & complexity, allowing Adaptive Ranking Model to deliver frontier-level personalization at the speed Meta’s global platforms require.
Meta Ads relies on deep system co-optimization to enable the LLM-scale model complexity within Meta-scale performance constraints. By fundamentally rethinking the boundary between the model and the hardware, we have created a unified inference stack that optimizes computational precision and graph execution to maximize computational ROI by boosting Model FLOPs Utilization (MFU) on heterogeneous hardware.
Large-scale models necessitate reduced precision to maintain high-throughput inference, yet a blanket application of low-precision quantization often degrades the nuance required for complex ads ranking. Adaptive Ranking Model overcomes this through a post-training quantization strategy that applies FP8 selectively. Using a micro-benchmark guided selection mechanism, the system deploys FP8 only in layers with high precision-loss tolerance. This targeted approach unlocks the throughput benefits of modern heterogeneous hardware for our most complex models with negligible impact on recommendation quality.
To minimize the latency caused by redundant memory access and inefficient kernel launches, Adaptive Ranking Model optimizes the execution flow through coordinated graph and kernel specialization. We fuse operators that share inputs to minimize data movement between high-bandwidth memory and on-chip SRAM. Additionally, thousands of small operations are consolidated into compute-dense kernels using techniques like Grouped General Matrix Multiply and horizontal fusion. This precise alignment between the computation graph and modern GPU architectures significantly reduces the memory footprint and increases effective hardware utilization, ensuring that LLM-scale model complexity translates directly into performance.
Beyond model-system co-optimization, deploying LLM-scale models at scale requires reimagining the underlying serving infrastructure. To neutralize the latency penalty of massive scale, the Adaptive Ranking Model utilizes a specialized stack designed to surpass physical memory limits and ensure Meta-scale production reliability.
Unlike standard LLMs, recommendation models are driven by predominantly sparse, categorical features. Mapping these IDs to high-dimensional embedding tables creates a critical trade-off where oversized tables lead to overfitting, while undersized tables suffer from hash collisions that degrade model quality. Adaptive Ranking Model enables O(1T) parameter scale through memory optimizations that resolve this tension. The system efficiently allocates embedding hash sizes based on feature sparsity and prunes unused embeddings to maximize learning capacity within strict memory budgets. This is further optimized by unified embeddings, which allow multiple features to share a single embedding table to significantly reduce the memory footprint without sacrificing the ability to learn complex feature interactions.
As LLM-scale model embeddings approached the terabyte level, they exceeded the memory capacity of any single GPU. To mitigate this, a multi-card sharding mechanism splits embedding tables into segments distributed across an optimized hardware cluster. By leveraging hardware-specific communication optimizations, the system maintains high throughput and efficient communication between shards. This multi-card architecture achieves performance parity with single-card setups, effectively decoupling model complexity from individual GPU hardware constraints.
Serving trillion-parameter models under high-traffic conditions presents significant reliability challenges, particularly regarding initialization speed and system stability. To ensure production-grade reliability, we developed accelerated model loading that utilizes multi-stream downloading and remote caching to load models in under 10 minutes, minimizing downtime during deployments. Auto-scaling rules based on streaming multiprocessor utilization allows the system to handle fluctuating traffic dynamically. This ensures real-time demand is met without the need for wasteful over-provisioning, maintaining stability across the platform.
The launch of Adaptive Ranking Model on Instagram marks the first milestone in our journey to bend the inference performance vs cost scaling curve at Meta scale. The roadmap shifts from individual optimizations toward an infrastructure that is increasingly autonomous and responsive to real-time fluctuations in user signal density and request patterns across our global ecosystem.
This vision began with evolving inference efficient scaling to unlock deeper complexity and longer behavioral sequences that capture user intent with unprecedented fidelity. To sustain this growth, we are pioneering a new era of inference execution efficiency, leveraging advanced model compression and ultra-low precision quantization methods to allow the most sophisticated LLM-scale models to run efficiently across a diverse global hardware fleet.
To eliminate the traditional bottlenecks of manual engineering, we are exploring agentic optimization frameworks to further accelerate kernel performance optimizations. These frameworks will automatically adapt to new hardware and model architectures, ensuring that the most sophisticated AI remains accessible and performant at scale.
Furthermore, we’re reimaging the speed of learning through near-instantaneous model freshness, utilizing incremental, in-place weight updates to achieve constant, real-time adaptation. Collectively, these innovations will ensure that the Adaptive Ranking Model continues to power more personal experiences for people while driving superior ROAS for advertisers globally.
We would like to thank: Jia Jiunn Ang, Pan Chen, Wenlin Chen, Maomao Ding, Chengze Fan, Lu Fang, Birmingham Guan, Qin Huang, Santanu Kolay, Ashwin Kumar, Jinfu Leng, Boda Li, Huayu Li, Jiawei Li, Li Li (Ads Ranking), Liyuan Li, Mingda Li, Wenyuan Li, Rocky Liu, Jason Lu, Robert Luo, Yinbin Ma, Sandeep Pandey, Uladzimir Pashkevich, Varna Puvvada, Michael Shao, Pranav Sharma, Zijian Shen, Vibha Sinha, Matt Steiner, Chonglin Sun, Weiman Sun, Aaron (Li Bo) Tao, Xiaohan Wei, Nathan Yan, Yantao Yao, Hongtao Yu, Li Yu, Sihan Zeng, Buyun Zhang, Bill Zhao, Alex Zhong, Zhehui Zhou, and the entire V-team team behind the development and productionization of the LLM scale runtime model in Meta’s ads recommendation system.
The post Meta Adaptive Ranking Model: Bending the Inference Scaling Curve to Serve LLM-Scale Models for Ads appeared first on Engineering at Meta.
Continue reading on the original blog to support the author
Read full articleThis research addresses the challenge of sparse signal optimization in massive-scale recommendation systems. By using hierarchical graph learning and multimodal enrichment, engineers can improve deep funnel performance and better align user intent with content in high-sparsity environments.
This demonstrates how BPF-based extensible scheduling allows engineers to bypass general-purpose kernel limitations. By tailoring CPU scheduling to specific workload patterns, Meta achieved massive latency reductions and power efficiency gains that standard schedulers couldn't provide.
Storage bottlenecks are a primary cause of GPU stalls in AI workloads. Optimizing BLOB storage for low-latency retrieval is critical for maximizing expensive compute utilization and accelerating the development of frontier models.
SilverTorch breaks the performance ceiling of microservice-based recommendation systems. By unifying retrieval into a single GPU-accelerated model, engineers can reduce latency, lower TCO, and eliminate the friction between ML and infrastructure development cycles.