At hyperscale, even 0.1% regressions waste massive power. Meta’s AI agents automate performance optimization, saving hundreds of megawatts and thousands of engineering hours. This demonstrates how LLMs can encode domain expertise to manage infrastructure efficiency autonomously.
We’ve built a unified AI agent platform that encodes the domain expertise of senior efficiency engineers into reusable, composable skills. These agents now automate both finding and fixing performance issues, recovering hundreds of megawatts (MW) of power and compressing hours of manual regression investigation into minutes, enabling the program to scale MW delivery across a growing number of product areas without proportionally scaling headcount.
On defense, FBDetect, Meta’s in-house regression detection tool, catches thousands of regressions weekly; faster automated resolution means fewer megawatts wasted compounding across the fleet. On offense, AI-assisted opportunity resolution is expanding to more product areas every half, handling a growing volume of wins that engineers would never get to manually. Together, this is how Meta’s Capacity Efficiency Program keeps growing MW delivery without proportionally growing the team. The end goal is a self-sustaining efficiency engine where AI handles the long tail.
Here’s how it works and where we’re headed:
When the code you ship serves more than 3 billion people, even a 0.1% performance regression can translate to significant additional power consumption.
In Meta’s Capacity Efficiency organization, we see efficiency as a two-sided effort:
These systems worked well and have played an important role in Meta’s efficiency efforts for years. However, actually resolving the issues they surface introduces a new bottleneck: human engineering time.
This human engineering time can be spent on any of the following activities:
Many engineers at Meta use our efficiency tools to work on these problems every day. But no matter how high-quality the tooling is, engineers have limited time to address performance issues when innovating on new products is our top priority.
We started asking: What if AI could handle investigation and resolution?
The breakthrough was realizing that both problems share the same structure:
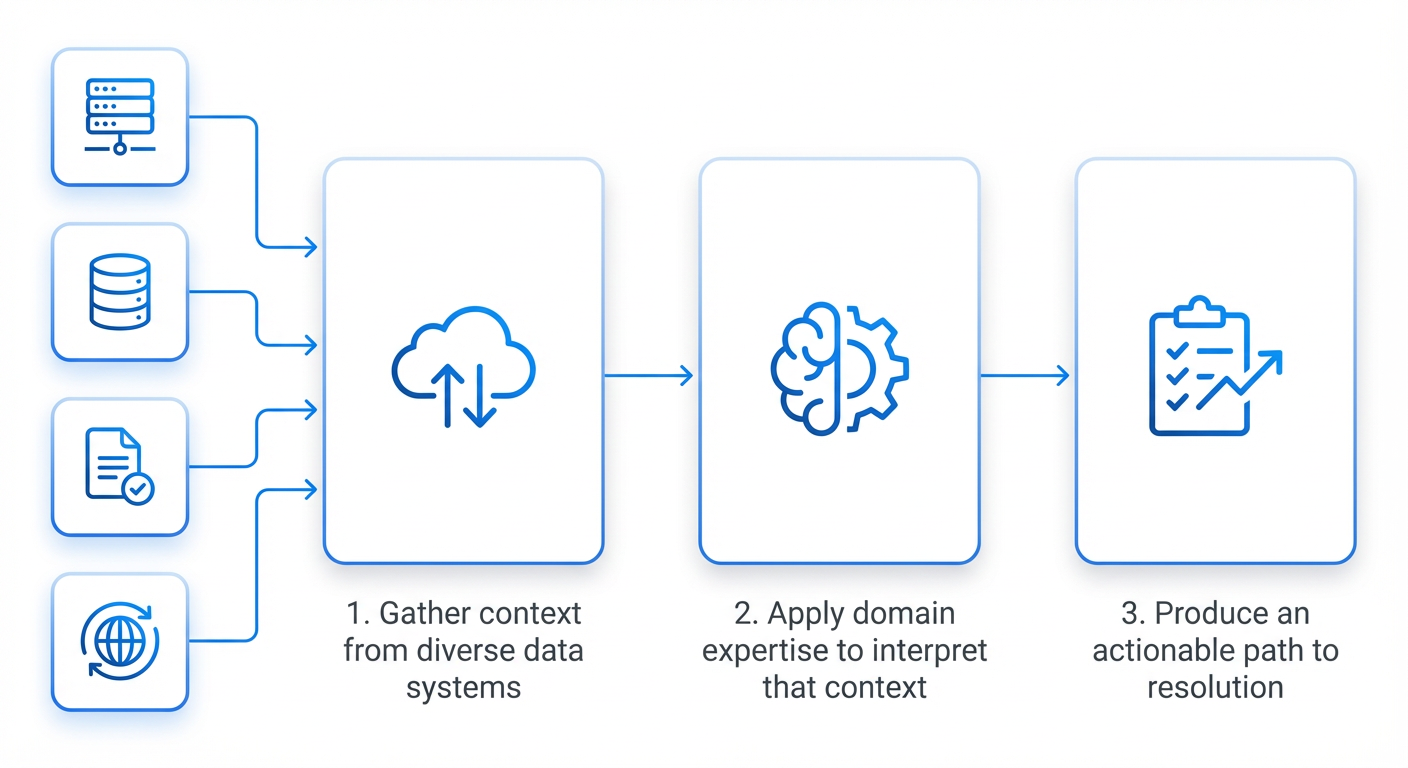 This meant we didn’t need two separate AI systems. We needed one platform that could serve both.
This meant we didn’t need two separate AI systems. We needed one platform that could serve both.
We built it on two layers:
Together, tools and skills promote a generalized language model into something that can apply the domain expertise typically held by senior engineers. The same tools can power both offense and defense. Only the skills differ.
FBDetect is Meta’s in-house regression detection tool that can catch performance regressions as small as 0.005% in noisy production environments. It analyzes time series data like this:
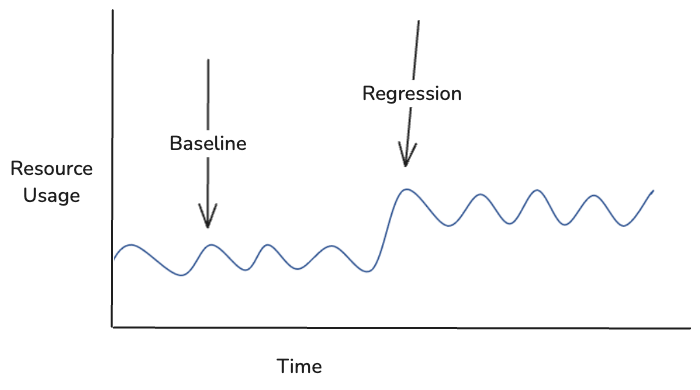
When FBDetect finds a regression, we immediately attempt to root-cause it to a code or configuration change; this is a vital first step to understand what happened. It’s done primarily with traditional techniques such as correlating regression functions with recent pull requests. After a root cause is determined, engineers are typically notified and expected to take action, such as optimizing the recent code change. We’ve added an additional feature to make this faster:
Our AI Regression Solver is the newest and most promising component of FBDetect, which produces a pull request to fix forward the regression automatically. Traditionally, root-causes (pull requests) that created performance regressions were either rolled back (slowing engineering velocity) or ignored (increasing infrastructure resource use unnecessarily).
Now, our in-house coding agent is activated to do the following:
On the offensive side, “efficiency opportunities” are proposed conceptual code changes that are believed to improve performance of existing code. We built a system where engineers can view an opportunity and request an AI-generated pull request that implements it. What used to require hours of investigation now takes minutes to review and deploy.
The pipeline mirrors the defensive AI Regression Solver:
Importantly, we use the same tools as defense: profiling data, documentation, code search. What differs is the skills.
Our unified architecture with shared tools and data sources has been a clean abstraction. Each existing and new agent has an easy way to gather context about performance with the interfaces we’ve made, without the need to reinvent the wheel.
This post focused on our first use cases: performance regressions and opportunities. Within a year, the same foundation powered additional applications: conversational assistants for efficiency questions, capacity planning agents, personalized opportunity recommendations, guided investigation workflows, and AI-assisted validation. Each new capability requires few to no new data integrations since they can just compose existing tools with new skills.
The results of the Capacity Efficiency program are significant: We’ve recovered hundreds of megawatts of power. The AI systems for both offense and defense contribute to supporting this effort.
But the deeper change is in how offense and defense reinforce each other: Engineers who spent mornings on defensive triage now review AI-generated analyses in minutes. Engineers using our efficiency tools can now get AI-assisted code instead of starting from scratch. The daunting question of “where do I even start?” has been replaced by reviewing and deploying high-impact fixes.
The post Capacity Efficiency at Meta: How Unified AI Agents Optimize Performance at Hyperscale appeared first on Engineering at Meta.
Continue reading on the original blog to support the author
Read full articleZoomer is crucial for optimizing AI performance at Meta's massive scale, ensuring efficient GPU utilization, reducing energy consumption, and cutting operational costs. This accelerates AI development and innovation across all Meta products, from GenAI to recommendations.
This demonstrates how BPF-based extensible scheduling allows engineers to bypass general-purpose kernel limitations. By tailoring CPU scheduling to specific workload patterns, Meta achieved massive latency reductions and power efficiency gains that standard schedulers couldn't provide.
Configuration errors are a leading cause of large-scale outages. This article highlights how Meta uses automated canarying, ML-driven alerting, and a blameless culture to maintain system stability while scaling deployment speed in an AI-accelerated environment.
Scaling recommendation systems to LLM-scale is often cost-prohibitive. Meta's approach demonstrates how co-designing hardware and software with intelligent request routing can break the inference trilemma, delivering high-performance AI at global scale with industry-leading efficiency.