Code coverage is often a structural issue rather than a testing one. Refactoring data models to remove boilerplate allows teams to meet CI requirements while improving maintainability and reducing CI runtime, avoiding the trap of writing low-value tests.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Tom Noah, Senior Software Engineer on Salesforce’s Security Mesh platform team, who integrates signals from CrowdStrike, Okta, and internal event monitoring systems to analyze massive security data streams. To support this, Tom increased code coverage by 28% without adding a single test by restructuring how data models were implemented.
Learn how Tom navigated CI-enforced code coverage constraints at the module level that blocked feature development at the file level, how he addressed the distortion of code coverage metrics, and much more.
We build systems that reliably detect and surface security signals across integrated providers. Our team aggregates events from external and internal sources to identify anomalies that indicate malicious activity.
Because these insights directly impact trust, correctness and reliability remain critical. We design services so engineers confidently evolve detection logic without introducing regressions.
This goal requires strong validation and an adaptable codebase for new integrations. In this environment, code coverage acts as a gating factor for shipping detection capabilities while maintaining system integrity.
CI-enforced code coverage at the module level created a constraint where validation depended on specific modified files. While the overall project met the threshold, individual modules often fell below the required bar.
Developing a new feature in these low-coverage modules failed validation and blocked merges. This mismatch forced engineers to address unrelated coverage gaps instead of delivering functionality.
Writing tests for code unrelated to the feature extended timelines and increased overhead. This granular constraint exposed structural inefficiencies that required a systemic solution.
Auto-generated code in CI pipelines distorted coverage metrics by including logic outside the core business functionality. Measurements included generated methods like getters, setters, and utility functions that did not represent meaningful system behavior.
This inclusion made coverage percentages appear lower for the logic that mattered. Consequently, engineers felt pushed to write tests for code already validated by underlying libraries.
These tests increased volume without improving system confidence. The metric no longer reflected real quality because non-essential code was measured alongside critical logic.
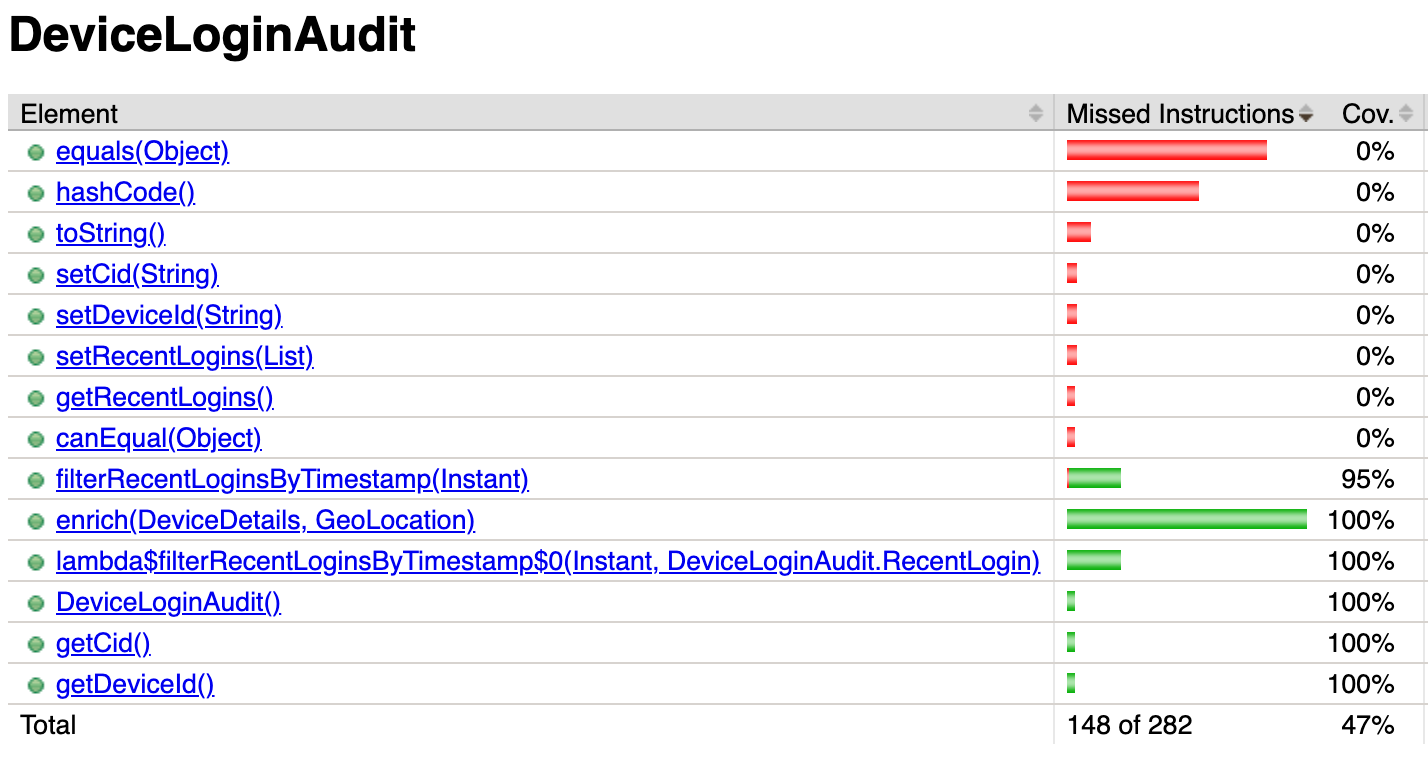
The original code contained many redundant methods before the refactor.
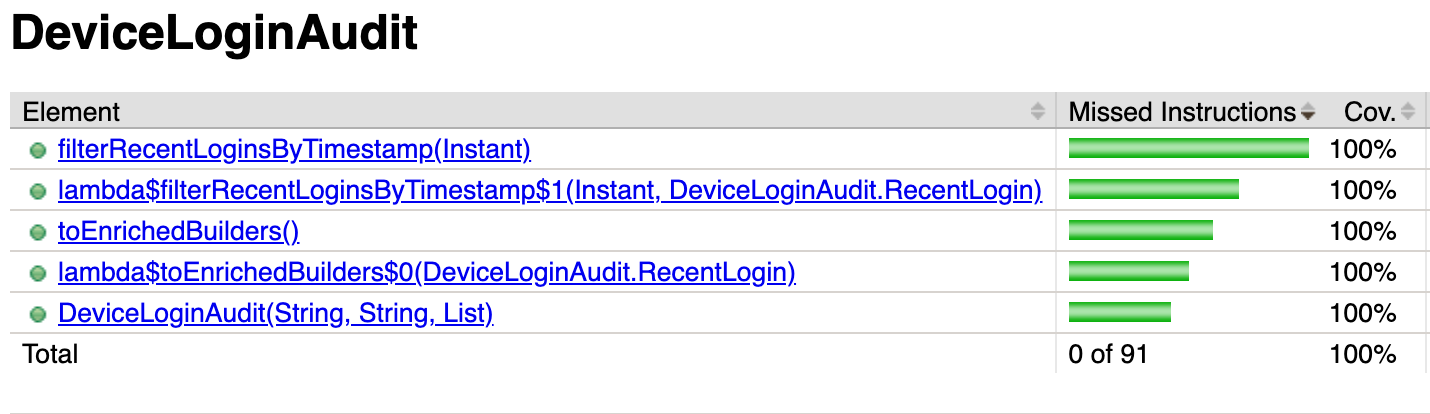
The update ensures we measure only relevant methods for code coverage.
Adding more tests to increase coverage offered an easy path but introduced several downsides. This approach increased CI runtime, which slowed feedback loops and consumed more resources during pipeline executions.
Tests also define the system contract. Writing tests for non-essential code creates a false contract that future developers must preserve, even when the behavior lacks significance. This makes refactoring harder and increases the risk of breaking tests that do not reflect true requirements.
These tests also mislead AI-assisted development tools, which interpret them as valid constraints and avoid better implementations. Furthermore, more tests increase the codebase size, impacting maintainability and review complexity.
Adding tests would have improved the metric while degrading overall system quality. Instead of increasing test volume, we shifted the focus from testing to system design.
This approach increased code coverage by reducing unnecessary code instead of increasing test volume. We treated coverage as a structural issue within our data model implementation rather than a testing problem. The process followed these steps:
@Data annotated, but it made the classes be mutable and in addition it generated a lot of redundant code in the background. We examined which classes should really be mutable and which can be immutable, which was better not only for eliminating the redundant code, but also for thread safety and more reasons, as suggested by the modern Java best practices.@Value annotation retained behavior while reducing redundancy.Restructuring data models removed redundant code and reduced the total lines measured. This reduction improved the coverage ratio naturally, resulting in a 28% increase without adding any tests.
The main constraint involved balancing immutability with the need to evolve and enrich objects. While immutable data structures in Java reduce complexity and improve predictability, they also limit direct modification.
The process followed these steps:
@Value annotation approach: We utilized @Value annotation approach for cases requiring complex behavior or inheritance.This approach ensured flexibility without reintroducing unnecessary code. It reduced code volume, improved thread safety in a distributed system, and maintained a clean design.
Excessive auto-generated code created noise that disrupted the performance of AI development tools and LLM agents. Since these tools function within restricted context windows, heavy boilerplate takes up valuable room intended for essential logic. This clutter caused models to focus on minor details or maintain poor patterns because the core logic remained hidden behind generated distractions.
Redundant tests also created issues by validating flawed assumptions about how the system works. Models viewed these tests as fixed requirements, which frequently blocked superior technical solutions. Minimizing repetitive code and removing these false constraints restored clarity, enabling AI tools to function with better precision and speed.
The post How We Increased Code Coverage by 28% Without Writing a Single Test appeared first on Salesforce Engineering Blog.
Continue reading on the original blog to support the author
Read full articleCode coverage is often a structural issue rather than a testing one. By removing boilerplate and excluding generated code from metrics, teams can satisfy CI gates while improving maintainability and reducing pipeline overhead without adding low-value tests.
This system demonstrates how to transform massive, fragmented telemetry into actionable insights. By standardizing health metrics and isolating analytics from production, engineers can proactively identify risks, reduce support overhead, and ensure platform stability at a petabyte scale.
For global-scale perimeter services, traditional sequential rollbacks are too slow. This architecture demonstrates how to achieve 10-minute global recovery through warm-standby blue-green deployments and synchronized autoscaling, ensuring high availability for trillions of requests.
Securing AI agents at scale requires balancing rapid innovation with enterprise-grade protection. This architecture demonstrates how to manage 11M+ daily calls by decoupling security layers, ensuring multi-tenant reliability, and maintaining request integrity across distributed systems.