This article details how to scale legacy data integration systems to modern cloud-native standards. It highlights the importance of backward compatibility, the use of Spark for distributed processing, and how FinOps automation can optimize infrastructure costs for massive enterprise workloads.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today we spotlight Shivangi Srivastava, Senior Director of Software Engineering at Salesforce, as she details the creation of Cloud Data Integration, the decentralized architecture driving Informatica’s platform that supports workflows for over 5,500 corporate clients managing about 250,000 daily tasks.
Explore how the team transformed the Informatica data integration framework from a solitary node setup into a scalable Spark environment on Kubernetes while ensuring legacy support for thousands of active streams and utilizing FinOps logic to stabilize operational expenses against processing speed for massive data sets.
We make enterprise data accessible and reliable across hybrid and multi-cloud environments. Cloud Data Integration serves as the engine for this mission by connecting systems, transforming datasets, and moving information to its destination.
Enterprises manage hundreds of sources, including SaaS platforms and legacy systems. CDI provides the necessary connectors for these environments. This allows teams to build pipelines that cleanse and reshape data as it moves through the organization.
Productivity remains a central focus for us. We prioritize graphical pipelines over handwritten code within the CDI model. Engineers define mappings while the runtime engine handles orchestration and scaling. This approach lets teams design integrations instead of managing infrastructure.
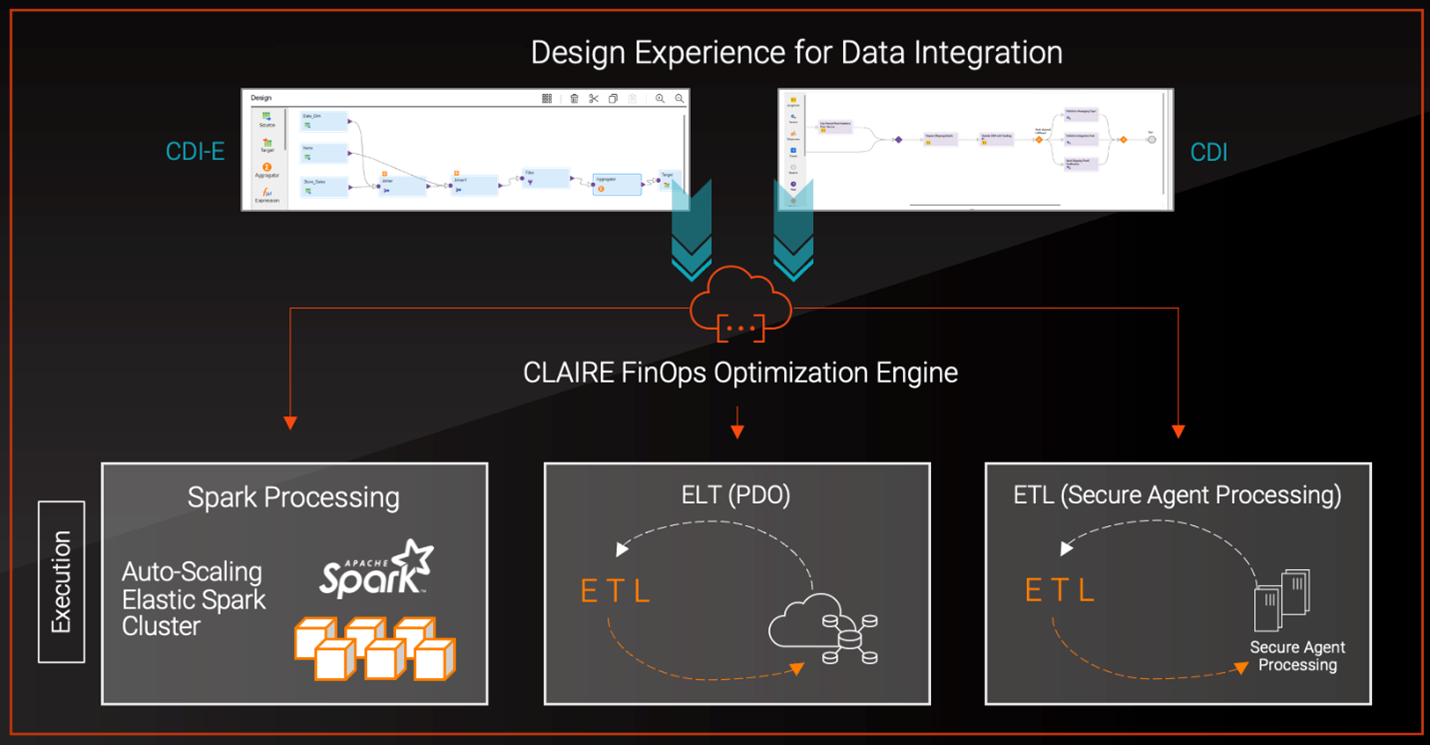
High-level overview.
The original Informatica integration engine served a different era of data processing. It functioned as a single-node system, which worked for datasets measured in gigabytes.
Modern enterprises now operate at a massive scale. SaaS platforms and digital applications generate volumes that reach terabytes and petabytes. This shift required a move toward a distributed architecture.
Backward compatibility remained the primary constraint during this transition. Since thousands of production pipelines already existed on the platform, asking users to rebuild them was not an option. We solved this by preserving the logical abstraction layer used to design pipelines. Engineers still create graphical mappings, but the runtime now converts those mappings into distributed Spark execution plans.
Open-source Spark alone lacked necessary enterprise capabilities like lineage tracking and deep connector support. To fix this, we extended the engine into Spark++. This version combines the distributed processing model of Spark with our transformation framework and governance features. This extended runtime allows CDI to run complex integration pipelines at scale while keeping the logical abstractions engineers already use.
CDI operates as the backbone of many data workflows. Reliability remains a core design requirement because integration pipelines power analytics systems and operational processes.
To maintain stability, CDI focuses on three reliability principles:
These systems allow CDI to function as a stable data integration backbone. The platform maintains a 99.9% control-plane availability target.
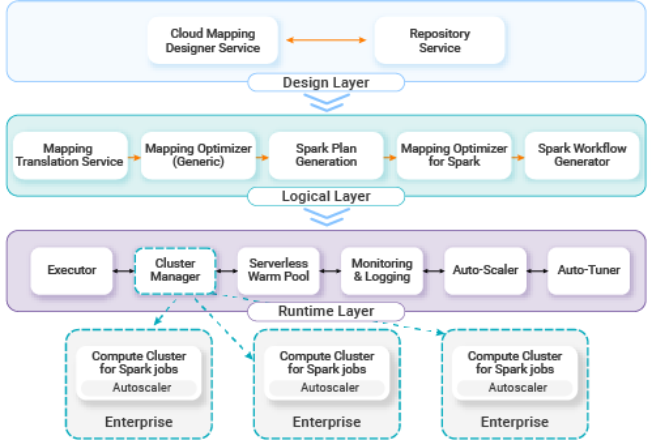
High-level architecture.
Scaling CDI presents challenges as enterprise data volumes expand. Infrastructure planning grows complex because cloud providers offer many compute and storage options.
Enterprise deployments face three specific scaling challenges:
CDI uses FinOps automation to solve these issues. Users define cost and performance goals instead of configuring clusters manually. The platform analyzes workloads and selects the best infrastructure configuration. It scales compute resources dynamically across Kubernetes-managed clusters.
This approach processes large datasets efficiently. Engineers no longer manage infrastructure directly.
Scaling distributed systems by simply adding hardware often leads to rapidly increasing infrastructure costs. CDI automates infrastructure optimization to balance performance and cost. This architecture removes the manual burden of cluster management.
Three core systems power the FinOps architecture:
These systems optimize infrastructure continuously. Production deployments show this architecture reduces infrastructure costs by approximately 1.65 times while maintaining performance.
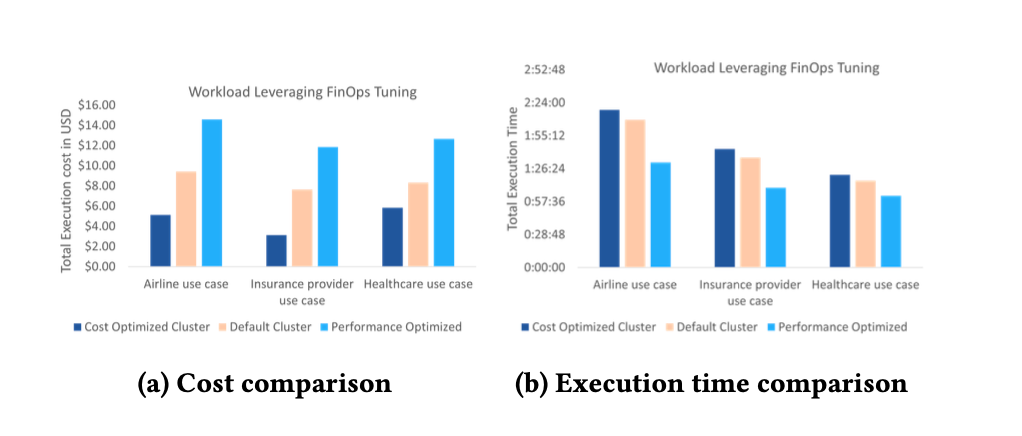
Sample performance results.
Scaling CDI at an enterprise level requires more than just initial construction. The platform must manage growth across customer environments, job concurrency, and data throughput.
CDI currently supports approximately 5,500 enterprise customers who execute roughly 250,000 integration jobs daily. Two architectural choices maintain stability at this scale:
This design ensures orchestration services remain stable during compute cluster spikes. Advanced scheduling also prevents large workloads from monopolizing shared infrastructure. These capabilities allow CDI to maintain performance during enterprise growth.
The post Inside Informatica’s Spark-Based Data Integration Platform: Running 250K Enterprise Pipelines Daily appeared first on Salesforce Engineering Blog.
Continue reading on the original blog to support the author
Read full articleThis article details scaling legacy data systems to modern distributed environments using Spark and Kubernetes. It demonstrates balancing backward compatibility with massive scalability and using FinOps to manage cost-performance trade-offs when processing petabytes of data daily.
Optimizing Kubernetes scheduling for bursty Spark workloads resolves the conflict between cost efficiency and job stability. By moving from reactive consolidation to proactive bin-packing, engineers can achieve significant cost savings without triggering disruptive pod evictions.
This article demonstrates how to build a resilient distributed system that handles extreme scale and unpredictable customer data models. It provides a blueprint for managing metadata bottlenecks and resource allocation when processing quadrillions of records across disparate storage systems.
Scaling distributed systems to 120 trillion rows requires moving beyond query federation. Adopting a file-based approach with Apache Iceberg eliminates bottlenecks between compute and storage, enabling high-performance AI at petabyte scale without data duplication.