This article demonstrates how a robust data foundation like Data 360 enables rapid AI deployment. It provides a blueprint for handling large-scale unstructured data and meeting aggressive deadlines through architectural reuse and automated data preparation.
By Irina Malkova and Alexander Smith.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Irina Malkova, Vice President of Product and Success Data, who helped deliver the data foundation behind the Informatica Help Agent in just 24 days.
Explore how the team met an ambitious deadline by refining project focus, converting 100,000 unstructured documents into searchable intelligence via Data 360, and applying established architectural frameworks to enable reliable retrieval for live agents.
The team builds trusted AI-ready context. In this case, a knowledge base that empowers Informatica agent to reliably answer customer questions and reduce support cases. We support all agents that augment the Customer Success business motion, including those on help.salesforce.com and slack.com/help. Our strategy balances enabling helpful, tailored answers for each agent with building a durable data foundation that can power future agents, too — reducing time to launch and ensuring consistent trusted results across all experiences.
Data 360 is how the team unifies, standardizes, indexes, and activates unstructured knowledge. Data preparation is a notoriously difficult step in building AI — but Data 360 eliminates the need for custom pipelines, accelerates time to launch, and enables reuse — making tight deadlines possible.
Retrieval precision and accuracy defined the success of the Informatica Help Agent. By focusing on AI data readiness as a core engineering task, the team delivers correct answers and scales the system without losing trust.
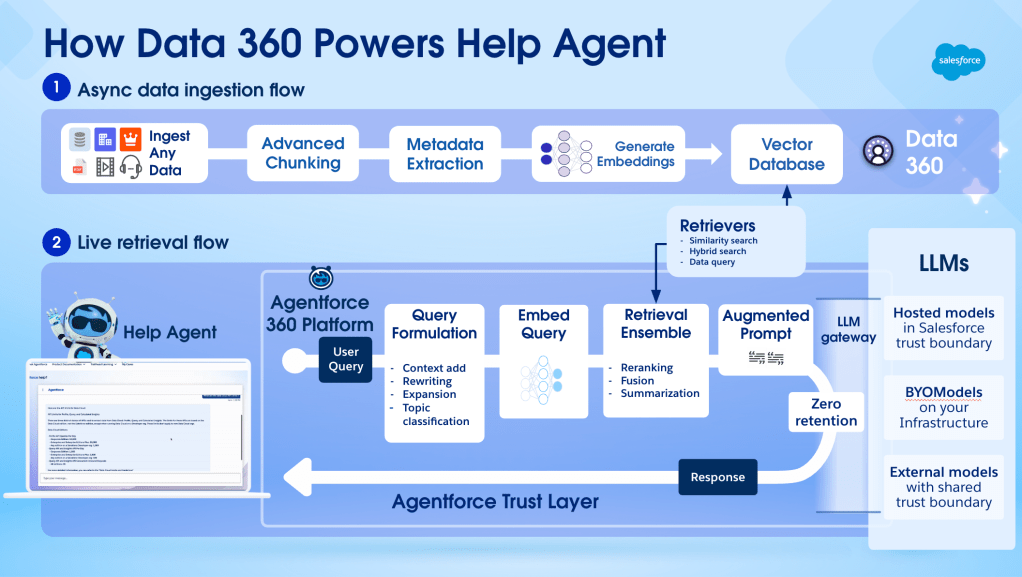
How Data 360 transforms data into retrievable context for AI Agents.
We were challenged to enable Informatica Agent in 30 days after the acquisition completed on November 18, 2025. The ambitious post-acquisition timeline required strict discipline and architectural creativity. The team focused on delivering a production-grade high-quality foundation instead of addressing every complex detail in the initial release.
To avoid friction that threatened the deadline, the team leveraged clever architectural approaches. For instance, Informatica’s knowledge base had complex versioning, with many near-duplicate articles differing only slightly across product versions. The team found a way to manage the product versioning through prompting and configuration rather than changing the system logic. This choice kept the primary effort on ingestion and retrieval fundamentals.
Execution relied on reusing established Data 360 patterns while protecting the engineering team from distractions. By following a precise plan and sequencing tasks carefully, the team completed the entire system in 24 days — ahead of the 30 day deadline.
Informatica documentation was written for human readers rather than artificial intelligence. Raw HTML files contained headers, footers, and navigation menus that interfere with retrieval quality. To become AI-ready, the knowledge needed a cleanup — but manual cleaning was impossible at this scale.
Instead, the team used Data 360 patterns to normalize content and remove noise while keeping the original meaning. This process transformed HTML into consistent chunks for better embedding and retrieval.
Preparing this volume of content would have taken weeks without Data 360. By using native ingestion and search features, the team finished data preparation in days and moved quickly to optimizing the performance. Thanks to the data cleanup, they had a solid performance baseline to start with — because context determines the quality of an agent’s response.
The Informatica knowledge base came from different systems with unique structures and metadata. The ingestion process had to handle these differences while remaining reliable at a large scale.
A lot of Informatica’s knowledge we sought to use was available through a content management system and hosted on their website. To ingest it, the team used the new Data 360 feature “sitemaps” that crawls the website and creates conforming Data 360 knowledge.
For more unique content, Python workflows managed the extraction, while Data 360 handled the ingestion and storage. The first ingestion of developer documentation finished in about three hours. Future updates ran faster as the pipelines stabilized.
The team managed limitations in filtering and refresh timing through preprocessing and configuration. Despite these constraints, Data 360 pipelines supported hundreds of thousands of documents. This approach created a production-ready knowledge base within the necessary timeline.
Accuracy remains vital because documentation varies by product version and user type. Mismatched content risks eroding trust even when responses appear relevant. To solve this, the team reused proven chunking strategies that worked for Customer Success and added filters and metadata tags during ingestion.
These tags enable more precise retrieval and simplify evaluation by narrowing results to the most relevant context. Real-world usage validated this approach following the launch. The Informatica Help Agent achieved an 80% resolution rate with only 5% human escalation. This success demonstrates that retrieval accuracy and performance hold under live traffic without sacrificing quality.
Confidence in existing Data 360 patterns drove the decision to reuse systems and move quickly without adding unnecessary complexity. Rather than rebuilding from scratch, the team extended established configurations for ingestion, chunking, indexing, and retrieval to Informatica content.
Although Informatica data behaves differently than Salesforce-authored content, necessary adjustments remained localized. Because pipelines and infrastructure follow a standard design, tuning did not require systemic changes or a ground-up redesign.
This strategy avoided a rebuild that would have required a much larger team and months of extra work. In practice, reusing proven patterns in Data 360 delivered equivalent outcomes in a fraction of the usual time. The process maintained enterprise quality while establishing a scalable foundation for future agent expansions.
The post Against the Clock: How Data 360 Launched the Informatica Help Agent in 24 Days appeared first on Salesforce Engineering Blog.
Continue reading on the original blog to support the author
Read full articleManual bug triage at scale is slow and inconsistent. By combining custom ML with LLMs, teams can automate complex engineering judgments, preserving institutional knowledge while reducing months of manual effort to days, significantly accelerating product quality improvements.
This approach reduces 'reasoning tax' by pre-processing messy documentation into synthesized context. It enables faster onboarding for humans and provides AI agents with a reliable, low-cost knowledge layer, improving the efficiency of RAG systems without complex infrastructure.
This article demonstrates how generative AI can eliminate manual bottlenecks in ETL processes. It provides a blueprint for transitioning from fine-tuned models to foundation models while maintaining reliability through grounding and validation.
Scaling distributed systems to 120 trillion rows requires moving beyond query federation. Adopting a file-based approach with Apache Iceberg eliminates bottlenecks between compute and storage, enabling high-performance AI at petabyte scale without data duplication.