As AI agents handle more domain-specific tasks, their reliability becomes critical. This guide offers an empirical framework to move beyond 'vibes-based' AI development, providing a repeatable process to test and optimize how agents apply internal architectural knowledge.
Author: Daniel Reed

The tech industry is currently seeing a massive overhaul in the way we work and many are enjoying the benefits of AI agents, particularly when automating engineer workflows and serving domain-specific knowledge. However, relying on agents to consistently invoke a custom skill can be surprisingly unreliable at times.
When adopting a new skill intended to help agents write code for Pinterest’s iOS architecture (I’ll call it rx-mvvm) we discovered that sometimes our knowledge skill wasn’t being loaded into our agents. To address this, we conducted a series of tests on Pin-agent (an internal fork of OpenAI’s Codex) and Claude Code to quantify the reliability of skill invocation and identify some best practices to maximize performance. This was a direct result of observing agents struggling to meet the skills bar during architectural reviews. We found that by applying different techniques we could track and drastically improve skill invocation rates on both tested agents.
How to Build A Skill Test Harness
Building a reliable test harness for agent skill invocation requires three key components working in concert. The Core Tool is a Bash script that orchestrates automated testing by piping prompts to your agent and capturing verbose output logs. The core execution is simple:
if echo "$prompt" | claude --print --verbose --output-format stream-json > "$log_file" 2>&1; then
command_success=true
fi
The script runs all test cases in sequence, collecting logs for later analysis. We ran the entire suite multiple times to account for the nondeterministic nature of agents. Prompts were categorized into two categories defined as arrays:
Positive Cases — 15 prompts covering the full spectrum of skill domains:
CORE_PROMPTS=(
"load the rx-mvvm-architecture skill"
"check if this follows rx-mvvm patterns"
# ... 13 more cases
)
Negative Cases — 5 general programming prompts designed to expose false positives:
EDGE_PROMPTS=(
"fix this Swift compilation error"
"write unit tests for this View"
"refactor this function"
# ... 2 more cases
)
We then use log parsing heuristics on the json output logfiles to detect skill invocation by searching for telltale patterns in the JSON-streamed debug output.
skill_invoked_claude() {
local log_file="$1"
if grep -q '"name":"Skill"' "$log_file" && grep -q '"command":"rx-mvvm-architecture"' "$log_file"; then
return 0
elif grep -q 'Launching skill: rx-mvvm-architecture' "$log_file"; then
return 0
else
return 1
fi
}The script finally tallies successes across both categories and computes three key metrics with clear formulas:
CORE_SUCCESS_RATE=$(awk "BEGIN {printf \"%.1f\", ($CORE_SKILL_INVOKED / $CORE_TOTAL) * 100}")
EDGE_FALSE_POSITIVE_RATE=$(awk "BEGIN {printf \"%.1f\", ($EDGE_SKILL_INVOKED / $EDGE_TOTAL) * 100}")
OVERALL_ACCURACY=$(awk "BEGIN {printf \"%.1f\", ($TOTAL_CORRECT / $TOTAL_TESTS) * 100}")What we learned: optimizations
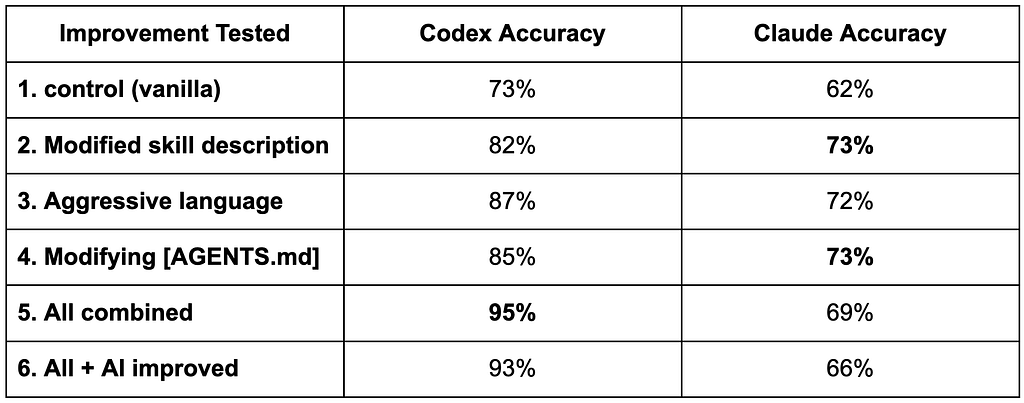
Our initial “vanilla” testing revealed that neither agent could guarantee 100% skill invocation, particularly when engineers used terse or ambiguous prompts. The baseline performance was an overall accuracy of 73% for Codex and 62% for Claude. This low reliability is unacceptable for critical engineering workflows.
Our research confirmed that the performance of both tools can be dramatically improved, with the increase being much greater for Codex than for Claude. We found there were many ways to improve skill invocation rates:
Below is a table detailing what we found in our runs. For Codex, we used GPT 5.2-codex and for Claude we were using Opus 4.5.
(100 tests = 5 runs * (15 “positive” + 5 “negative”) tests)
Conclusion
I would be in remiss if I didn’t say that the test prompts we are using are intentionally terse — they’re meant to catch edge cases. This isn’t an indictment of agent skills, models or harnesses. Every single test case during every single run on both agents loaded the skill when the prompt explicitly said ‘load this skill’. The primary method of reliable skill invocation is a good plan, verbose instruction and clear intent from the developer.
The overarching lesson we learned through this process was that not only is it possible to empirically test how often we were loading the skills we expected, it’s something we should encourage, adopt and improve upon so that our agentic AI coding tools become more effective. However, even with a fully optimized skill the engineers working with AI have a responsibility to use high quality and thorough prompts. Teams should follow both of these rules to unlock the full potential of AI agents for domain specific work.
An Engineer’s Guide to Better AI Skills: Implementing a Testing Process to Optimize Agent… was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleStandard recommendation systems often over-optimize for immediate clicks, leading to user churn. By modeling the lifecycle of specific interests (UICs), engineers can build systems that prioritize long-term retention and discovery, ensuring platforms remain relevant as user needs evolve.
Scaling recommendation models is often limited by network bandwidth rather than compute. This demonstrates how to overcome communication bottlenecks in embedding-heavy architectures, enabling massive model training with near-linear efficiency and optimized infrastructure costs.
Managing user-sequence data is notoriously expensive and prone to training-serving skew. This unified architecture reduces operational costs and ensures data consistency across the ML lifecycle, enabling faster iteration on sequence-aware models like Transformers for recommendation systems.
This approach solves the 'cold start' of session intent in recommendation systems by blending offline historical sequences with real-time context. The hybrid inference model balances computational efficiency with immediate relevance, significantly improving candidate survival in ranking funnels.