Automating incident response at hyperscale reduces human error and cognitive load during high-pressure events. By using AI agents to correlate billions of signals, teams can cut resolution times by up to 80%, shifting from reactive manual triage to proactive, explainable mitigation.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, Deborah Donoghue, Vice President of Centralized Incident Response, who leads the team responsible for leading the mitigation of high-severity incidents across Salesforce’s global operations. Her organization functions at hyperscale, commanding incidents for the thousands of services and billions of telemetry signals.
Explore how her team eliminated human-driven detection bottlenecks using AI-based anomaly detection across metrics, logs, traces, releases, and vendor signals, reduced 3:00-AM decision latency with Agentforce-powered hypothesis generation and explainable recommendations, and accelerated mitigation through automated customer prioritization and runbook execution, cutting resolution time for common major incidents (our Severity 2 incidents) by approximately 70 – 80%.
The Centralized Incident Response team aims to ensure the success of incident response at Salesforce. Our mission to dismantle the cognitive and operational obstacles that impede incident response at an enterprise level. As Salesforce expanded in complexity and global presence, incident response became increasingly reliant on individuals manually piecing together disparate data, drawing conclusions from disconnected tools, and implementing mitigations under significant time constraints. This method, quite frankly, proved unsustainable.
To achieve our mission, we worked with our partners in Salesforce’s Site Reliability Engineering (SRE) team, who developed the Incident Command Deputy (ICD) platform. This multi-agent system is specifically engineered for incident response, and it leverages Agentforce for its core reasoning engine, orchestration layer, and workflow automation. The combined power of these systems transforms incident response from a reactive human-only process into one that is predictive, explainable, and continually improving.
Ultimately, the objective is centered on outcomes: to detect issues more rapidly, comprehend them more swiftly, and mitigate them before customers experience any impact. Every architectural and operational choice — spanning detection, decision-making, execution, and post-incident learning — is firmly rooted in reducing uncertainty and empowering humans to act decisively when every minute counts.
Salesforce’s operational environment had, over time, become significantly fragmented, encompassing observability, CI/CD, change management, and capacity systems. These systems evolved independently, each with its own schema, and presented signals in isolation. During incidents, this forced individuals into the slow and error-prone task of manually correlating data across numerous dashboards in real-time.
ICD employs durable orchestration for its long-running workflows and utilizes Hyperforce foundations to maintain consistent identity and entity resolution. This allows signals from various layers of the stack to converge into a single, comprehensive system view.
This unified model holds significant importance because AI reasoning relies on structured, interconnected data. By consolidating fragmented tools into a singular reasoning surface, ICD empowers agents to analyze incidents holistically, rather than compelling humans to mentally piece together context under duress.
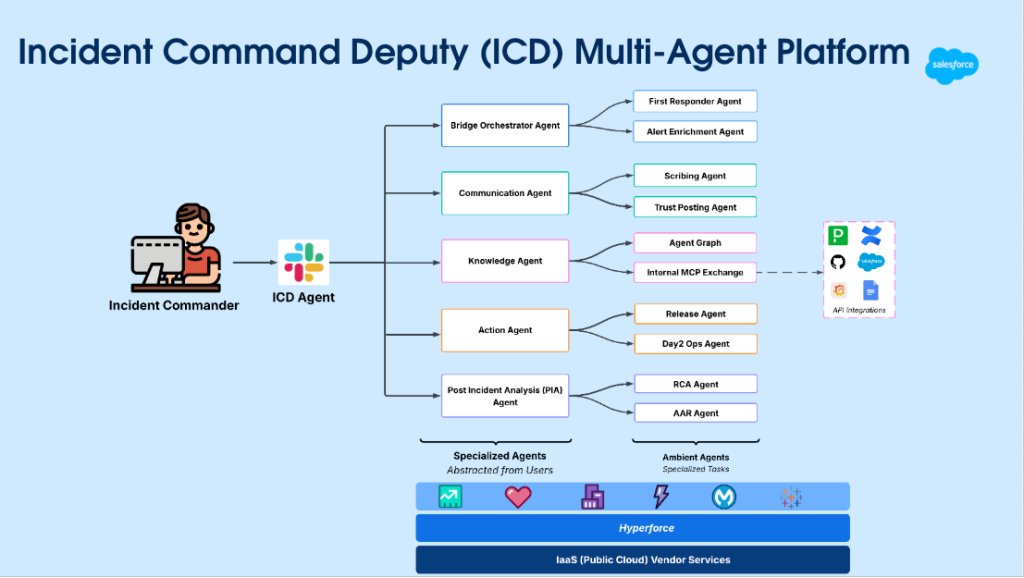
The ICD platform’s agentic relationships.
Human-driven triage and diagnosis became ineffective once Salesforce achieved hyperscale. The platform generates billions of time-series signals and ingests petabytes of logs daily across its infrastructure, network, storage, and application layers. Usage patterns fluctuate based on region, season, and customer behavior, rendering static thresholds useless.
Manually monitoring this extensive surface area and then correlating and triaging demanded that humans reconcile time zones, interpret inconsistent telemetry, and identify significant deviations, often after customers had already experienced an impact. Detection and understanding the real nature of the problem frequently lagged behind customer reports, which increased the blast radius and duration of impact.
The Infrastructure Lifecycle Management (ILM) implemented AI-based anomaly detection to continuously examine the entire telemetry surface. Machine learning models establish dynamic baselines, identify deviations in near real-time, and correlate anomalies with releases, capacity changes, and vendor signals. This allows ICD to proactively present actionable signals rather than reactively.
The organization has already seen the most common forms of incidents be detected within ten minutes, and then resolved. They have already seen a great improvement in the effectiveness of subsequent responses.
Once incidents were detected, triage and diagnosis presented the subsequent bottleneck. Engineers, paged at 3:00 AM, were expected to analyze data across 10 to 15 tools, interpret unfamiliar dashboards, and answer urgent questions within minutes. This often occurred while they were fatigued and under stress. Cognitive load, not a lack of expertise, proved to be the limiting factor.
ICD transfers that burden from humans to agents. Agentforce-powered agents automatically collect evidence across observability systems, compare signals to historical baselines, formulate hypotheses, and perform lightweight validation checks. These checks include customer-journey tests and internal integrations. The system then provides explainable recommendations to incident commanders and service owners.
This structured, repeatable reasoning model decreases inconsistency and accelerates the time to decision. It allows humans to concentrate on judgment and execution rather than data assembly. Decision-making becomes quicker, more dependable, and less reliant on individual experience.
Mitigation historically required humans to determine which customers to remediate first. This involved spreadsheets, manual lookups, and ad-hoc coordination with account teams. This process introduced ambiguity precisely when clarity was most critical.
The team replaced this approach with an AI-driven prioritization engine. This engine evaluates customer metadata, contractual commitments, entitlement tiers, revenue impact, and blast radius in real time. ICD integrates with other agents to generates a ranked mitigation order that reflects both technical and business risk, eliminating manual debate.
Mitigation execution accelerated further by automating runbooks and integrating agent recommendations with single-click remediation workflows. Instead of humans manually triggering thousands of pipelines, agents prepare and sequence actions safely and consistently.
Together, automated prioritization and execution reduced overall incident response time by approximately 70 to 80% for our most common incidents (Severity 2). This shrank incidents that previously lasted more than 12 hours and significantly improved enterprise reliability outcomes.
The post How Agentforce Empowered Incident Response Automation to Cut Common Resolution Time by 70 – 80% appeared first on Salesforce Engineering Blog.
Continue reading on the original blog to support the author
Read full articleTraditional logs fail to capture the data context of AI responses. This query-driven approach allows engineers to inspect the exact document chunks and embeddings used in production, slashing debugging time from weeks to hours while maintaining strict data isolation.
Moving AI to production requires shifting focus from prompting to distributed systems reliability. Durable workflows ensure that long-running tasks can recover from failures without duplicating expensive work or losing state, which is essential for enterprise-scale applications.
Manual bug triage at scale is slow and inconsistent. By combining custom ML with LLMs, teams can automate complex engineering judgments, preserving institutional knowledge while reducing months of manual effort to days, significantly accelerating product quality improvements.
This approach reduces 'reasoning tax' by pre-processing messy documentation into synthesized context. It enables faster onboarding for humans and provides AI agents with a reliable, low-cost knowledge layer, improving the efficiency of RAG systems without complex infrastructure.