Want to get the most out of search on your High Availability GitHub Enterprise Server deployment? Reach out to support to get set up with our new search architecture!
This architectural shift eliminates common failure modes in high-availability setups where search indexes could become locked or corrupted during upgrades. By using native Cross Cluster Replication, engineers gain a more resilient, easier-to-maintain search infrastructure.
So much of what you interact with on GitHub depends on search—obviously the search bars and filtering experiences like the GitHub Issues page, but it is also the core of the releases page, projects page, the counts for issues and pull requests, and more. Given that search is such a core part of the GitHub platform, we’ve spent the last year making it even more durable. That means, less time spent managing GitHub Enterprise Server, and more time working on what your customers care most about.
In recent years, GitHub Enterprise Server administrators had to be especially careful with search indexes, the special database tables optimized for searching. If they didn’t follow maintenance or upgrade steps in exactly the right order, search indexes could become damaged and need repair, or they might get locked and cause problems during upgrades. Quick context if you’re not running High Availability (HA) setups, they’re designed to keep GitHub Enterprise Server running smoothly even if part of the system fails. You have a primary node that handles all the writes and traffic, and replica nodes that stay in sync and can take over if needed.
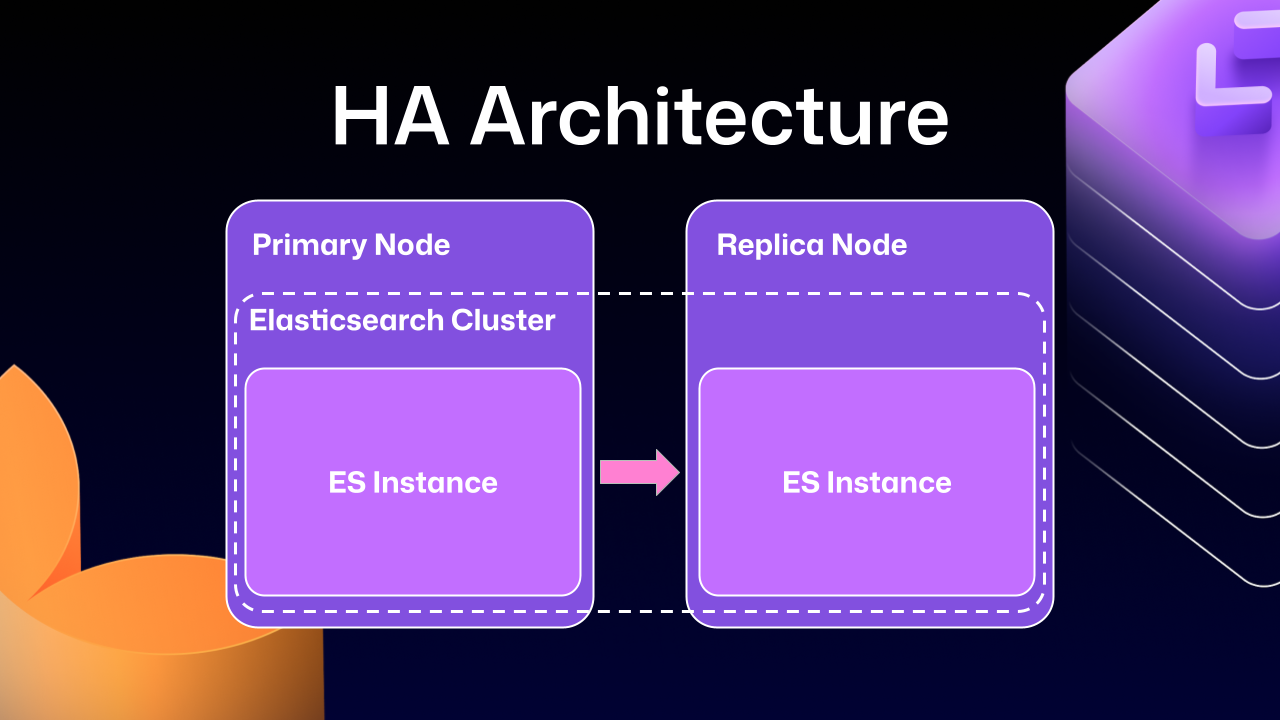
Much of this difficulty comes from how previous versions of Elasticsearch, our search database of choice, were integrated. HA GitHub Enterprise Server installations use a leader/follower pattern. The leader (primary server) receives all the writes, updates, and traffic. Followers (replicas) are designed to be read-only. This pattern is deeply ingrained into all of the operations of GitHub Enterprise Server.
This is where Elasticsearch started running into issues. Since it couldn’t support having a primary node and a replica node, GitHub engineering had to create an Elasticsearch cluster across the primary and replica nodes. This made replicating data straightforward and additionally gave some performance benefits, since each node could locally handle search requests.
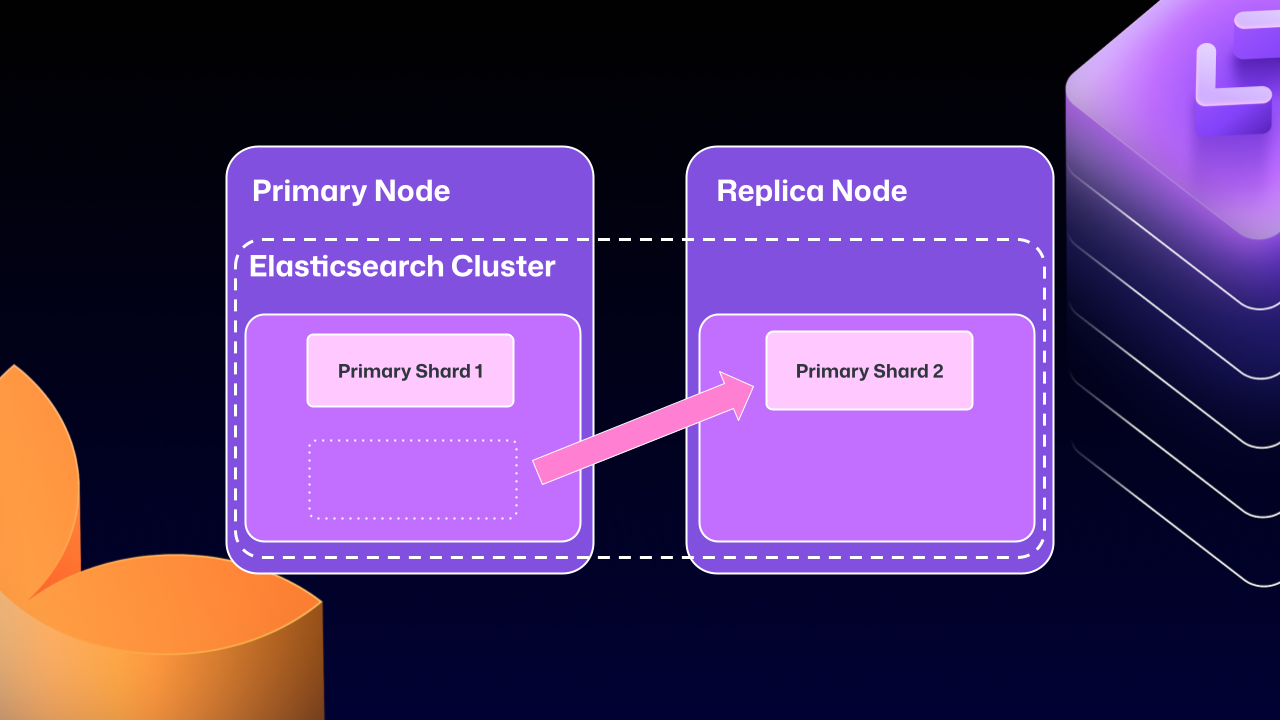
Unfortunately, the problems of clustering across servers eventually began to outweigh the benefits. For example, at any point Elasticsearch could move a primary shard (responsible for receiving/validating writes) to a replica. If that replica was then taken down for maintenance, GitHub Enterprise Server could end up in a locked state. The replica would wait for Elasticsearch to be healthy before starting up, but Elasticsearch couldn’t become healthy until the replica rejoined.
For a number of GitHub Enterprise Server releases, engineers at GitHub tried to make this mode more stable. We implemented checks to ensure Elasticsearch was in a healthy state, as well as other processes to try and correct drifting states. We went as far as attempting to build a “search mirroring” system that would allow us to move away from the clustered mode. But database replication is incredibly challenging and these efforts needed consistency.
After years of work, we’re now able to use Elasticsearch’s Cross Cluster Replication (CCR) feature to support HA GitHub Enterprise.
“But David,” you say, “That’s replication between clusters. How does that help here?”
I’m so glad you asked. With this mode, we’re moving to use several, “single-node” Elasticsearch clusters. Now each Enterprise server instance will operate as independent single node Elasticsearch clusters.
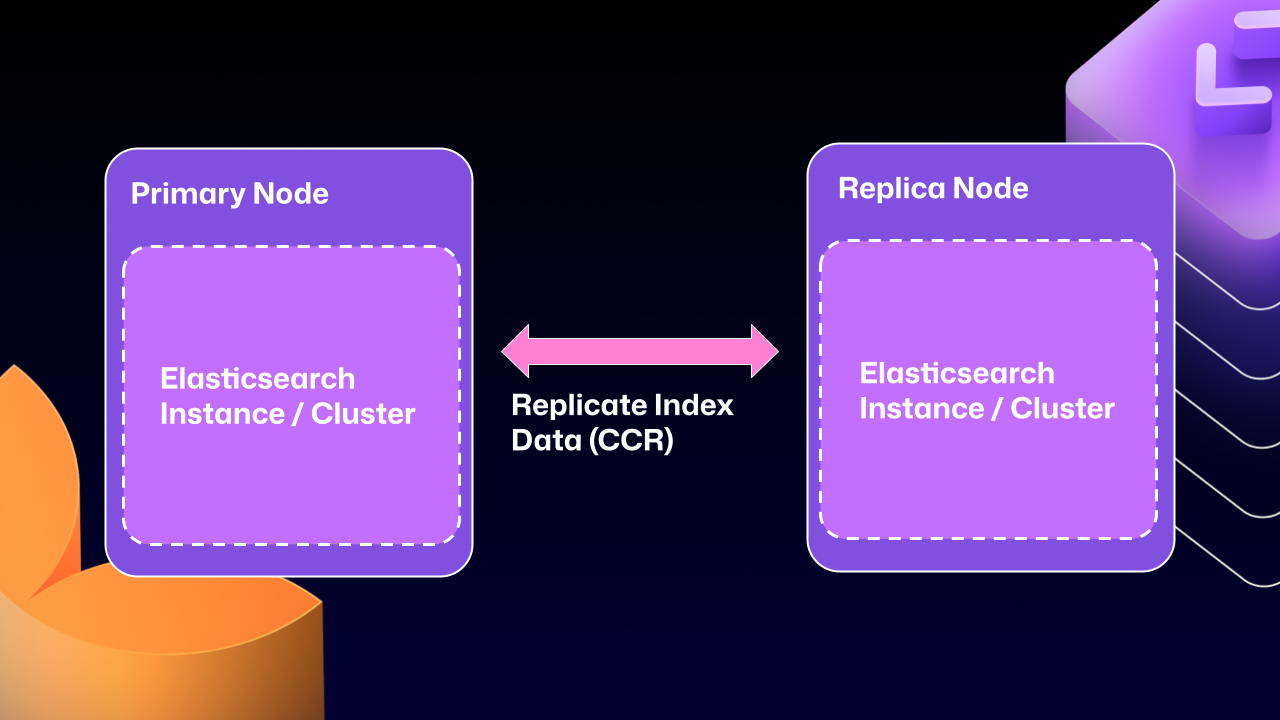
CCR lets us share the index data between nodes in a way that is carefully controlled and natively supported by Elasticsearch. It copies data once it’s been persisted to the Lucene segments (Elasticsearch’s underlying data store). This ensures we’re replicating data that has been durably persisted within the Elasticsearch cluster.
In other words, now that Elasticsearch supports a leader/follower pattern, GitHub Enterprise Server administrators will no longer be left in a state where critical data winds up on read-only nodes.
Elasticsearch has an auto-follow API, but it only applies to indexes created after the policy exists. GitHub Enterprise Server HA installations already have a long-lived set of indexes, so we need a bootstrap step that attaches followers to existing indexes, then enables auto-follow for anything created in the future.
Here’s a sample of what that workflow looks like:
function bootstrap_ccr(primary, replica):
# Fetch the current indexes on each
primary_indexes = list_indexes(primary)
replica_indexes = list_indexes(replica)
# Filter out the system indexes
managed = filter(primary_indexes, is_managed_ghe_index)
# For indexes without follower patterns we need to
# initialize that contract
for index in managed:
if index not in replica_indexes:
ensure_follower_index(replica, leader=primary, index=index)
else:
ensure_following(replica, leader=primary, index=index)
# Finally we will setup auto-follower patterns
# so new indexes are automatically followed
ensure_auto_follow_policy(
replica,
leader=primary,
patterns=[managed_index_patterns],
exclude=[system_index_patterns]
)This is just one of the new workflows we’ve created to enable CCR in GitHub Enterprise Server. We’ve needed to engineer custom workflows for failover, index deletion, and upgrades. Elasticsearch only handles the document replication, and we’re responsible for the rest of the index’s lifecycle.
To get started using the new CCR mode, reach out to support@github.com and let them know you’d like to use the new HA mode for GitHub Enterprise Server. They’ll set up your organization so that you can download the required license.
Once you’ve downloaded your new license, you’ll need to set `ghe-config app.elasticsearch.ccr true`. With that finished, administrators can run a `config-apply` or an upgrade on your cluster to move to 3.19.1, which is the first release to support this new architecture.
When your GitHub Enterprise Server restarts, Elasticsearch will migrate your installation to use the new replication method. This will consolidate all the data onto the primary nodes, break clustering across nodes, and restart replication using CCR. This update may take some time depending on the size of your GitHub Enterprise Server instance.
While the new HA method is optional for now, we’ll be making it our default over the next two years. We want to ensure there’s ample time for GitHub Enterprise administrators to get their feedback in, so now is the time to try it out.
We’re excited for you to start using the new HA mode for a more seamless experience managing GitHub Enterprise Server.
Want to get the most out of search on your High Availability GitHub Enterprise Server deployment? Reach out to support to get set up with our new search architecture!
The post How we rebuilt the search architecture for high availability in GitHub Enterprise Server appeared first on The GitHub Blog.
Continue reading on the original blog to support the author
Read full articleThis report provides a transparent look at large-scale infrastructure migration and service extraction. It highlights the trade-offs between speed and stability, the importance of edge rate-limiting, and how to handle database contention in a massive monolith-to-microservices transition.
This report highlights the challenges of scaling a massive monolith under AI-driven traffic growth. It provides a blueprint for reliability through infrastructure migration, service decomposition, and the implementation of automated circuit breakers to prevent cascading failures.
Git 2.55 brings critical performance enhancements for large-scale repositories. By optimizing multi-pack indexes and connectivity checks, it significantly reduces maintenance overhead and push latency, which is vital for SREs and developers managing massive codebases.
This report highlights the complexity of maintaining high availability in distributed systems. It provides lessons on the risks of automated infrastructure changes, the importance of correctly scoped rate limiting, and the need for robust DNS management and failover strategies.