Scaling graph databases for real-time applications is difficult. Airbnb's move to an internal JanusGraph platform demonstrates how to decouple storage from logic to achieve high performance, reliability, and operational control for massive identity resolution workloads.
How Airbnb shifts from PaaS to an internal knowledge graph infrastructure at scale.

By: Lucen Zhao, Shukun Yang, Ashish Jain
Knowledge graphs offer a natural and powerful way to represent relationships between entities. Many real-world systems are fundamentally about connections.
Airbnb’s identity graph captures relationships between users in a graph database. The identity graph serves aggregated insights that enable user identity resolution and relationship understanding. These capabilities support a wide range of Trust and Safety use cases, from detecting suspicious activities to identifying linked accounts. Over time, the identity graph has grown into one of the largest and most complex graph data products at Airbnb, both in terms of scale and the complexity of queries it supports.
In 2024, Airbnb began investing in a new, internally managed, paved-path graph data platform to build a unified knowledge graph infrastructure. Airbnb’s identity graph became one of the first systems to adopt this platform. In this post, we’ll walk through the foundations and challenges of the identity graph, introduce the architecture behind the graph infrastructure, and highlight several key optimizations that emerged during the onboarding process.
Airbnb’s identity graph is a critical foundation layer, playing an important role in Trust and Safety applications. It contains two major components:
The identity graph architecture progressed through three major iterations. It started with a relational database for user and entity data, paired with a KV store holding JSON‑encoded edge lists, a pattern that became difficult and expensive to scale as graph density increased. A third‑party SaaS graph database replaced the KV store in 2021, improving horizontal scalability but introducing long‑tail latency, operational instability, and limited ability to tune performance or enforce fine‑grained access controls. As part of ongoing system enhancements, the system was migrated to a graph infrastructure: an internally managed, high‑performance graph platform built to support low‑latency, large‑scale graph workloads.
A number of challenges persisted during the evolution of the identity graph:
Before the centrally managed graph infrastructure, graph adoption at Airbnb was fragmented. Teams typically fell into one of four anti-patterns, each with significant operational overhead:
To solve this, we built an internal graph infrastructure, a paved-path, multi-tenant platform designed to bring our use cases together under a single, supported infrastructure.
Graph databases vary widely in storage design, schema models, and query languages. We evaluated options based on four requirements:
We chose JanusGraph (a distributed, open-source graph database built on Apache TinkerPop), with DynamoDB as the storage backend and OpenSearch for indexing. JanusGraph’s labeled property graph model provides strong schema support, and Gremlin enables expressive traversal queries.
This combination offers a unique advantage: Storage separation. Because JanusGraph supports pluggable storage backends, we were able to leverage the scalability and reliability of AWS DynamoDB for the persistence layer while maintaining full control over the graph logic layer. This allowed us to iterate quickly on graph features without reinventing the wheel on distributed storage operations. Moreover, we have the ability to evolve the storage layer over time as our internal persistence platform matures.
Airbnb’s knowledge graph infrastructure provides a managed experience where each tenant (such as the identity graph) operates in an isolated namespace. We built a management service on top of JanusGraph to handle schema enforcement, index management, and schematized Thrift APIs.
To meet Airbnb’s latency requirements, we made several key optimizations to the core JanusGraph engine:
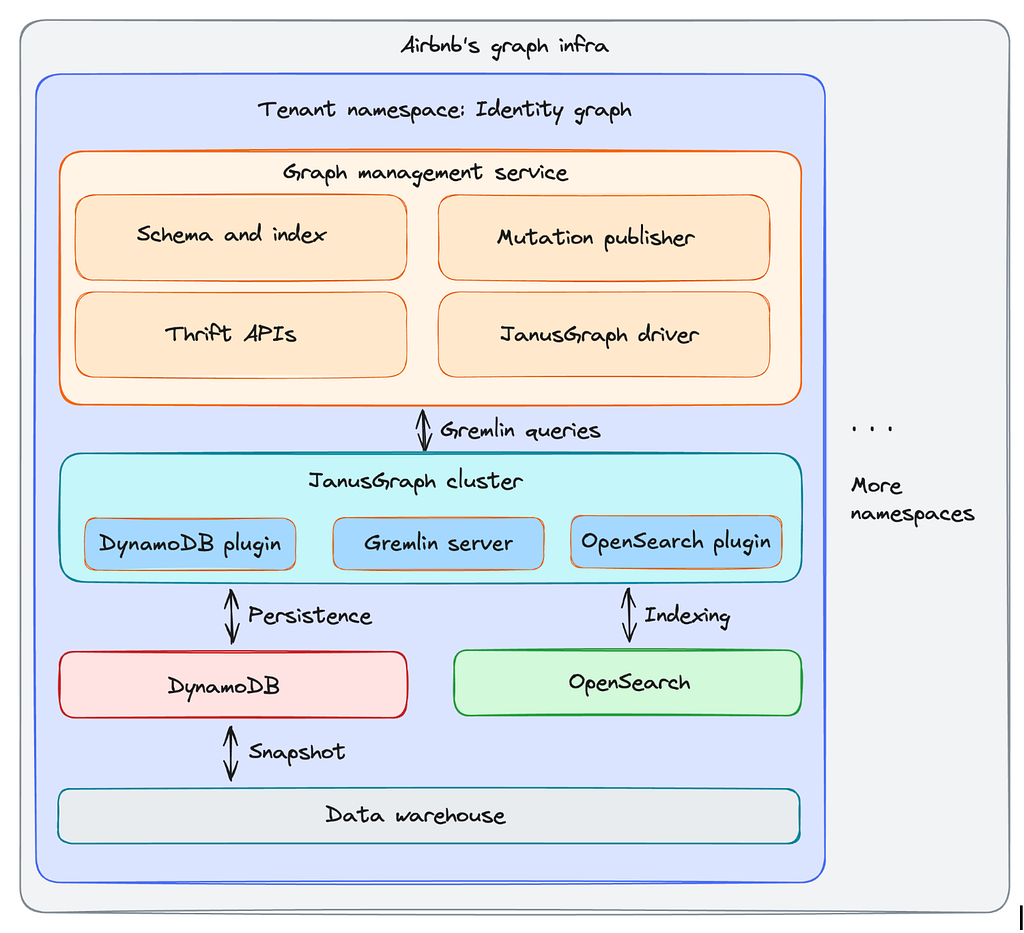
This architecture now supports critical use cases across the company, including fraud detection, inventory knowledge graphs, and data lineage.
We moved from a vendor-provided solution to an internally-built solution based on the open source Apache Tinkerpop graph computing framework, which includes the Gremlin graph query language. The change has delivered considerable improvements in performance and reliability.
The identity graph service consists of four applications: two for event-based data ingestion and bulk loading, another two for data serving and pre-computation of complex graph queries. For both the internal solution and the previous third-party vendor solution, read and write traffic are isolated in the graph computation engine layer.
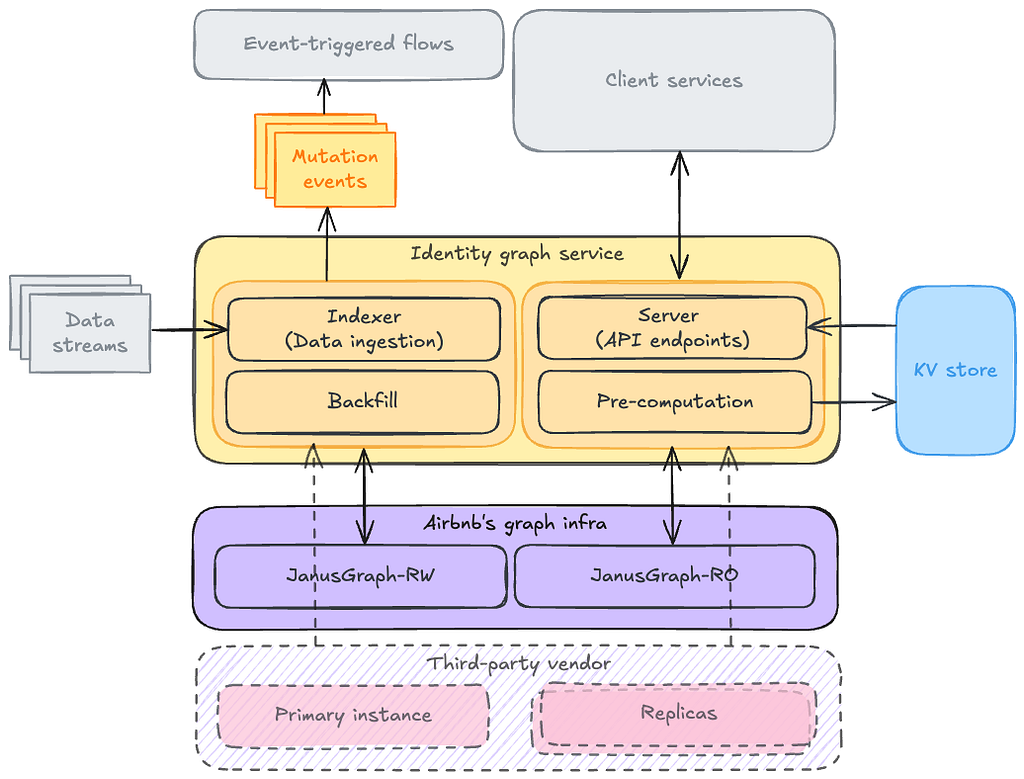
Both graph engines also support Gremlin, enabling us to benchmark Gremlin queries side-by-side when serving shadow traffic. After benchmarking, internal graph infrastructure was used to start serving production traffic before the vendor solution was deprecated.
Even though both graph engines support the Gremlin query language, they applied very different optimizations over TinkerPop query steps during the query planning phase. Thus, during the migration, identical Gremlin queries produced significantly different performance between Airbnb’s graph infrastructure and the third party vendor. To address this and enhance the performance of graph queries, optimizations were made on both the JanusGraph side and the client side.
Client-side optimization included a series of query rewriting improvements, including:
Integrating the identity graph with the internal infrastructure has delivered meaningful improvements in performance, stability, and scalability:
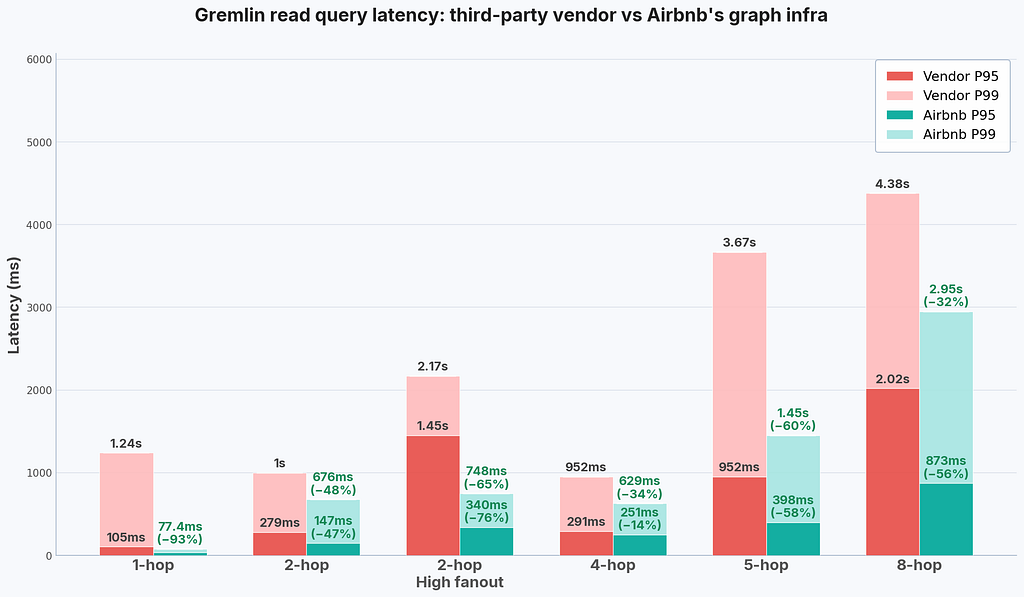
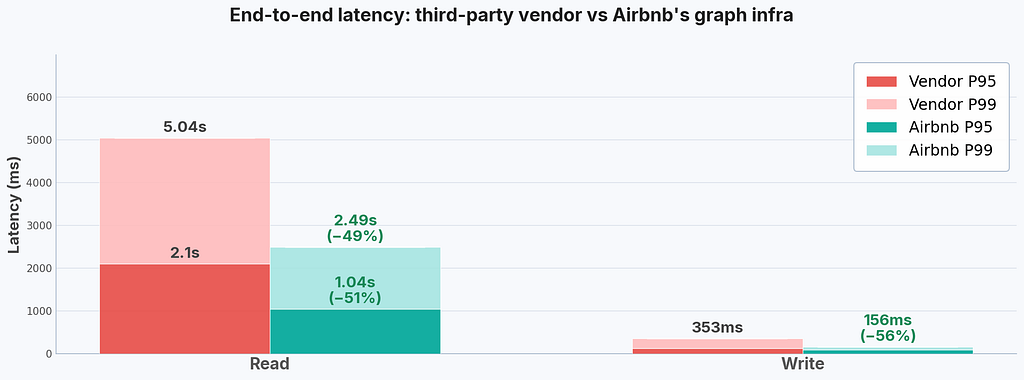
Airbnb’s knowledge graph has demonstrated significant improvement in both query performance and system stability compared to the third-party vendor identity graph we had been relying on. Enabling multi-step queries in a broader range of queries in JanusGraph has improved overall query performance, while client-side query optimizations helped greatly in shrinking long-tail query latency. Our ability to manage the new system internally enables faster and more transparent incident investigations.
If this type of work interests you, check out some of our open roles.
Special thanks to Pawan Rathi, Zach Fein, Cong Zhao, Peter Li, Haiyang Han, Jisheng Liang, Abhishek Ravi, Yi Li, Adam Kocoloski, Kaushik Srinivasan, and everyone else who supported this project. The infrastructure upgrade would not be such a huge success without contributions from these people.
We also want to thank Primus Lam and Rajan Jon for their support in authoring this post during their time at Airbnb.
All product names, logos, and brands are property of their respective owners. All company, product, and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.
Scaling Airbnb’s identity graph with a unified knowledge graph infrastructure was originally published in The Airbnb Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleThis article provides a blueprint for scaling data architecture during rapid product expansion. It demonstrates how to balance consistency and flexibility through a principled framework, preventing technical debt and data silos while supporting diverse business requirements.
Viaduct offers a middle ground between monolithic GraphQL and complex Federation by allowing teams to contribute to a shared schema via modules. This reduces operational overhead while maintaining developer autonomy, making it easier to scale data access across large organizations.
Scaling observability for 1,000+ services requires balancing multi-tenant isolation with operational efficiency. Airbnb's approach to shuffle sharding and automated control planes provides a blueprint for building resilient, petabyte-scale metrics systems that avoid 'flying blind' during outages.
This architecture demonstrates how to build social features without compromising privacy. By decoupling internal identities from public profiles, engineers can provide granular user control and prevent unintended data leakage across different product contexts.