This article details how a large-scale key-value store was rearchitected to meet modern demands for real-time data, scalability, and operational efficiency. It offers valuable insights into addressing common distributed system challenges and executing complex migrations.

How we completely rearchitected Mussel, our storage engine for derived data, and lessons learned from the migration from Mussel V1 to V2.
By Shravan Gaonkar, Chandramouli Rangarajan, Yanhan Zhang
How we completely rearchitected Mussel, our storage engine for derived data, and lessons learned from the migration from Mussel V1 to V2.
Airbnb’s core key-value store, internally known as Mussel, bridges offline and online workloads, providing highly scalable bulk load capabilities combined with single-digit millisecond reads.
Since first writing about Mussel in a 2022 blog post, we have completely deprecated the storage backend of the original system (what we now call Mussel v1) and have replaced it with a NewSQL backend which we are referring to as Mussel v2. Mussel v2 has been running successfully in production for a year, and we wanted to share why we undertook this rearchitecture, what the challenges were, and what benefits we got from it.
Mussel v1 reliably supported Airbnb for years, but new requirements — real-time fraud checks, instant personalization, dynamic pricing, and massive data — demand a platform that combines real-time streaming with bulk ingestion, all while being easy to manage.
Mussel v2 solves a number of issues with v1, delivering a scalable, cloud-native key-value store with predictable performance and minimal operational overhead.

Mussel v2 is a complete re-architecture addressing v1’s operational and scalability challenges. It’s designed to be automated, maintainable, and scalable, while ensuring feature parity and an easy migration for 100+ existing user cases.
In Mussel v2, the Dispatcher is a stateless, horizontally-scalable Kubernetes service that replaces the tightly coupled, protocol-specific design of v1. It translates client API calls into backend queries/mutations, supports dual-write and shadow-read modes for migration, manages retries and rate limits, and integrates with Airbnb’s service mesh for security and service discovery.
Reads are simplified: Each dataname maps to a logical table, enabling optimized point lookups, range/prefix queries, and stale reads from local replicas to reduce latency. Dynamic throttling and prioritization maintain performance under changing traffic.
Writes are persisted in Kafka for durability first, with the Replayer and Write Dispatcher applying them in order to the backend. This event-driven model absorbs bursts, ensures consistency, and removes v1’s operational overhead. Kafka also underpins upgrades, bootstrapping, and migrations until CDC and snapshotting mature.
The architecture suits derived data and replay-heavy use cases today, with a long-term goal of shifting ingestion and replication fully to the distributed backend database to bring down latency and simplify operations.
Bulk load
Bulk load remains essential for moving large datasets from offline warehouses into Mussel for low-latency queries. v2 preserves v1 semantics, supporting both “merge” (add to existing tables) and “replace” (swap datasets) semantics.
To maintain a familiar interface, v2 keeps the existing Airflow-based onboarding and transforms warehouse data into a standardized format, uploading to S3 for ingestion. Airflow is an open-source platform for authoring, scheduling, and monitoring data pipelines. Created at Airbnb, it lets users define workflows in code as directed acyclic graphs (DAGs), enabling quick iteration and easy orchestration of tasks for data engineers and scientists worldwide.
A stateless controller orchestrates jobs, while a distributed, stateful worker fleet (Kubernetes StatefulSets) performs parallel ingestion, loading records from S3 into tables. Optimizations — like deduplication for replace jobs, delta merges, and insert-on-duplicate-key-ignore — ensure high throughput and efficient writes at Airbnb scale.
Automated data expiration (TTL) can help support data governance goals and storage efficiency. In v1, expiration relied on the storage engine’s compaction cycle, which struggled at scale.
Mussel v2 introduces a topology-aware expiration service that shards data namespaces into range-based subtasks processed concurrently by multiple workers. Expired records are scanned and deleted in parallel, minimizing sweep time for large datasets. Subtasks are scheduled to limit impact on live queries, and write-heavy tables use max-version enforcement with targeted deletes to maintain performance and data hygiene.
These enhancements provide the same retention functionality as v1 but with far greater efficiency, transparency, and scalability, meeting Airbnb’s modern data platform demands and enabling future use cases.
Mussel stores vast amounts of data and serves thousands of tables across a wide array of Airbnb services, sustaining mission-critical read and write traffic at high scale. Given the criticality of Mussel to Airbnb’s online traffic, our migration goal was straightforward but challenging: Move all data and traffic from Mussel v1 to v2 with zero data loss and no impact on availability to our customers.
We adopted a blue/green migration strategy, but with notable complexities. Mussel v1 didn’t provide table-level snapshots or CDC streams, which are standard in many datastores. To bridge this gap, we developed a custom migration pipeline capable of bootstrapping tables to v2, selected by usage patterns and risk profiles. Once bootstrapped, dual writes were enabled on a per-table basis to keep v2 in sync as the migration progressed.
The migration itself followed several distinct stages:
To further de-risk the process, migration was performed one table at a time. Every step was reversible and could be fine-tuned per table or group of tables based on their risk profile. This granular, staged approach allowed for rapid iteration, safe rollbacks, and continuous progress without impacting the business.
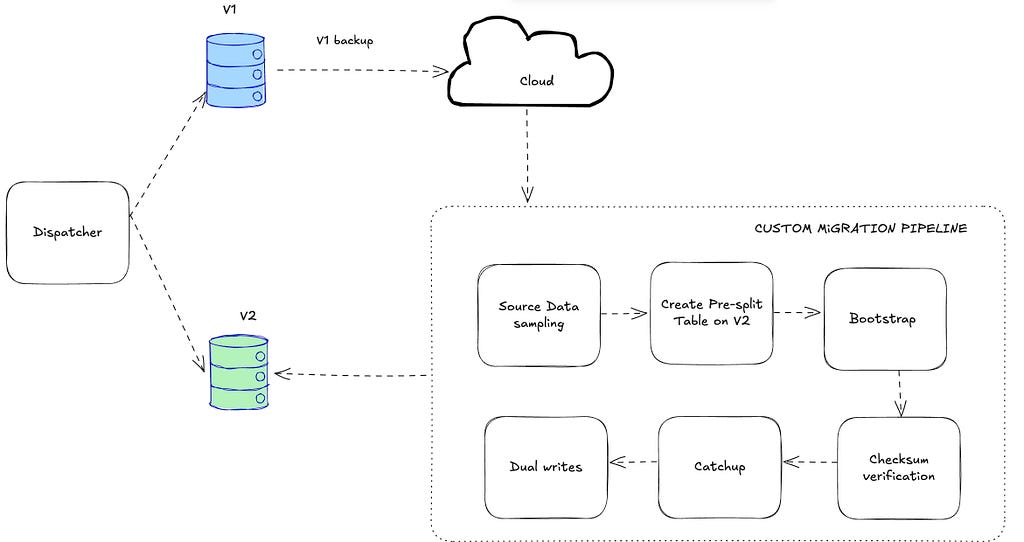
As described in our previous blog post, the v1 architecture uses Kafka as a replication log — data is first written to Kafka, then consumed by the v1 backend. During the data migration to v2, we leveraged the same Kafka stream to maintain eventual consistency between v1 and v2.
To migrate any given table from v1 to v2, we built a custom pipeline consisting of the following steps:
Once data migration is complete and we enter dual write mode, we can begin the read traffic migration phase. During this phase, our dispatcher can be dynamically configured to serve read requests for specific tables from v1, while sending shadow requests to v2 for consistency checks. We then gradually shift to serving reads from v2, accompanied by reverse shadow requests to v1 for consistency checks, which also enables quick fallback to v1 responses if v2 becomes unstable. Eventually, we fully transition to serving all read traffic from v2.
Several key insights emerged from this migration:
As a result, we migrated more than a petabyte of data across thousands of tables with zero downtime or data loss, thanks to a blue/green rollout, dual-write pipeline, and automated fallbacks — so the product teams could keep shipping features while the engine under them evolved.
What sets Mussel v2 apart is the way it fuses capabilities that are usually confined to separate, specialized systems. In our deployment of Mussel V2, we observe that this system can simultaneously
— all while giving callers a simple dial to toggle stale reads on a per-namespace basis. By pairing a NewSQL backend with a Kubernetes-native control plane, Mussel v2 delivers the elasticity of object storage, the responsiveness of a low-latency cache, and the operability of modern service meshes — rolled into one platform. Engineers no longer need to stitch together a cache, a queue, and a datastore to hit their SLAs; Mussel provides those guarantees out of the box, letting teams focus on product innovation instead of data plumbing.
Looking ahead, we’ll be sharing deeper insights into how we’re evolving quality of service (QoS) management within Mussel, now orchestrated cleanly from the Dispatcher layer. We’ll also describe our journey in optimizing bulk loading at scale — unlocking new performance and reliability wins for complex data pipelines. If you’re passionate about building large-scale distributed systems and want to help shape the future of data infrastructure at Airbnb, take a look at our Careers page — we’re always looking for talented engineers to join us on this mission.
Building a Next-Generation Key-Value Store at Airbnb was originally published in The Airbnb Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleViaduct offers a middle ground between monolithic GraphQL and complex Federation by allowing teams to contribute to a shared schema via modules. This reduces operational overhead while maintaining developer autonomy, making it easier to scale data access across large organizations.
Scaling observability for 1,000+ services requires balancing multi-tenant isolation with operational efficiency. Airbnb's approach to shuffle sharding and automated control planes provides a blueprint for building resilient, petabyte-scale metrics systems that avoid 'flying blind' during outages.
This article showcases a successful approach to managing a large, evolving data graph in a service-oriented architecture. It provides insights into how a data-oriented service mesh can simplify developer experience, improve modularity, and scale efficiently.
This article provides a detailed blueprint for achieving high availability and fault tolerance for distributed databases on Kubernetes in a multi-cloud environment. Engineers can learn best practices for managing stateful services, mitigating risks, and designing resilient systems at scale.