Dynamic configuration is critical for feature flags and runtime tuning. Airbnb's sidecar approach ensures high availability and low latency across a massive, multi-language microservice architecture, decoupling config delivery from service deployments and backend availability.

By: Bo Teng, Cosmo Qiu, Siyuan Zhou, Ankur Soni, Xin Huang, Willis Harvey
In our previous post, we explored Airbnb’s dynamic configuration system, Sitar, with a focus on service architecture and configuration change safety. Now for the harder question: once a config change is committed, which happens several times each minute, how does it actually reach the thousands of Airbnb’s service instances reliably, quickly, and without redeploying the services?
This post describes sitar agent: a lightweight Kubernetes sidecar that runs alongside every subscribed service pod, continuously synchronizing the latest configurations from the service backend and making them available on the local filesystem for reads. In this post, we will first go through the configuration delivery life cycle, and then discuss some key design choices for the sitar-agent sidecar.
The diagram below illustrates the end-to-end journey of a configuration change, from the developer-facing layer to the production service fleet.
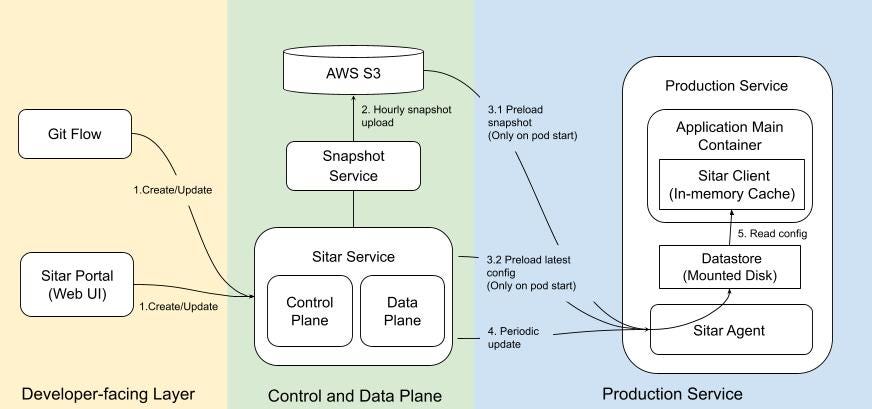
Step 1 — Config creation/update
Developers create or update configuration values through either Git flow or the web UI. These changes are committed to the Sitar Service, where they are stored with full versioning, change logs, and ACL enforcement.
Step 2 — Hourly snapshot upload
The Snapshot Service periodically packages the full state of all config groups and uploads compressed snapshots to AWS S3.
Step 3.1 — Preload snapshot from S3 (on pod startup)
When a production service pod starts, the sitar-agent sidecar runs first. It downloads the latest snapshot for each subscribed tenant’s configs from S3 to the mounted disk (shared between sitar-agent and the main container). This allows the agent to bootstrap from a known-good state without fetching every config from the Sitar Service from scratch on every restart. Preloading the snapshots from S3 enables faster restarts, makes the service resilient to transient Sitar Service unavailability, and avoids load spikes during deployments.
Step 3.2 — Preload latest config from Sitar Service (on pod startup)
After loading the S3 snapshot, the agent performs an initial sync with the Sitar Service to catch up on any changes published since the last snapshot. Once this step succeeds, the agent signals readiness, unblocking the application main container from starting.
Step 4 — Periodic update
After startup, the agent enters a continuous polling loop (order of seconds with jitter). On each cycle, the sitar agent queries the Sitar Service for changes across all subscribed groups.
Step 5 — Read config
The application main container reads configurations from the mounted disk through the Sitar client library, which maintains an in-memory cache. The client detects file changes and refreshes its cache transparently.
With the delivery lifecycle in mind, the following sections walk through the major architectural choices that shaped the sidecar’s design.
In 2024, the sitar-agent underwent a full rewrite from Ruby to Java, Airbnb’s mainstream JVM language, giving the team an opportunity to modernize the architecture alongside the language migration. The snapshot-based S3 preload introduced in the previous section is one outcome of this effort: it dramatically reduces cold start time for the pod and decouples startup reliability from Sitar Service availability. The rewrite also led to several other deliberate design decisions around reliability, performance, and operational safety. The sections below walk through each of these choices.
Before diving into specific design choices, it helps to understand the constraints that shaped every decision. At Airbnb, dynamic configuration delivery isn’t just a convenience: it controls critical features across thousands of services. That means configs must always be available, even when the Sitar Service itself is down; a slightly stale value is tolerable, but an unreadable config is not. At the same time, when an engineer pushes a change, it needs to reach every subscribed service within tens of seconds, not minutes. Making that work at scale is non-trivial: with tens of thousands of pods fetching updates simultaneously, the system has to absorb that load without degrading. And since Airbnb’s service fleet spans Java, Python, Go, Typescript, and Ruby, the solution needs to serve all of them, ideally minimizing the effort of maintaining separate per-language implementations.
The above requirements for reliability, performance, scalability, and multi-language support aren’t independent. As you’ll see, most of our design decisions, described below, come back to balancing one against another.
The question of whether sitar-agent should run as a sidecar container or a process in the main container surfaced as a key architectural decision during the Java rewrite. We evaluated the pros and cons of each option as follows:
Pros of moving to the main container:
Cons of moving to the main container:
Decision:
Despite the cost savings and reduced operational surface which would result from moving the sitar-agent logic to the main container, the projected savings were insufficient to justify the tradeoffs in reliability and operational overhead, and the development overhead of supporting the sidecar logic in multiple languages. We therefore decided to maintain the sitar-agent as an isolated sidecar container.
Sitar-agent fetches configuration updates by polling the Sitar service every 10 seconds. This is a pull model: the agent drives the update cycle by periodically asking the server for changes. This pull-based architecture, while being simple and easy to maintain, generates unnecessary load on the server when there is no update needed.
A push-based architecture change can greatly reduce the server-side load and change propagation time, at the expense of a more complicated architecture. In order to keep the current simple architecture while reducing the service-side load, the sitar system implements the following optimizations:
Given the above optimizations, the sitar-service can scale and perform quite well in handling the pull request from all service pods at Airbnb, and we can preserve the simple, stateless server-with-pull architecture.
Decision:
For sitar’s use case, polling latency on the order of seconds is acceptable; dynamic config is not a real-time signaling mechanism, and most config changes are manual, making a few seconds of propagation delay inconsequential. The pull model’s stateless simplicity is a strong operational advantage at Airbnb’s scale. The team elected to keep the pull model and invest instead in reducing per-poll cost.
Sitar-agent maintains a local on-disk key-value store that the main container reads from. The legacy datastore is a Sparkey-backed internal implementation, with a thin layer around the Sparkey datastore for concurrent coordination. As the usage of Sitar continues to grow and evolve, the mismatch of the Sparkey-backed datastore and sitar’s needs have become evident:
The team evaluated and benchmarked two candidates to replace the legacy Sparkey-based datastore: SQLite and RocksDB. A matrix of experiments were run across varying dataset sizes, read QPS, and memory allocations, fixing two of the three dimensions and varying the third in each run. We also researched community support, open source activity, supported languages, and adoption breadth of both. The following summarizes our findings:
SQLite:
Pros:
Cons:
RocksDB:
Pros:
Cons:
Decision:
In our tests, both RocksDB and SQLite significantly outperform Sparkey-backed datastores for our workload across all three test dimensions: data size, memory allocation, and read QPS. While RocksDB delivers better raw performance, sitar-agent’s workload operates comfortably within SQLite’s envelope. SQLite’s first-class multi-language library support, native WAL-based concurrent access model, and simpler operational footprint made it the better overall fit for a team supporting multiple language runtimes. The team selected SQLite as the replacement for the Sparkey-backed datastore.
Safe migration from Sparkey to SQLite
Operational safety was a top priority. Beyond extensive testing, we also we relied on two mechanisms to keep the rollout safe:
Sitar-agent sits at the core of Airbnb’s dynamic configuration delivery system. This post walked through how it works and the key tradeoffs we navigated during the Java rewrite: between cost and isolation, simplicity and push-based efficiency, and raw performance and operational practicality. Every decision came back to the same constraints: configs must always be available, changes must propagate quickly across a fleet of tens of thousands of pods, and the solution must work across Airbnb’s polyglot service stack without compounding the maintenance burden.
If this type of work interests you, check out some of our related positions!
Our progress with Sitar would not have been possible without the support and contributions of many people. We’d like to thank Craig Sosin, Nikolaj Nielsen, Daniel Fagnan, Alex Edwards, Nick Morgan, Carolina Calderon, Hanfei Lin, Yunong Liu, Lucas Rosa Galego, Yann Ramin, Denis Sheahan, Richa Khandelwal, Swetha Vaidy, Adam Kocoloski, Adam Miskiewicz, and all the other engineers and teams at Airbnb who joined design reviews and offered valuable feedback, as this work would not have been possible without them.
All product names, logos, and brands are property of their respective owners. All company, product, and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.
Sitar-agent: Building a reliable dynamic configuration sidecar at scale was originally published in The Airbnb Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Continue reading on the original blog to support the author
Read full articleViaduct offers a middle ground between monolithic GraphQL and complex Federation by allowing teams to contribute to a shared schema via modules. This reduces operational overhead while maintaining developer autonomy, making it easier to scale data access across large organizations.
Observability must be more reliable than the systems it monitors. By breaking circular dependencies in compute and networking, engineers ensure visibility remains during critical outages, preventing 'dark' dashboards when they are needed most for recovery.
Skipper offers a lightweight alternative to heavy orchestrators like Temporal. It allows engineers to build reliable, multi-step processes using existing infrastructure, significantly reducing operational complexity while maintaining high reliability for critical transactions.
Scaling observability for 1,000+ services requires balancing multi-tenant isolation with operational efficiency. Airbnb's approach to shuffle sharding and automated control planes provides a blueprint for building resilient, petabyte-scale metrics systems that avoid 'flying blind' during outages.