This article details how Meta built and scaled a massive LLM-inspired foundation model for ads, showcasing innovations in architecture, training, and knowledge transfer for significant performance gains. It offers insights into building large-scale recommendation systems.
Meta has been at the forefront of harnessing AI across our products and services to drive business value for advertisers. Leveraging advanced techniques to personalize ads for people and maximize the performance of each ad impression is an integral part of how we develop our Ads Recommendation system.
The Generative Ads Recommendation Model (GEM) is Meta’s most advanced ads foundation model, built on an LLM-inspired paradigm and trained across thousands of GPUs. It is the largest foundation model for recommendation systems (RecSys) in the industry, trained at the scale of large language models. GEM introduces architectural innovations that unlock efficient scaling laws, delivering performance gains that scale cost-effectively with data and compute. Training breakthroughs such as multi-dimensional parallelism, custom GPU kernels, and memory optimizations make it feasible to train GEM at its scale. Post-training, GEM applies advanced knowledge transfer techniques to amplify the performance of downstream models across the entire ads stack, delivering more relevant and personalized ad experiences aligned with people’s preferences. Since launching GEM earlier this year, GEM’s launch across Facebook and Instagram has delivered a 5% increase in ad conversions on Instagram and a 3% increase in ad conversions on Facebook Feed in Q2.
In Q3, we made improvements to GEM’s model architecture that doubled the performance benefit we get from adding a given amount of data and compute. This will enable us to continue scaling up the amount of training capacity we use on GEM at an attractive ROI.
GEM represents a significant advancement in RecSys through three key innovations: model scaling with advanced architecture, post-training techniques for knowledge transfer, and enhanced training infrastructure to support scalability. These innovations efficiently boost ad performance, enable effective knowledge sharing across the ad model fleet, and optimize the use of thousands of GPUs for training. GEM has driven a paradigm shift in ads RecSys, transforming ad performance across the funnel — awareness, engagement, and conversion — through joint optimization of both user and advertiser objectives.
Building a large foundation model for Meta’s ads RecSys requires addressing several key challenges:
GEM overcomes these challenges through:
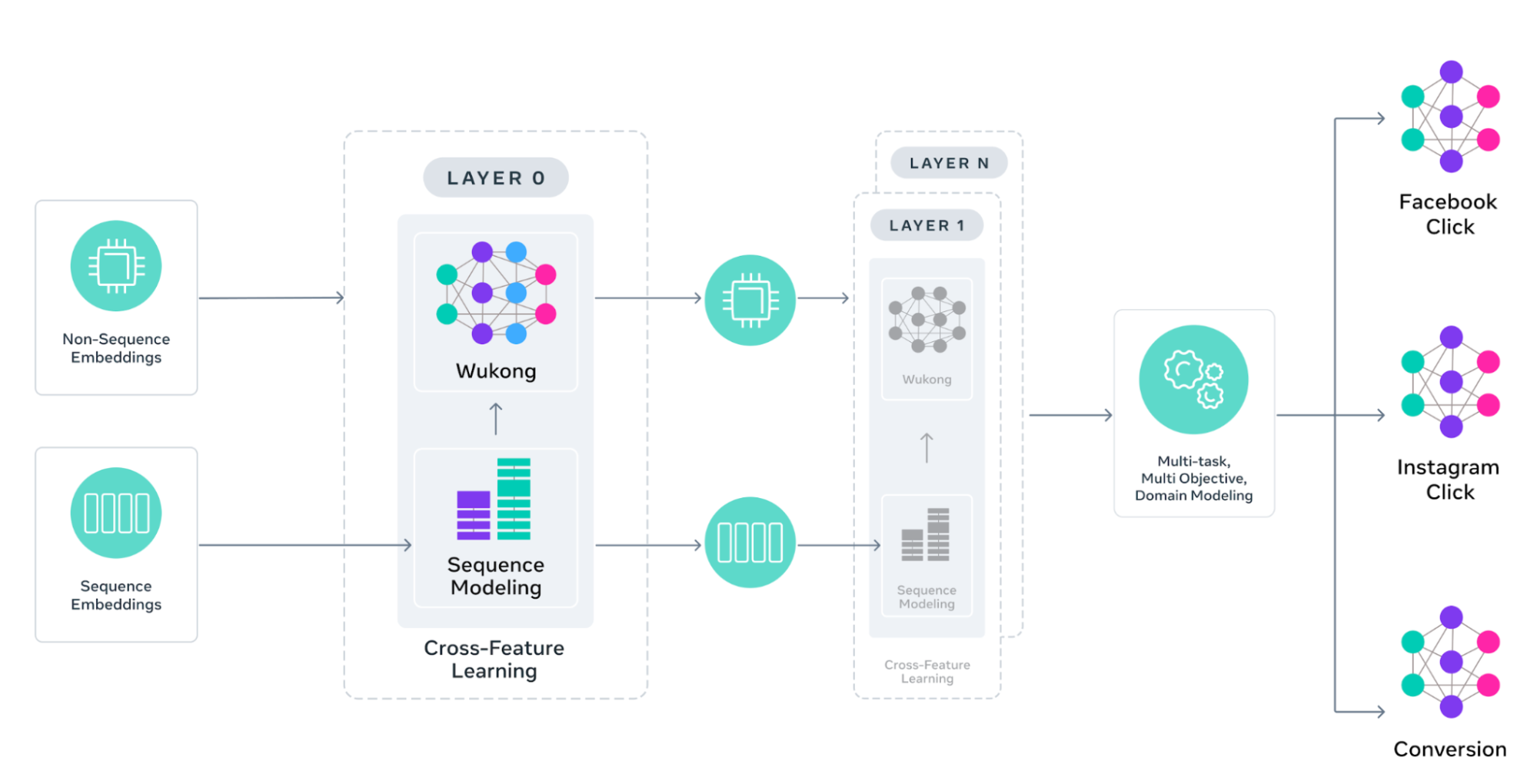
GEM is trained on ad content and user engagement data from both ads and organic interactions. From this data, we derive features that we categorize into two groups: sequence features (such as activity history) and non-sequence features (such as user and ad attributes — e.g., age, location, ad format, and creative representation). Customized attention mechanisms are applied to each group independently, while also enabling cross-feature learning. This design improves accuracy and scales both the depth and breadth of each attention block, delivering 4× the efficiency of our previous generation of models.

Understanding how user attributes interact with ad characteristics is crucial for accurate recommendations. GEM enhances the Wukong architecture to use stackable factorization machines with cross-layer attention connections, allowing the model to learn which feature combinations matter most. Each Wukong block can scale vertically (for deeper interactions) and horizontally (for broader feature coverage), enabling the discovery of increasingly complex user-ad patterns.
User behavior sequences — spanning long sequences of ad / content clicks, views, and interactions — contain rich signals about preferences and intent, yet traditional architectures struggle to process such long sequences efficiently. GEM overcomes this challenge with a pyramid-parallel structure, stacking multiple parallel interaction modules in a pyramid formation to capture complex user-ad relationships at scale. The new scalable offline feature infrastructure processes sequences of up to thousands of events with minimal storage cost, so GEM can learn from a much longer history of user organic and ad interactions. By modeling these extended user behavior sequences, GEM can more effectively uncover patterns and relationships, resulting in a deeper and more accurate understanding of the user’s purchase journey.
Existing approaches compress user behavior sequences into compact vectors for downstream tasks, which risks losing critical engagement signals. GEM takes a different approach that preserves full sequence information while enabling efficient cross-feature learning. Our design, InterFormer, employs parallel summarization with an interleaving structure that alternates between sequence learning (e.g., custom transformer architecture) and cross-feature interaction layers. This allows progressively refining its sequence understanding while maintaining access to the complete user journey. This design facilitates efficient interaction learning while preserving the structural integrity of user sequence data — enabling GEM to scale to higher layer counts without losing critical behavioral signals.
Traditional ad recommendation systems struggle to balance learning across a broad product ecosystem — treating surfaces either in isolation (thus missing valuable cross-platform insights) or identically (ignoring platform-specific behaviors). Different Meta surfaces like Facebook, Instagram, and Business Messaging each have unique user behaviors and interaction patterns. GEM solves this through learning from cross-surface user interactions while ensuring predictions remain tailored to each surface’s unique characteristics. For example, this enables GEM to use insights from Instagram video ad engagement to improve Facebook Feed ad predictions, while also optimizing each domain’s predictions for its specific objective (such as clicks or conversions).
GEM only delivers impact if its knowledge can be efficiently transferred to hundreds of user-facing vertical models (VMs). To translate the performance of the GEM foundation model (FM) into measurable gains for user-facing VMs, we employ both direct and hierarchical knowledge transfer strategies.
Direct transfer enables GEM to transfer knowledge to major VMs within the same data spaces where GEM was trained. Hierarchical transfer distills knowledge from GEM into domain-specific FMs, which then teach VMs, driving broad improvements across ad models. Together, these approaches use a suite of techniques, including knowledge distillation, representation learning, and parameter sharing to maximize transfer efficiency across the entire ad model space, achieving 2x the effectiveness of standard knowledge distillation.
In Meta’s ads system, VMs often suffer from stale supervision caused by delays in FM training and evaluation as well as domain mismatches between GEM or FM predictions and the VMs’ surface-specific objectives. These outdated or misaligned signals between the VMs (students) and GEM (the teacher) can degrade the accuracy and adaptability of student models over time.
To address this, we use a Student Adapter during training, a lightweight component that refines the teacher’s outputs using the most recent ground-truth data. It learns a transformation that better aligns teacher predictions with observed outcomes, ensuring that student models receive more up-to-date and domain-relevant supervision throughout training.
Representation learning is the process by which models automatically drive meaningful and compact features from raw data, enabling more effective downstream tasks like ad click prediction. Representation learning complements knowledge distillation by generating semantically aligned features that support efficient knowledge transfer from teacher to student models. With this approach GEM can effectively improve FM-to-VM transfer efficiency without adding inference overhead.
Parameter sharing is a technique in which multiple models or components reuse the same set of parameters to reduce redundancy, improve efficiency, and facilitate knowledge transfer.
In our context, parameter sharing enables efficient knowledge reuse by allowing VMs to selectively incorporate components from FMs. This lets smaller, latency-sensitive VMs leverage the rich representations and pre-learned patterns of FMs without incurring their full computational cost.
GEM operates at a scale typically only seen by modern LLMs. Training GEM required a complete overhaul of our training recipes. The re-engineered training stack delivers a 23x increase in effective training FLOPs using 16x more GPUs while also improving efficiency. MFU, a key measure of hardware efficiency, increased by 1.43x, reflecting better use of GPU resources. This ability to increase both throughput and efficiency is important to training foundation models of this scale.
To support massive model sizes and multimodal workloads, we employ strategies such as multi-dimensional parallelism, custom GPU kernels, and model-system co-design. These techniques enable near-linear scaling, applied to thousands of GPUs, improving compute throughput, memory usage, and overall hardware efficiency.
Training large models, like GEM, requires carefully orchestrated parallelism strategies across both dense and sparse components. For the dense parts of the model, techniques like Hybrid Sharded Distributed Parallel (HSDP) optimize memory usage and reduce communication costs, enabling efficient distribution of dense parameters across thousands of GPUs. In contrast, the sparse components — primarily large embedding tables used for user and item features — employ a two-dimensional approach using data parallelism and model parallelism, optimized for synchronization efficiency and memory locality.
Beyond parallelism, we implemented a suite of techniques to saturate GPU compute throughput and reduce training bottlenecks:
To improve training agility and minimize GPU idleness, we optimized effective training time (ETT) — the proportion of training time spent processing new data. We reduced job startup time by 5x through optimizing trainer init, data reader setup, checkpointing, and PyTorch 2.0 compilation time, etc. Notably we reduced PyTorch 2.0 compilation time by 7x via caching strategies.
GPU efficiency is optimized across all stages of the model lifecycle — from early experimentation to large-scale training and post-training. In the exploration phase, we accelerate iteration using lightweight model variants at a much lower cost compared to full-sized models. These variants support over half of all experiments, enabling faster idea validation with minimal resource overhead. During the post-training stage, the model runs forward passes to generate knowledge, including labels and embeddings, for downstream models. Unlike in large language models, we also perform continuous online training to refresh the FMs. We enhance traffic sharing between training and post-training knowledge generation, as well as between the foundation model and downstream models, to reduce computational demand. Additionally, GPU efficiency optimization has been applied across all stages to improve end-to-end system throughput.
The future of ads recommendation systems will be defined by a deeper understanding of people’s preferences and intent, making every interaction feel personal. For advertisers, this translates into one-to-one connections at scale, driving stronger engagement and outcomes.
Looking ahead, GEM will learn from Meta’s entire ecosystem including user interactions on organic and ads content across modalities such as text, images, audio, and video. These learnings from GEM will be extended to cover all major surfaces across Facebook and Instagram. This stronger multimodal foundation helps GEM capture nuances behind clicks, conversions, and long-term value, paving the way for a unified engagement model that can intelligently rank both organic content and ads, delivering maximum value for people and advertisers.
We will continue to scale GEM and train on even larger clusters by advancing its architecture and advancing training recipes on the latest AI hardware, enabling it to learn efficiently from more data with diverse modalities to deliver precise predictions. We will also evolve GEM to reason with inference-time scaling to optimize compute allocation, power intent-centric user journeys, and enable agentic, insight-driven advertiser automation that drive higher ROAS.
We would like to thank Yasmine Badr, John Bocharov, Shuo Chang, Laming Chen, Wenlin Chen, Wentao Duan, Xiaorui Gan, Shuo Gu, Mengyue Hang, Yuxi Hu, Yuzhen Huang, Shali Jiang, Santanu Kolay, Zhijing Li, Boyang Liu, Rocky Liu, Xi Liu, Liang Luo, GP Musumeci, Sandeep Pandey, Richard Qiu, Jason Rudy, Vibha Sinha, Matt Steiner, Musharaf Sultan, Chonglin Sun, Viral Vimawala, Ernest Wang, Xiaozhen Xia, Jackie (Jiaqi) Xu, Fan Yang, Xin Zhang, Buyun Zhang, Zhengyu Zhang, Qinghai Zhou, Song Zhou, Zhehui Zhou, Rich Zhu and the entire team behind the development and productionization of the largest foundation model in Meta’s ads recommendation system.
The post Meta’s Generative Ads Model (GEM): The Central Brain Accelerating Ads Recommendation AI Innovation appeared first on Engineering at Meta.
Continue reading on the original blog to support the author
Read full articleThis research addresses the challenge of sparse signal optimization in massive-scale recommendation systems. By using hierarchical graph learning and multimodal enrichment, engineers can improve deep funnel performance and better align user intent with content in high-sparsity environments.
Storage bottlenecks are a primary cause of GPU stalls in AI workloads. Optimizing BLOB storage for low-latency retrieval is critical for maximizing expensive compute utilization and accelerating the development of frontier models.
SilverTorch breaks the performance ceiling of microservice-based recommendation systems. By unifying retrieval into a single GPU-accelerated model, engineers can reduce latency, lower TCO, and eliminate the friction between ML and infrastructure development cycles.
REA shifts ML engineering from manual experimentation to high-level strategy. By automating long-horizon tasks like hypothesis generation and debugging, it significantly increases model accuracy and engineering throughput while optimizing expensive GPU compute resources.