These updates provide engineers with more accurate, granular data on GitHub's reliability. By distinguishing between latency and outages and isolating AI model provider issues, teams can make better-informed decisions during incidents and more effectively evaluate platform performance.
GitHub is where millions of developers do their most important work, and that comes with a responsibility we take seriously. Earlier this year, we shared an update on GitHub’s recent availability issues and the work we’re doing to address them. Alongside those reliability investments, we have prioritized improving how we communicate during and after incidents, increasing the specificity of the data we provide and giving better insight into the platform’s health overall.
Guided by transparency, accuracy, and timeliness, we’re rolling out three changes to how we communicate service health—outlined below.
We’re adding a new incident severity level: Degraded Performance. This sits alongside our existing Partial Outage and Major Outage states, creating a three-tier system that more accurately reflects the spectrum of issues that can affect GitHub services.
| State | What It Means |
|---|---|
| Degraded Performance | The service is operational but impaired. You may experience elevated latency, reduced functionality, or intermittent errors affecting a small percentage of requests. |
| Partial Outage | A significant portion of the service is unavailable or severely impacted for a meaningful number of users. |
| Major Outage | The service is broadly unavailable, affecting most or all users. |
Previously, even with minimal service disruption, all incidents were classified at least as a partial outage. This did not accurately reflect customer impact and led users to believe a service was unavailable even if it was still functional.
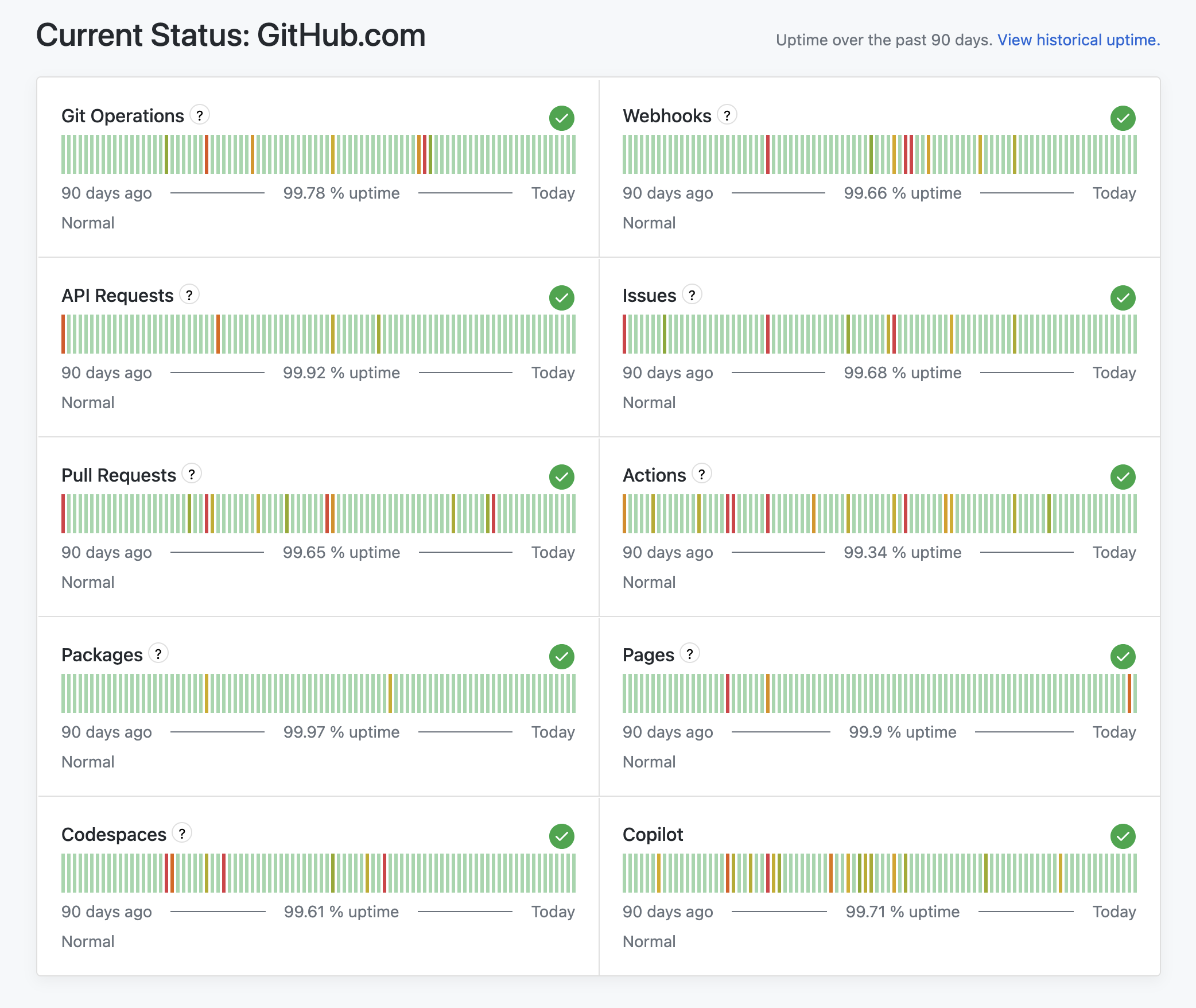
We are now publishing per-service uptime percentages over the last 90 days directly on our status page, so you can quickly understand each service’s recent reliability track record.
These uptime percentages are calculated based on the number of incidents, their severity, and their duration for each individual service. These calculations are based on industry standard status page calculations.
Each severity level carries a specific downtime weight:
| Severity | Downtime weight |
|---|---|
| Major Outage | 100% — the full duration counts as downtime |
| Partial Outage | 30% — reflects significant but not total service loss |
| Degraded Performance | 0% — does not count as downtime; the service remains functional |
For example, if a service experienced a 1-hour Partial Outage over a 90-day period, that would count as 18 minutes of effective downtime in the uptime calculation—not the full hour. A Degraded Performance incident, by contrast, would not affect the uptime percentage at all.
We’ve added a new component representing Copilot AI model providers.
Previously, when a model provider experienced an outage, we declared an incident against the Copilot service, even when the impact was limited to a single model. That didn’t always reflect your experience, because many Copilot features, such as GitHub Copilot Chat and GitHub Copilot cloud agent (formerly coding agent) support multiple models. On those features, if one model is unavailable, you can choose an alternative model or use auto model selection to have Copilot pick the best available option for you.
Going forward, incidents related to model availability will be reported under the new “Copilot AI Model Providers” component instead of the broader “Copilot” component. We’ll continue to share details, such as which models are affected, through public incident updates.
We recognize that clear communication and transparency matter most when things go wrong. The Degraded Performance state, per-service uptime percentages, and dedicated Copilot AI Model Providers component are designed to give you the context and details you need to make confident decisions about your operations.
We know GitHub is critical infrastructure for your teams, and we are committed to ensuring our platform is available when and where you need it; and communicating effectively and transparently when it is not.
The post Bringing more transparency to GitHub’s status page appeared first on The GitHub Blog.
Continue reading on the original blog to support the author
Read full articleClear repository ownership is critical for security remediation and incident response. By automating ownership validation via custom properties, GitHub eliminated technical debt, archived thousands of stale repos, and ensured every active project has a direct point of contact.
GitHub Actions enables engineers to automate development workflows directly within their repositories. Understanding these fundamentals allows teams to implement CI/CD, improve code quality through automated testing, and reduce manual overhead for project management tasks.
GitHub Agentic Workflows lower the barrier for complex repository automation by replacing rigid YAML with intent-driven Markdown. This enables 'Continuous AI,' allowing teams to automate cognitive tasks like issue triage and CI debugging while maintaining strict security and audit guardrails.
These projects represent the backbone of modern developer productivity. By automating releases, simplifying backend infrastructure, and building independent engines, they empower engineers to bypass boilerplate and focus on high-impact innovation within the open source ecosystem.